 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRUtopia: Dream General Robots in a City at Scale
Jul 15, 2024Recent works have been exploring the scaling laws in the field of Embodied AI. Given the prohibitive costs of collecting real-world data, we believe the Simulation-to-Real (Sim2Real) paradigm is a crucial step for scaling the learning of embodied models. This paper introduces project GRUtopia, the first simulated interactive 3D society designed for various robots. It features several advancements: (a) The scene dataset, GRScenes, includes 100k interactive, finely annotated scenes, which can be freely combined into city-scale environments. In contrast to previous works mainly focusing on home, GRScenes covers 89 diverse scene categories, bridging the gap of service-oriented environments where general robots would be initially deployed. (b) GRResidents, a Large Language Model (LLM) driven Non-Player Character (NPC) system that is responsible for social interaction, task generation, and task assignment, thus simulating social scenarios for embodied AI applications. (c) The benchmark, GRBench, supports various robots but focuses on legged robots as primary agents and poses moderately challenging tasks involving Object Loco-Navigation, Social Loco-Navigation, and Loco-Manipulation. We hope that this work can alleviate the scarcity of high-quality data in this field and provide a more comprehensive assessment of Embodied AI research. The project is available at https://github.com/OpenRobotLab/GRUtopia.
Graph-Boosted Attentive Network for Semantic Body Parsing
Jul 08, 2024Human body parsing remains a challenging problem in natural scenes due to multi-instance and inter-part semantic confusions as well as occlusions. This paper proposes a novel approach to decomposing multiple human bodies into semantic part regions in unconstrained environments. Specifically we propose a convolutional neural network (CNN) architecture which comprises of novel semantic and contour attention mechanisms across feature hierarchy to resolve the semantic ambiguities and boundary localization issues related to semantic body parsing. We further propose to encode estimated pose as higher-level contextual information which is combined with local semantic cues in a novel graphical model in a principled manner. In this proposed model, the lower-level semantic cues can be recursively updated by propagating higher-level contextual information from estimated pose and vice versa across the graph, so as to alleviate erroneous pose information and pixel level predictions. We further propose an optimization technique to efficiently derive the solutions. Our proposed method achieves the state-of-art results on the challenging Pascal Person-Part dataset.
Non-parametric Contextual Relationship Learning for Semantic Video Object Segmentation
Jul 08, 2024We propose a novel approach for modeling semantic contextual relationships in videos. This graph-based model enables the learning and propagation of higher-level spatial-temporal contexts to facilitate the semantic labeling of local regions. We introduce an exemplar-based nonparametric view of contextual cues, where the inherent relationships implied by object hypotheses are encoded on a similarity graph of regions. Contextual relationships learning and propagation are performed to estimate the pairwise contexts between all pairs of unlabeled local regions. Our algorithm integrates the learned contexts into a Conditional Random Field (CRF) in the form of pairwise potentials and infers the per-region semantic labels. We evaluate our approach on the challenging YouTube-Objects dataset which shows that the proposed contextual relationship model outperforms the state-of-the-art methods.
Spectral Graph Reasoning Network for Hyperspectral Image Classification
Jul 02, 2024Convolutional neural networks (CNNs) have achieved remarkable performance in hyperspectral image (HSI) classification over the last few years. Despite the progress that has been made, rich and informative spectral information of HSI has been largely underutilized by existing methods which employ convolutional kernels with limited size of receptive field in the spectral domain. To address this issue, we propose a spectral graph reasoning network (SGR) learning framework comprising two crucial modules: 1) a spectral decoupling module which unpacks and casts multiple spectral embeddings into a unified graph whose node corresponds to an individual spectral feature channel in the embedding space; the graph performs interpretable reasoning to aggregate and align spectral information to guide learning spectral-specific graph embeddings at multiple contextual levels 2) a spectral ensembling module explores the interactions and interdependencies across graph embedding hierarchy via a novel recurrent graph propagation mechanism. Experiments on two HSI datasets demonstrate that the proposed architecture can significantly improve the classification accuracy compared with the existing methods with a sizable margin.
