 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Experience Replay for Self-Improvement of Language Agents
Jun 07, 2025
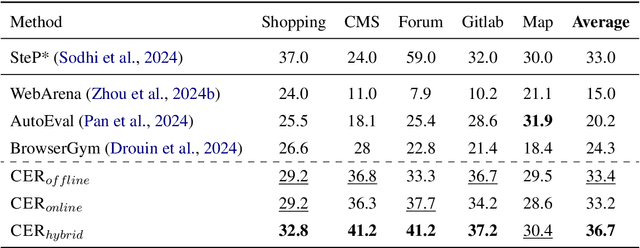


Large language model (LLM) agents have been applied to sequential decision-making tasks such as web navigation, but without any environment-specific experiences, they often fail in these complex tasks. Moreover, current LLM agents are not designed to continually learn from past experiences during inference time, which could be crucial for them to gain these environment-specific experiences. To address this, we propose Contextual Experience Replay (CER), a training-free framework to enable efficient self-improvement for language agents in their context window. Specifically, CER accumulates and synthesizes past experiences into a dynamic memory buffer. These experiences encompass environment dynamics and common decision-making patterns, allowing the agents to retrieve and augment themselves with relevant knowledge in new tasks, enhancing their adaptability in complex environments. We evaluate CER on the challenging WebArena and VisualWebArena benchmarks. On VisualWebArena, CER achieves a competitive performance of 31.9%. On WebArena, CER also gets a competitive average success rate of 36.7%, relatively improving the success rate of the GPT-4o agent baseline by 51.0%. We also conduct a comprehensive analysis on it to prove its efficiency, validity and understand it better.
CharXiv: Charting Gaps in Realistic Chart Understanding in Multimodal LLMs
Jun 26, 2024



Chart understanding plays a pivotal role when applying Multimodal Large Language Models (MLLMs) to real-world tasks such as analyzing scientific papers or financial reports. However, existing datasets often focus on oversimplified and homogeneous charts with template-based questions, leading to an over-optimistic measure of progress. We demonstrate that although open-source models can appear to outperform strong proprietary models on these benchmarks, a simple stress test with slightly different charts or questions can deteriorate performance by up to 34.5%. In this work, we propose CharXiv, a comprehensive evaluation suite involving 2,323 natural, challenging, and diverse charts from arXiv papers. CharXiv includes two types of questions: 1) descriptive questions about examining basic chart elements and 2) reasoning questions that require synthesizing information across complex visual elements in the chart. To ensure quality, all charts and questions are handpicked, curated, and verified by human experts. Our results reveal a substantial, previously underestimated gap between the reasoning skills of the strongest proprietary model (i.e., GPT-4o), which achieves 47.1% accuracy, and the strongest open-source model (i.e., InternVL Chat V1.5), which achieves 29.2%. All models lag far behind human performance of 80.5%, underscoring weaknesses in the chart understanding capabilities of existing MLLMs. We hope CharXiv facilitates future research on MLLM chart understanding by providing a more realistic and faithful measure of progress. Project page and leaderboard: https://charxiv.github.io/
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
Apr 11, 2024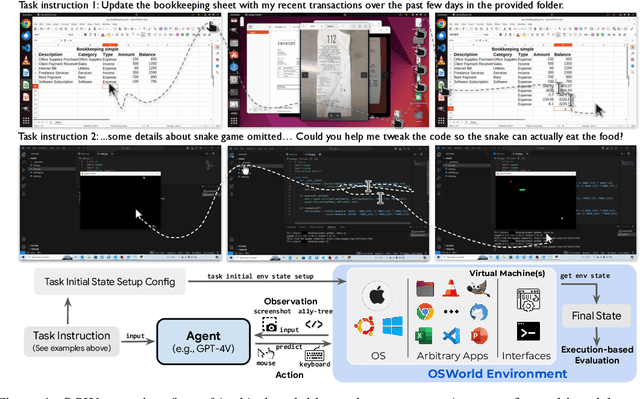

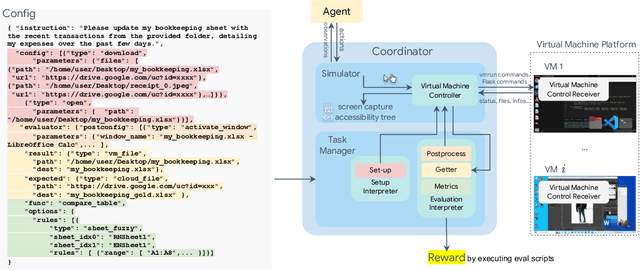

