 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIA Forecaster: Technical Report
Nov 10, 2025This technical report describes the AIA Forecaster, a Large Language Model (LLM)-based system for judgmental forecasting using unstructured data. The AIA Forecaster approach combines three core elements: agentic search over high-quality news sources, a supervisor agent that reconciles disparate forecasts for the same event, and a set of statistical calibration techniques to counter behavioral biases in large language models. On the ForecastBench benchmark (Karger et al., 2024), the AIA Forecaster achieves performance equal to human superforecasters, surpassing prior LLM baselines. In addition to reporting on ForecastBench, we also introduce a more challenging forecasting benchmark sourced from liquid prediction markets. While the AIA Forecaster underperforms market consensus on this benchmark, an ensemble combining AIA Forecaster with market consensus outperforms consensus alone, demonstrating that our forecaster provides additive information. Our work establishes a new state of the art in AI forecasting and provides practical, transferable recommendations for future research. To the best of our knowledge, this is the first work that verifiably achieves expert-level forecasting at scale.
TxAgent: An AI Agent for Therapeutic Reasoning Across a Universe of Tools
Mar 14, 2025Precision therapeutics require multimodal adaptive models that generate personalized treatment recommendations. We introduce TxAgent, an AI agent that leverages multi-step reasoning and real-time biomedical knowledge retrieval across a toolbox of 211 tools to analyze drug interactions, contraindications, and patient-specific treatment strategies. TxAgent evaluates how drugs interact at molecular, pharmacokinetic, and clinical levels, identifies contraindications based on patient comorbidities and concurrent medications, and tailors treatment strategies to individual patient characteristics. It retrieves and synthesizes evidence from multiple biomedical sources, assesses interactions between drugs and patient conditions, and refines treatment recommendations through iterative reasoning. It selects tools based on task objectives and executes structured function calls to solve therapeutic tasks that require clinical reasoning and cross-source validation. The ToolUniverse consolidates 211 tools from trusted sources, including all US FDA-approved drugs since 1939 and validated clinical insights from Open Targets. TxAgent outperforms leading LLMs, tool-use models, and reasoning agents across five new benchmarks: DrugPC, BrandPC, GenericPC, TreatmentPC, and DescriptionPC, covering 3,168 drug reasoning tasks and 456 personalized treatment scenarios. It achieves 92.1% accuracy in open-ended drug reasoning tasks, surpassing GPT-4o and outperforming DeepSeek-R1 (671B) in structured multi-step reasoning. TxAgent generalizes across drug name variants and descriptions. By integrating multi-step inference, real-time knowledge grounding, and tool-assisted decision-making, TxAgent ensures that treatment recommendations align with established clinical guidelines and real-world evidence, reducing the risk of adverse events and improving therapeutic decision-making.
LLMs are Superior Feedback Providers: Bootstrapping Reasoning for Lie Detection with Self-Generated Feedback
Aug 25, 2024



Large Language Models (LLMs) excel at generating human-like dialogues and comprehending text. However, understanding the subtleties of complex exchanges in language remains a challenge. We propose a bootstrapping framework that leverages self-generated feedback to enhance LLM reasoning capabilities for lie detection. The framework consists of three stages: suggestion, feedback collection, and modification. In the suggestion stage, a cost-effective language model generates initial predictions based on game state and dialogue. The feedback-collection stage involves a language model providing feedback on these predictions. In the modification stage, a more advanced language model refines the initial predictions using the auto-generated feedback. We investigate the application of the proposed framework for detecting betrayal and deception in Diplomacy games, and compare it with feedback from professional human players. The LLM-generated feedback exhibits superior quality and significantly enhances the performance of the model. Our approach achieves a 39% improvement over the zero-shot baseline in lying-F1 without the need for any training data, rivaling state-of-the-art supervised learning results.
CharXiv: Charting Gaps in Realistic Chart Understanding in Multimodal LLMs
Jun 26, 2024