Swapped goal-conditioned offline reinforcement learning
Feb 17, 2023Offline goal-conditioned reinforcement learning (GCRL) can be challenging due to overfitting to the given dataset. To generalize agents' skills outside the given dataset, we propose a goal-swapping procedure that generates additional trajectories. To alleviate the problem of noise and extrapolation errors, we present a general offline reinforcement learning method called deterministic Q-advantage policy gradient (DQAPG). In the experiments, DQAPG outperforms state-of-the-art goal-conditioned offline RL methods in a wide range of benchmark tasks, and goal-swapping further improves the test results. It is noteworthy, that the proposed method obtains good performance on the challenging dexterous in-hand manipulation tasks for which the prior methods failed.
Simultaneously Learning Architectures and Features of Deep Neural Networks
Jun 11, 2019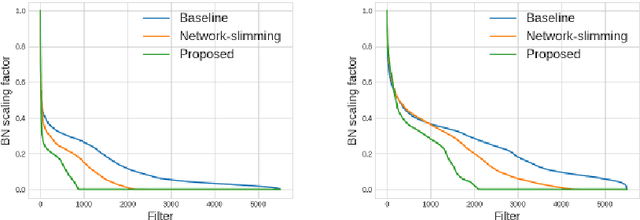
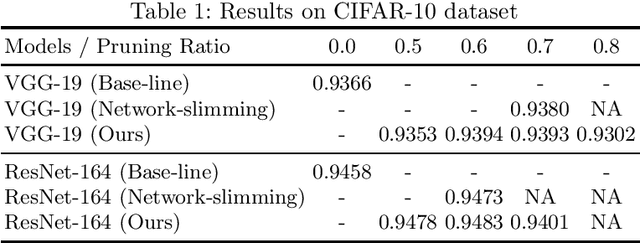
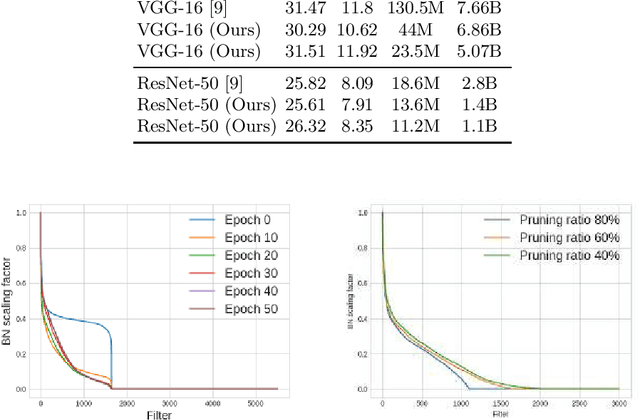
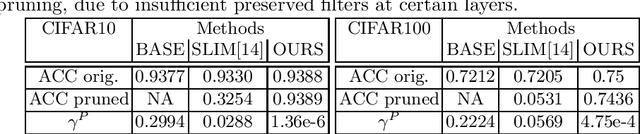
This paper presents a novel method which simultaneously learns the number of filters and network features repeatedly over multiple epochs. We propose a novel pruning loss to explicitly enforces the optimizer to focus on promising candidate filters while suppressing contributions of less relevant ones. In the meanwhile, we further propose to enforce the diversities between filters and this diversity-based regularization term improves the trade-off between model sizes and accuracies. It turns out the interplay between architecture and feature optimizations improves the final compressed models, and the proposed method is compared favorably to existing methods, in terms of both models sizes and accuracies for a wide range of applications including image classification, image compression and audio classification.