Autonomous agents that accomplish complex computer tasks with minimal human interventions have the potential to transform human-computer interaction, significantly enhancing accessibility and productivity. However, existing benchmarks either lack an interactive environment or are limited to environments specific to certain applications or domains, failing to reflect the diverse and complex nature of real-world computer use, thereby limiting the scope of tasks and agent scalability. To address this issue, we introduce OSWorld, the first-of-its-kind scalable, real computer environment for multimodal agents, supporting task setup, execution-based evaluation, and interactive learning across various operating systems such as Ubuntu, Windows, and macOS. OSWorld can serve as a unified, integrated computer environment for assessing open-ended computer tasks that involve arbitrary applications. Building upon OSWorld, we create a benchmark of 369 computer tasks involving real web and desktop apps in open domains, OS file I/O, and workflows spanning multiple applications. Each task example is derived from real-world computer use cases and includes a detailed initial state setup configuration and a custom execution-based evaluation script for reliable, reproducible evaluation. Extensive evaluation of state-of-the-art LLM/VLM-based agents on OSWorld reveals significant deficiencies in their ability to serve as computer assistants. While humans can accomplish over 72.36% of the tasks, the best model achieves only 12.24% success, primarily struggling with GUI grounding and operational knowledge. Comprehensive analysis using OSWorld provides valuable insights for developing multimodal generalist agents that were not possible with previous benchmarks. Our code, environment, baseline models, and data are publicly available at https://os-world.github.io.
OpenAgents: An Open Platform for Language Agents in the Wild
Oct 16, 2023



Language agents show potential in being capable of utilizing natural language for varied and intricate tasks in diverse environments, particularly when built upon large language models (LLMs). Current language agent frameworks aim to facilitate the construction of proof-of-concept language agents while neglecting the non-expert user access to agents and paying little attention to application-level designs. We present OpenAgents, an open platform for using and hosting language agents in the wild of everyday life. OpenAgents includes three agents: (1) Data Agent for data analysis with Python/SQL and data tools; (2) Plugins Agent with 200+ daily API tools; (3) Web Agent for autonomous web browsing. OpenAgents enables general users to interact with agent functionalities through a web user interface optimized for swift responses and common failures while offering developers and researchers a seamless deployment experience on local setups, providing a foundation for crafting innovative language agents and facilitating real-world evaluations. We elucidate the challenges and opportunities, aspiring to set a foundation for future research and development of real-world language agents.
Lemur: Harmonizing Natural Language and Code for Language Agents
Oct 10, 2023We introduce Lemur and Lemur-Chat, openly accessible language models optimized for both natural language and coding capabilities to serve as the backbone of versatile language agents. The evolution from language chat models to functional language agents demands that models not only master human interaction, reasoning, and planning but also ensure grounding in the relevant environments. This calls for a harmonious blend of language and coding capabilities in the models. Lemur and Lemur-Chat are proposed to address this necessity, demonstrating balanced proficiencies in both domains, unlike existing open-source models that tend to specialize in either. Through meticulous pre-training using a code-intensive corpus and instruction fine-tuning on text and code