 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA OmniDreams: Real-Time Generative World Model for Closed-Loop Autonomous Vehicle Simulation
Jun 02, 2026As autonomous vehicle capabilities advance, the safe evaluation of driving policies in long-tail scenarios remains a critical bottleneck. In closed-loop simulation, the driving policy model actively interacts with the environment, where its actions dynamically update the simulator state and directly influence the next set of generated sensor observations. While recent reconstruction-based neural simulators offer photorealism, they are fundamentally constrained by their initial captured data and struggle to generalize to highly dynamic or novel scenes. To overcome these limitations, we introduce OmniDreams, a foundation generative world model mid- and post-trained from the Cosmos diffusion model to autoregressively generate action-conditioned videos in real time. By leveraging the rich visual priors of Cosmos and mid- and post-training on 21k hours of driving scenarios, OmniDreams synthesizes complex, unobserved phenomena that are hard for traditional simulators to capture, such as extreme weather and unpredictable dynamic agent behaviors. Crucially, it autoregressively conditions its photorealistic sensor generation on past frames, the current simulator state, and immediate driving actions. Deployed in a closed-loop system with the Alpamayo 1 policy model and AlpaSim orchestrator, OmniDreams acts as a highly responsive, reactive environment, providing a scalable and comprehensive solution for training and evaluating next-generation autonomous driving policies. We additionally show preliminary results indicating that a world-action model (WAM) post-trained from OmniDreams achieves strong performance on the Physical AI Autonomous Vehicles NuRec dataset, surpassing the VLA-based Alpamayo 1.5 research policy model while using only 1/5 the total parameters. These results highlight the potential for a real-time world model like OmniDreams to also serve as a backbone for policy architectures.
Variance Reduction for Expectations with Diffusion Teachers
May 20, 2026Pretrained diffusion models serve as frozen teachers feeding downstream pipelines such as text-to-3D, single-step distillation, and data attribution. The teacher gradients these pipelines consume are Monte Carlo (MC) expectations over noise levels and Gaussian noise samples; their estimator variance dominates compute cost because each draw requires expensive upstream work (rendering, simulation, encoding). We introduce CARV, a compute-aware variance-accounting framework that motivates a hierarchical MC estimator: amortize the expensive upstream computation over cheap diffusion-noise resamples, sharpened by timestep importance sampling and a stratified-inverse-CDF construction. In our text-to-3D distillation and attribution experiments, CARV delivers 2-3x effective compute multipliers (most from amortized reuse; ~25% additional from IS+stratification) without changing the objective; in single-step distillation, the same techniques cut gradient variance by an order of magnitude but do not improve downstream FID, marking the regime where MC variance is no longer the bottleneck.
Reinforced Fast Weights with Next-Sequence Prediction
Feb 18, 2026Fast weight architectures offer a promising alternative to attention-based transformers for long-context modeling by maintaining constant memory overhead regardless of context length. However, their potential is limited by the next-token prediction (NTP) training paradigm. NTP optimizes single-token predictions and ignores semantic coherence across multiple tokens following a prefix. Consequently, fast weight models, which dynamically update their parameters to store contextual information, learn suboptimal representations that fail to capture long-range dependencies. We introduce REFINE (Reinforced Fast weIghts with Next sEquence prediction), a reinforcement learning framework that trains fast weight models under the next-sequence prediction (NSP) objective. REFINE selects informative token positions based on prediction entropy, generates multi-token rollouts, assigns self-supervised sequence-level rewards, and optimizes the model with group relative policy optimization (GRPO). REFINE is applicable throughout the training lifecycle of pre-trained language models: mid-training, post-training, and test-time training. Our experiments on LaCT-760M and DeltaNet-1.3B demonstrate that REFINE consistently outperforms supervised fine-tuning with NTP across needle-in-a-haystack retrieval, long-context question answering, and diverse tasks in LongBench. REFINE provides an effective and versatile framework for improving long-context modeling in fast weight architectures.
Motion Attribution for Video Generation
Jan 13, 2026Despite the rapid progress of video generation models, the role of data in influencing motion is poorly understood. We present Motive (MOTIon attribution for Video gEneration), a motion-centric, gradient-based data attribution framework that scales to modern, large, high-quality video datasets and models. We use this to study which fine-tuning clips improve or degrade temporal dynamics. Motive isolates temporal dynamics from static appearance via motion-weighted loss masks, yielding efficient and scalable motion-specific influence computation. On text-to-video models, Motive identifies clips that strongly affect motion and guides data curation that improves temporal consistency and physical plausibility. With Motive-selected high-influence data, our method improves both motion smoothness and dynamic degree on VBench, achieving a 74.1% human preference win rate compared with the pretrained base model. To our knowledge, this is the first framework to attribute motion rather than visual appearance in video generative models and to use it to curate fine-tuning data.
