 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolving Symbolic 3D Visual Grounder with Weakly Supervised Reflection
Feb 03, 20253D visual grounding (3DVG) is challenging because of the requirement of understanding on visual information, language and spatial relationships. While supervised approaches have achieved superior performance, they are constrained by the scarcity and high cost of 3D vision-language datasets. On the other hand, LLM/VLM based agents are proposed for 3DVG, eliminating the need for training data. However, these methods incur prohibitive time and token costs during inference. To address the challenges, we introduce a novel training-free symbolic framework for 3D visual grounding, namely Evolvable Symbolic Visual Grounder, that offers significantly reduced inference costs compared to previous agent-based methods while maintaining comparable performance. EaSe uses LLM generated codes to compute on spatial relationships. EaSe also implements an automatic pipeline to evaluate and optimize the quality of these codes and integrate VLMs to assist in the grounding process. Experimental results demonstrate that EaSe achieves 52.9% accuracy on Nr3D dataset and 49.2% Acc@0.25 on ScanRefer, which is top-tier among training-free methods. Moreover, it substantially reduces the inference time and cost, offering a balanced trade-off between performance and efficiency. Codes are available at https://github.com/OpenRobotLab/EaSe.
GRUtopia: Dream General Robots in a City at Scale
Jul 15, 2024Recent works have been exploring the scaling laws in the field of Embodied AI. Given the prohibitive costs of collecting real-world data, we believe the Simulation-to-Real (Sim2Real) paradigm is a crucial step for scaling the learning of embodied models. This paper introduces project GRUtopia, the first simulated interactive 3D society designed for various robots. It features several advancements: (a) The scene dataset, GRScenes, includes 100k interactive, finely annotated scenes, which can be freely combined into city-scale environments. In contrast to previous works mainly focusing on home, GRScenes covers 89 diverse scene categories, bridging the gap of service-oriented environments where general robots would be initially deployed. (b) GRResidents, a Large Language Model (LLM) driven Non-Player Character (NPC) system that is responsible for social interaction, task generation, and task assignment, thus simulating social scenarios for embodied AI applications. (c) The benchmark, GRBench, supports various robots but focuses on legged robots as primary agents and poses moderately challenging tasks involving Object Loco-Navigation, Social Loco-Navigation, and Loco-Manipulation. We hope that this work can alleviate the scarcity of high-quality data in this field and provide a more comprehensive assessment of Embodied AI research. The project is available at https://github.com/OpenRobotLab/GRUtopia.
Lemur: Harmonizing Natural Language and Code for Language Agents