data, our models achieve state-of-the-art averaged performance across diverse text and coding benchmarks among open-source models. Comprehensive experiments demonstrate Lemur's superiority over existing open-source models and its proficiency across various agent tasks involving human communication, tool usage, and interaction under fully- and partially- observable environments. The harmonization between natural and programming languages enables Lemur-Chat to significantly narrow the gap with proprietary models on agent abilities, providing key insights into developing advanced open-source agents adept at reasoning, planning, and operating seamlessly across environments. https://github.com/OpenLemur/Lemur
Text2Reward: Automated Dense Reward Function Generation for Reinforcement Learning
Sep 21, 2023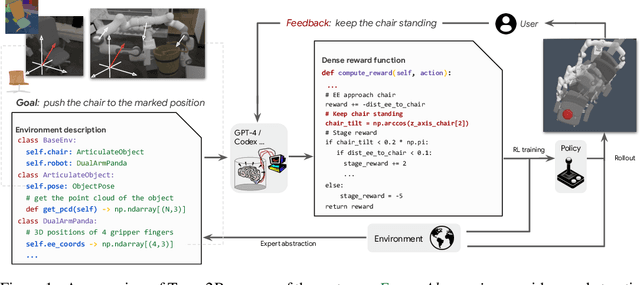
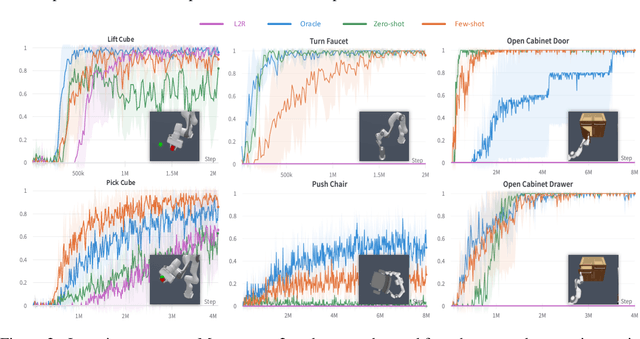
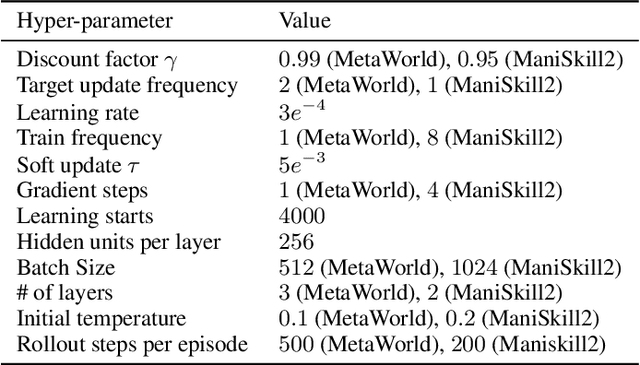
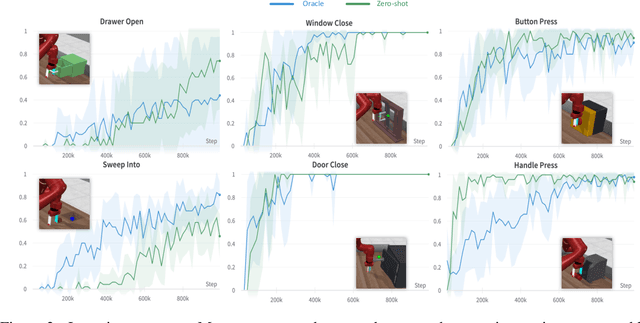
Designing reward functions is a longstanding challenge in reinforcement learning (RL); it requires specialized knowledge or domain data, leading to high costs for development. To address this, we introduce Text2Reward, a data-free framework that automates the generation of dense reward functions based on large language models (LLMs). Given a goal described in natural language, Text2Reward generates dense reward functions as an executable program grounded in a compact representation of the environment. Unlike inverse RL and recent work that uses LLMs to write sparse reward codes, Text2Reward produces interpretable, free-form dense reward codes that cover a wide range of tasks, utilize existing packages, and allow iterative refinement with human feedback. We evaluate Text2Reward on two robotic manipulation benchmarks (ManiSkill2, MetaWorld) and two locomotion environments of MuJoCo. On 13 of the 17 manipulation tasks, policies trained with generated reward codes achieve similar or better task success rates and convergence speed than expert-written reward codes. For locomotion tasks, our method learns six novel locomotion behaviors with a success rate exceeding 94%. Furthermore, we show that the policies trained in the simulator with our method can be deployed in the real world. Finally, Text2Reward further improves the policies by refining their reward functions with human feedback. Video results are available at https://text-to-reward.github.io
$\mathcal{Y}$-Tuning: An Efficient Tuning Paradigm for Large-Scale Pre-Trained Models via Label Representation Learning
Feb 20, 2022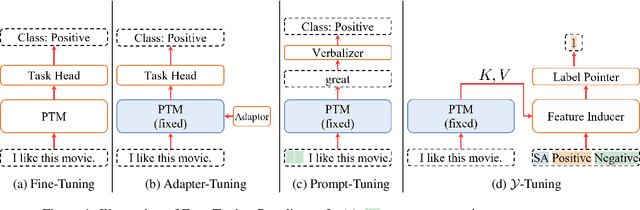



With the success of large-scale pre-trained models (PTMs), how efficiently adapting PTMs to downstream tasks has attracted tremendous attention, especially for PTMs with billions of parameters. Although some parameter-efficient tuning paradigms have been proposed to address this problem, they still require large resources to compute the gradients in the training phase. In this paper, we propose $\mathcal{Y}$-Tuning, an efficient yet effective paradigm to adapt frozen large-scale PTMs to specific downstream tasks. $\mathcal{Y}$-tuning learns dense representations for labels $\mathcal{Y}$ defined in a given task and aligns them to fixed feature representation. Without tuning the features of input text and model parameters, $\mathcal{Y}$-tuning is both parameter-efficient and training-efficient. For $\text{DeBERTa}_\text{XXL}$ with 1.6 billion parameters, $\mathcal{Y}$-tuning achieves performance more than $96\%$ of full fine-tuning on GLUE Benchmark with only $2\%$ tunable parameters and much fewer training costs.
CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation
Sep 14, 2021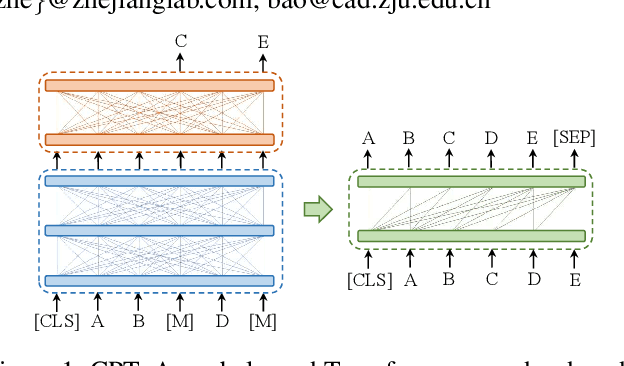
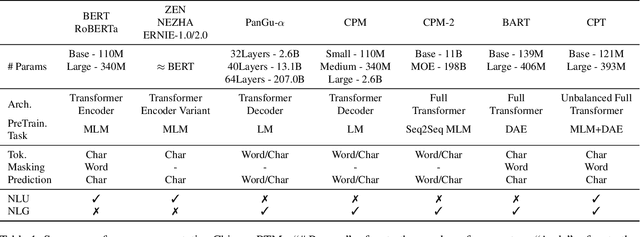
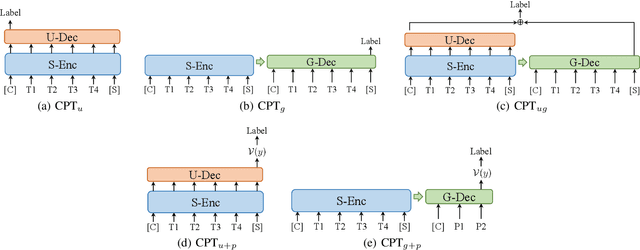
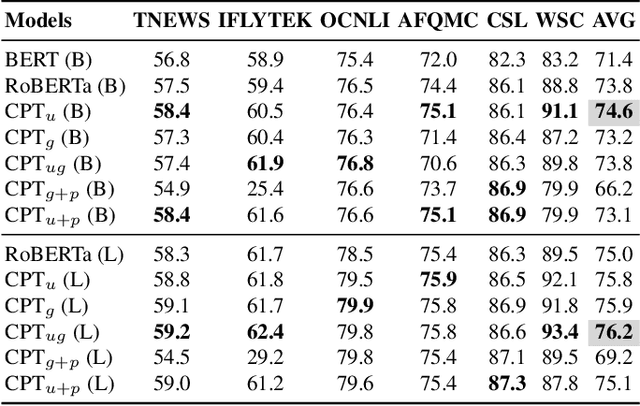
In this paper, we take the advantage of previous pre-trained models (PTMs) and propose a novel Chinese Pre-trained Unbalanced Transformer (CPT). Different from previous Chinese PTMs, CPT is designed for both natural language understanding (NLU) and natural language generation (NLG) tasks. CPT consists of three parts: a shared encoder, an understanding decoder, and a generation decoder. Two specific decoders with a shared encoder are pre-trained with masked language modeling (MLM) and denoising auto-encoding (DAE) tasks, respectively. With the partially shared architecture and multi-task pre-training, CPT can (1) learn specific knowledge of both NLU or NLG tasks with two decoders and (2) be fine-tuned flexibly that fully exploits the potential of the model. Moreover, the unbalanced Transformer saves the computational and storage cost, which makes CPT competitive and greatly accelerates the inference of text generation. Experimental results on a wide range of Chinese NLU and NLG tasks show the effectiveness of CPT.