Chart understanding plays a pivotal role when applying Multimodal Large Language Models (MLLMs) to real-world tasks such as analyzing scientific papers or financial reports. However, existing datasets often focus on oversimplified and homogeneous charts with template-based questions, leading to an over-optimistic measure of progress. We demonstrate that although open-source models can appear to outperform strong proprietary models on these benchmarks, a simple stress test with slightly different charts or questions can deteriorate performance by up to 34.5%. In this work, we propose CharXiv, a comprehensive evaluation suite involving 2,323 natural, challenging, and diverse charts from arXiv papers. CharXiv includes two types of questions: 1) descriptive questions about examining basic chart elements and 2) reasoning questions that require synthesizing information across complex visual elements in the chart. To ensure quality, all charts and questions are handpicked, curated, and verified by human experts. Our results reveal a substantial, previously underestimated gap between the reasoning skills of the strongest proprietary model (i.e., GPT-4o), which achieves 47.1% accuracy, and the strongest open-source model (i.e., InternVL Chat V1.5), which achieves 29.2%. All models lag far behind human performance of 80.5%, underscoring weaknesses in the chart understanding capabilities of existing MLLMs. We hope CharXiv facilitates future research on MLLM chart understanding by providing a more realistic and faithful measure of progress. Project page and leaderboard: https://charxiv.github.io/
Fast Exact Retrieval for Nearest-neighbor Lookup (FERN)
May 07, 2024Exact nearest neighbor search is a computationally intensive process, and even its simpler sibling -- vector retrieval -- can be computationally complex. This is exacerbated when retrieving vectors which have high-dimension $d$ relative to the number of vectors, $N$, in the database. Exact nearest neighbor retrieval has been generally acknowledged to be a $O(Nd)$ problem with no sub-linear solutions. Attention has instead shifted towards Approximate Nearest-Neighbor (ANN) retrieval techniques, many of which have sub-linear or even logarithmic time complexities. However, if our intuition from binary search problems (e.g. $d=1$ vector retrieval) carries, there ought to be a way to retrieve an organized representation of vectors without brute-forcing our way to a solution. For low dimension (e.g. $d=2$ or $d=3$ cases), \texttt{kd-trees} provide a $O(d\log N)$ algorithm for retrieval. Unfortunately the algorithm deteriorates rapidly to a $O(dN)$ solution at high dimensions (e.g. $k=128$), in practice. We propose a novel algorithm for logarithmic Fast Exact Retrieval for Nearest-neighbor lookup (FERN), inspired by \texttt{kd-trees}. The algorithm achieves $O(d\log N)$ look-up with 100\% recall on 10 million $d=128$ uniformly randomly generated vectors.\footnote{Code available at https://github.com/RichardZhu123/ferns}
Comparing Importance Sampling Based Methods for Mitigating the Effect of Class Imbalance
Feb 28, 2024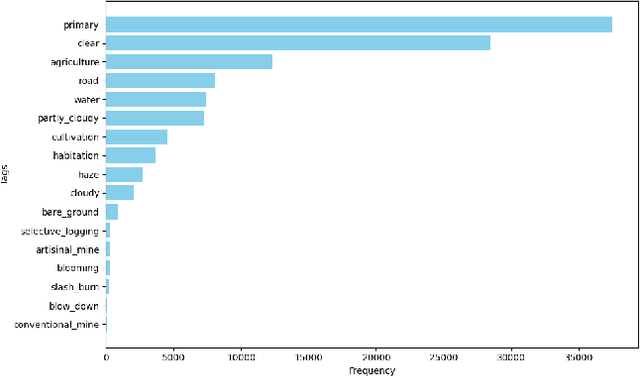
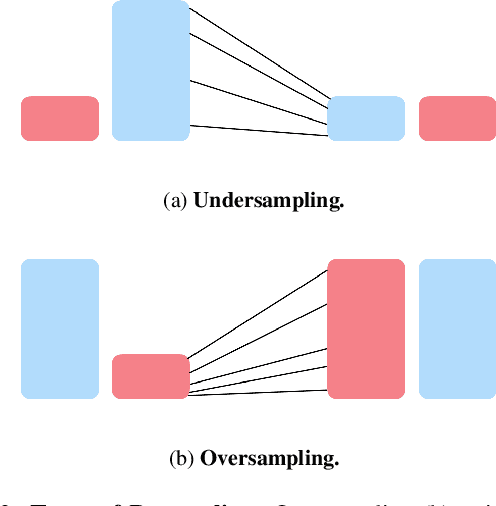
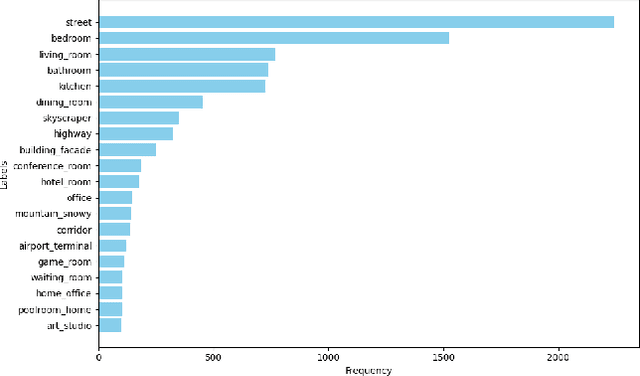

Most state-of-the-art computer vision models heavily depend on data. However, many datasets exhibit extreme class imbalance which has been shown to negatively impact model performance. Among the training-time and data-generation solutions that have been explored, one subset that leverages existing data is importance sampling. A good deal of this work focuses primarily on the CIFAR-10 and CIFAR-100 datasets which fail to be representative of the scale, composition, and complexity of current state-of-the-art datasets. In this work, we explore and compare three techniques that derive from importance sampling: loss reweighting, undersampling, and oversampling. Specifically, we compare the effect of these techniques on the performance of two encoders on an impactful satellite imagery dataset, Planet's Amazon Rainforest dataset, in preparation for another work. Furthermore, we perform supplemental experimentation on a scene classification dataset, ADE20K, to test on a contrasting domain and clarify our results. Across both types of encoders, we find that up-weighting the loss for and undersampling has a negigible effect on the performance on underrepresented classes. Additionally, our results suggest oversampling generally improves performance for the same underrepresented classes. Interestingly, our findings also indicate that there may exist some redundancy in data in the Planet dataset. Our work aims to provide a foundation for further work on the Planet dataset and similar domain-specific datasets. We open-source our code at https://github.com/RichardZhu123/514-class-imbalance for future work on other satellite imagery datasets as well.