Translate-to-Recognize Networks for RGB-D Scene Recognition
Apr 28, 2019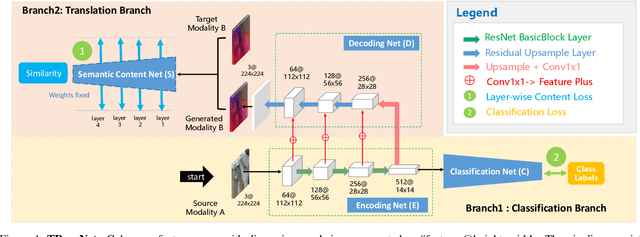

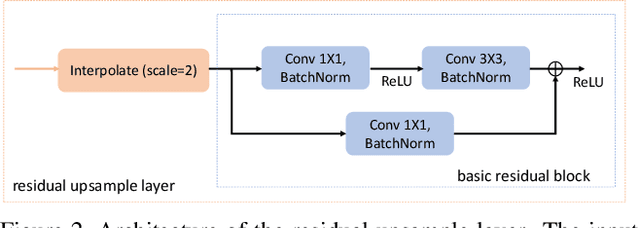
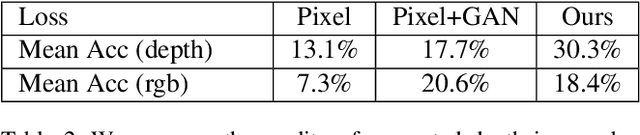
Cross-modal transfer is helpful to enhance modality-specific discriminative power for scene recognition. To this end, this paper presents a unified framework to integrate the tasks of cross-modal translation and modality-specific recognition, termed as Translate-to-Recognize Network (TRecgNet). Specifically, both translation and recognition tasks share the same encoder network, which allows to explicitly regularize the training of recognition task with the help of translation, and thus improve its final generalization ability. For translation task, we place a decoder module on top of the encoder network and it is optimized with a new layer-wise semantic loss, while for recognition task, we use a linear classifier based on the feature embedding from encoder and its training is guided by the standard cross-entropy loss. In addition, our TRecgNet allows to exploit large numbers of unlabeled RGB-D data to train the translation task and thus improve the representation power of encoder network. Empirically, we verify that this new semi-supervised setting is able to further enhance the performance of recognition network. We perform experiments on two RGB-D scene recognition benchmarks: NYU Depth v2 and SUN RGB-D, demonstrating that TRecgNet achieves superior performance to the existing state-of-the-art methods, especially for recognition solely based on a single modality.
Semi-Supervised Domain Adaptation for Weakly Labeled Semantic Video Object Segmentation
Jun 07, 2016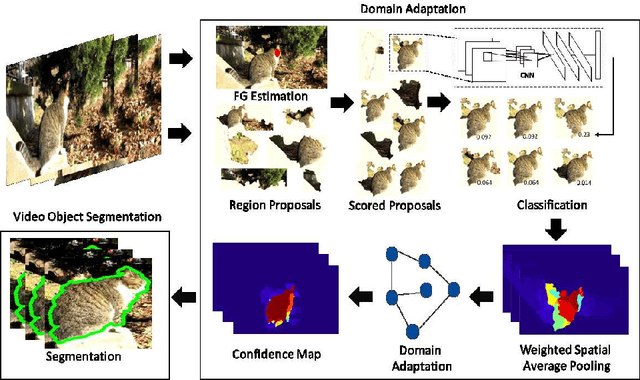
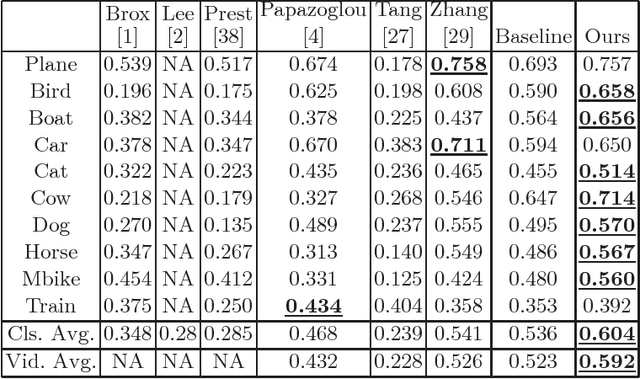


Deep convolutional neural networks (CNNs) have been immensely successful in many high-level computer vision tasks given large labeled datasets. However, for video semantic object segmentation, a domain where labels are scarce, effectively exploiting the representation power of CNN with limited training data remains a challenge. Simply borrowing the existing pretrained CNN image recognition model for video segmentation task can severely hurt performance. We propose a semi-supervised approach to adapting CNN image recognition model trained from labeled image data to the target domain exploiting both semantic evidence learned from CNN, and the intrinsic structures of video data. By explicitly modeling and compensating for the domain shift from the source domain to the target domain, this proposed approach underpins a robust semantic object segmentation method against the changes in appearance, shape and occlusion in natural videos. We present extensive experiments on challenging datasets that demonstrate the superior performance of our approach compared with the state-of-the-art methods.