Learning to Teach with Student Feedback
Sep 10, 2021
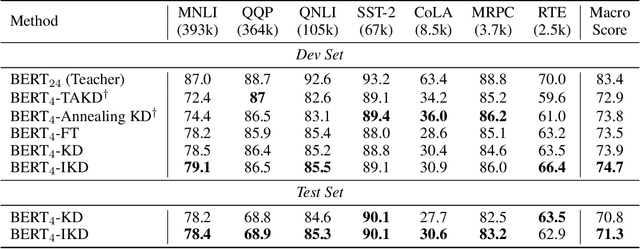


Knowledge distillation (KD) has gained much attention due to its effectiveness in compressing large-scale pre-trained models. In typical KD methods, the small student model is trained to match the soft targets generated by the big teacher model. However, the interaction between student and teacher is one-way. The teacher is usually fixed once trained, resulting in static soft targets to be distilled. This one-way interaction leads to the teacher's inability to perceive the characteristics of the student and its training progress. To address this issue, we propose Interactive Knowledge Distillation (IKD), which also allows the teacher to learn to teach from the feedback of the student. In particular, IKD trains the teacher model to generate specific soft target at each training step for a certain student. Joint optimization for both teacher and student is achieved by two iterative steps: a course step to optimize student with the soft target of teacher, and an exam step to optimize teacher with the feedback of student. IKD is a general framework that is orthogonal to most existing knowledge distillation methods. Experimental results show that IKD outperforms traditional KD methods on various NLP tasks.
LabelEnc: A New Intermediate Supervision Method for Object Detection
Jul 07, 2020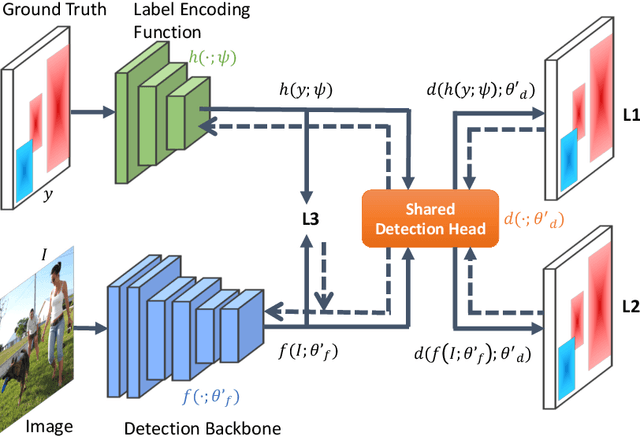
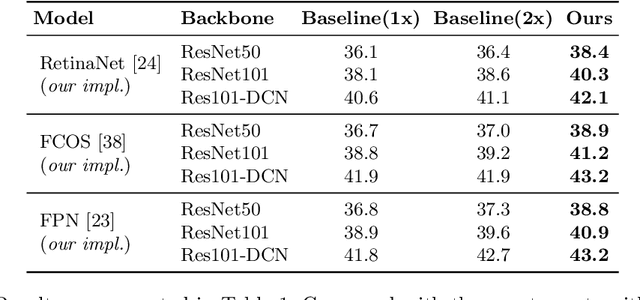
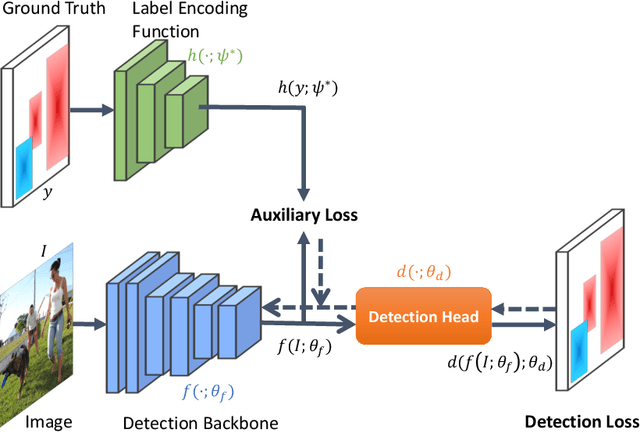

In this paper we propose a new intermediate supervision method, named LabelEnc, to boost the training of object detection systems. The key idea is to introduce a novel label encoding function, mapping the ground-truth labels into latent embedding, acting as an auxiliary intermediate supervision to the detection backbone during training. Our approach mainly involves a two-step training procedure. First, we optimize the label encoding function via an AutoEncoder defined in the label space, approximating the "desired" intermediate representations for the target object detector. Second, taking advantage of the learned label encoding function, we introduce a new auxiliary loss attached to the detection backbones, thus benefiting the performance of the derived detector. Experiments show our method improves a variety of detection systems by around 2% on COCO dataset, no matter one-stage or two-stage frameworks. Moreover, the auxiliary structures only exist during training, i.e. it is completely cost-free in inference time.