Actions as Language: Fine-Tuning VLMs into VLAs Without Catastrophic Forgetting
Sep 26, 2025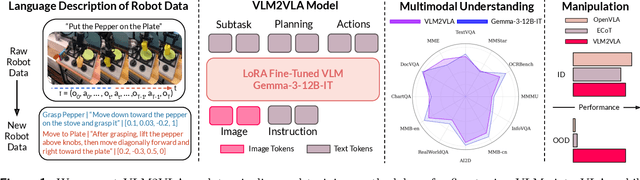
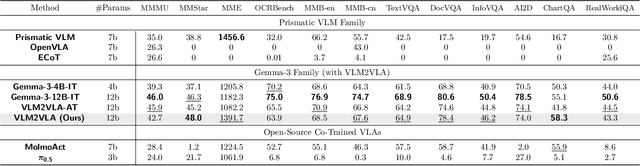

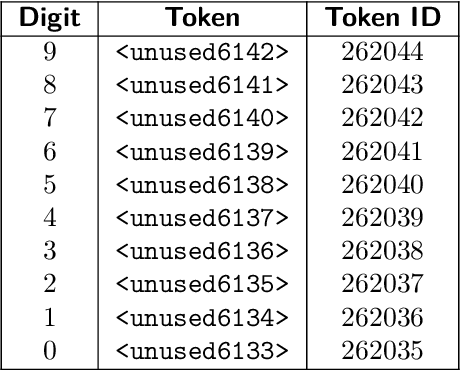
Fine-tuning vision-language models (VLMs) on robot teleoperation data to create vision-language-action (VLA) models is a promising paradigm for training generalist policies, but it suffers from a fundamental tradeoff: learning to produce actions often diminishes the VLM's foundational reasoning and multimodal understanding, hindering generalization to novel scenarios, instruction following, and semantic understanding. We argue that this catastrophic forgetting is due to a distribution mismatch between the VLM's internet-scale pretraining corpus and the robotics fine-tuning data. Inspired by this observation, we introduce VLM2VLA: a VLA training paradigm that first resolves this mismatch at the data level by representing low-level actions with natural language. This alignment makes it possible to train VLAs solely with Low-Rank Adaptation (LoRA), thereby minimally modifying the VLM backbone and averting catastrophic forgetting. As a result, the VLM can be fine-tuned on robot teleoperation data without fundamentally altering the underlying architecture and without expensive co-training on internet-scale VLM datasets. Through extensive Visual Question Answering (VQA) studies and over 800 real-world robotics experiments, we demonstrate that VLM2VLA preserves the VLM's core capabilities, enabling zero-shot generalization to novel tasks that require open-world semantic reasoning and multilingual instruction following.