Oct 10, 2023We introduce Lemur and Lemur-Chat, openly accessible language models optimized for both natural language and coding capabilities to serve as the backbone of versatile language agents. The evolution from language chat models to functional language agents demands that models not only master human interaction, reasoning, and planning but also ensure grounding in the relevant environments. This calls for a harmonious blend of language and coding capabilities in the models. Lemur and Lemur-Chat are proposed to address this necessity, demonstrating balanced proficiencies in both domains, unlike existing open-source models that tend to specialize in either. Through meticulous pre-training using a code-intensive corpus and instruction fine-tuning on text and code data, our models achieve state-of-the-art averaged performance across diverse text and coding benchmarks among open-source models. Comprehensive experiments demonstrate Lemur's superiority over existing open-source models and its proficiency across various agent tasks involving human communication, tool usage, and interaction under fully- and partially- observable environments. The harmonization between natural and programming languages enables Lemur-Chat to significantly narrow the gap with proprietary models on agent abilities, providing key insights into developing advanced open-source agents adept at reasoning, planning, and operating seamlessly across environments. https://github.com/OpenLemur/Lemur
RobuT: A Systematic Study of Table QA Robustness Against Human-Annotated Adversarial Perturbations
Jun 25, 2023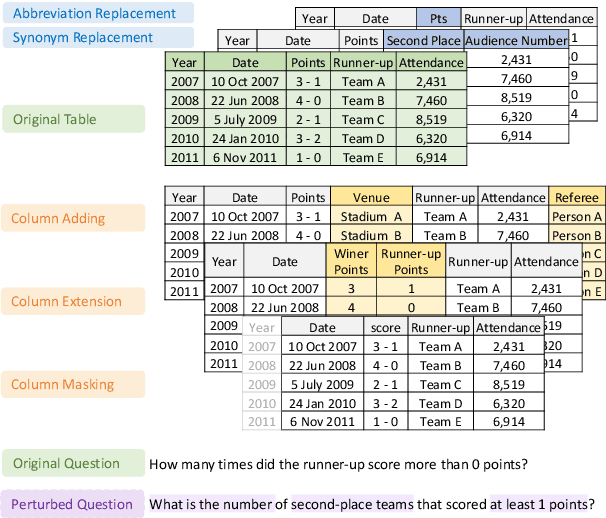

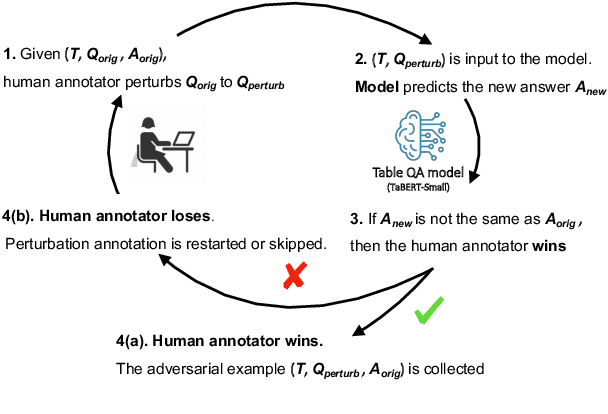
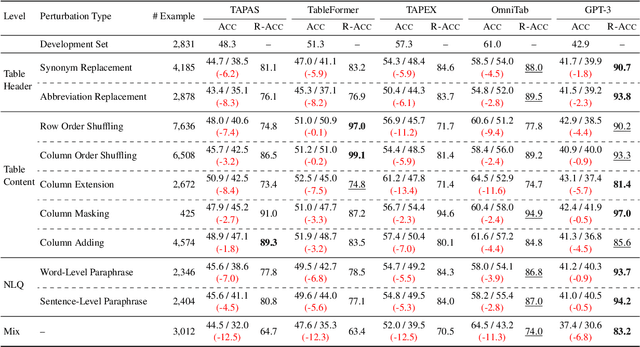
Despite significant progress having been made in question answering on tabular data (Table QA), it's unclear whether, and to what extent existing Table QA models are robust to task-specific perturbations, e.g., replacing key question entities or shuffling table columns. To systematically study the robustness of Table QA models, we propose a benchmark called RobuT, which builds upon existing Table QA datasets (WTQ, WikiSQL-Weak, and SQA) and includes human-annotated adversarial perturbations in terms of table header, table content, and question. Our results indicate that both state-of-the-art Table QA models and large language models (e.g., GPT-3) with few-shot learning falter in these adversarial sets. We propose to address this problem by using large language models to generate adversarial examples to enhance training, which significantly improves the robustness of Table QA models. Our data and code is publicly available at https://github.com/yilunzhao/RobuT.
QTSumm: A New Benchmark for Query-Focused Table Summarization
May 23, 2023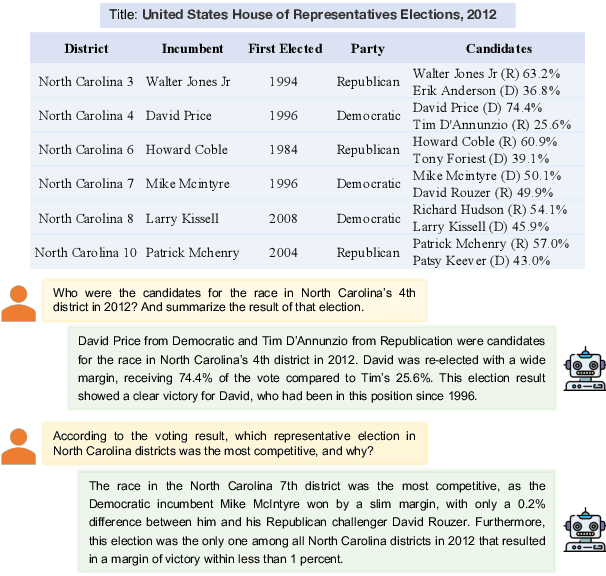
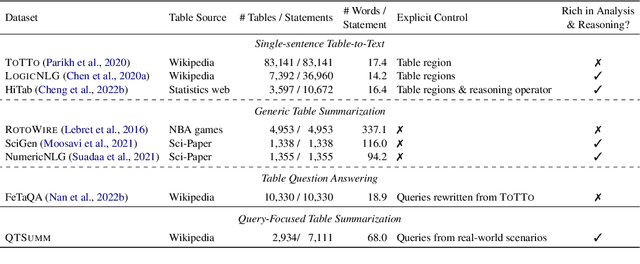

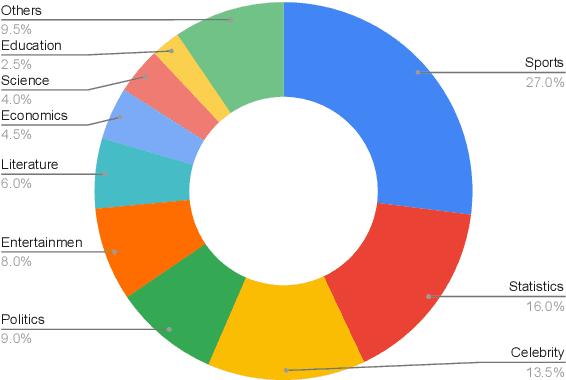
People primarily consult tables to conduct data analysis or answer specific questions. Text generation systems that can provide accurate table summaries tailored to users' information needs can facilitate more efficient access to relevant data insights. However, existing table-to-text generation studies primarily focus on converting tabular data into coherent statements, rather than addressing information-seeking purposes. In this paper, we define a new query-focused table summarization task, where text generation models have to perform human-like reasoning and analysis over the given table to generate a tailored summary, and we introduce a new benchmark named QTSumm for this task. QTSumm consists of 5,625 human-annotated query-summary pairs over 2,437 tables on diverse topics. Moreover, we investigate state-of-the-art models (i.e., text generation, table-to-text generation, and large language models) on the QTSumm dataset. Experimental results and manual analysis reveal that our benchmark presents significant challenges in table-to-text generation for future research.