Explain Before You Answer: A Survey on Compositional Visual Reasoning
Aug 24, 2025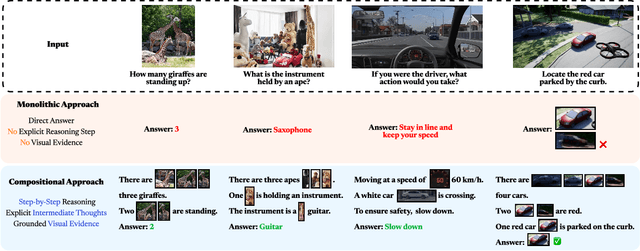
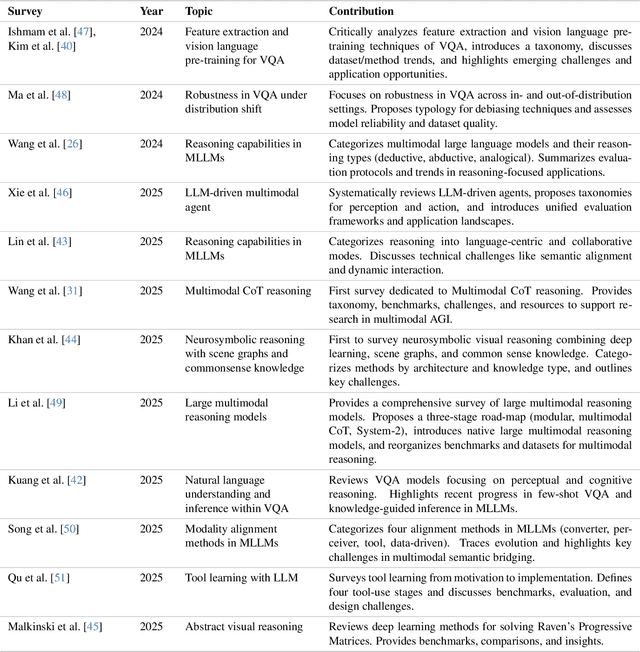
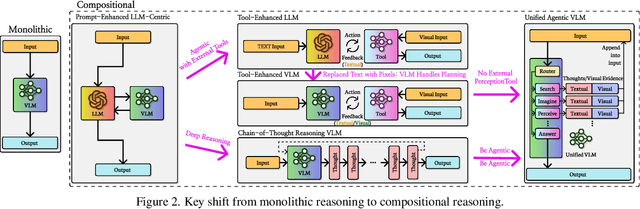
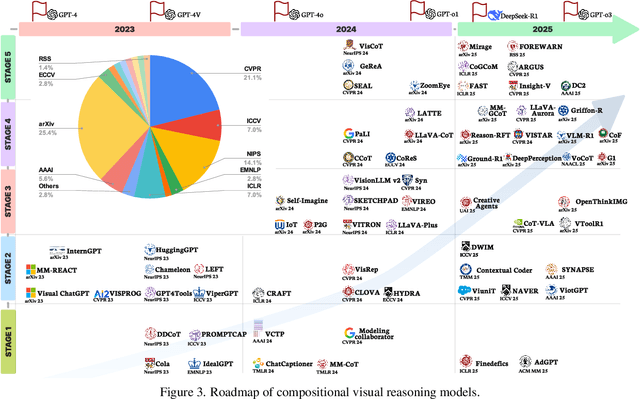
Compositional visual reasoning has emerged as a key research frontier in multimodal AI, aiming to endow machines with the human-like ability to decompose visual scenes, ground intermediate concepts, and perform multi-step logical inference. While early surveys focus on monolithic vision-language models or general multimodal reasoning, a dedicated synthesis of the rapidly expanding compositional visual reasoning literature is still missing. We fill this gap with a comprehensive survey spanning 2023 to 2025 that systematically reviews 260+ papers from top venues (CVPR, ICCV, NeurIPS, ICML, ACL, etc.). We first formalize core definitions and describe why compositional approaches offer advantages in cognitive alignment, semantic fidelity, robustness, interpretability, and data efficiency. Next, we trace a five-stage paradigm shift: from prompt-enhanced language-centric pipelines, through tool-enhanced LLMs and tool-enhanced VLMs, to recently minted chain-of-thought reasoning and unified agentic VLMs, highlighting their architectural designs, strengths, and limitations. We then catalog 60+ benchmarks and corresponding metrics that probe compositional visual reasoning along dimensions such as grounding accuracy, chain-of-thought faithfulness, and high-resolution perception. Drawing on these analyses, we distill key insights, identify open challenges (e.g., limitations of LLM-based reasoning, hallucination, a bias toward deductive reasoning, scalable supervision, tool integration, and benchmark limitations), and outline future directions, including world-model integration, human-AI collaborative reasoning, and richer evaluation protocols. By offering a unified taxonomy, historical roadmap, and critical outlook, this survey aims to serve as a foundational reference and inspire the next generation of compositional visual reasoning research.
DD-Ranking: Rethinking the Evaluation of Dataset Distillation
May 19, 2025



In recent years, dataset distillation has provided a reliable solution for data compression, where models trained on the resulting smaller synthetic datasets achieve performance comparable to those trained on the original datasets. To further improve the performance of synthetic datasets, various training pipelines and optimization objectives have been proposed, greatly advancing the field of dataset distillation. Recent decoupled dataset distillation methods introduce soft labels and stronger data augmentation during the post-evaluation phase and scale dataset distillation up to larger datasets (e.g., ImageNet-1K). However, this raises a question: Is accuracy still a reliable metric to fairly evaluate dataset distillation methods? Our empirical findings suggest that the performance improvements of these methods often stem from additional techniques rather than the inherent quality of the images themselves, with even randomly sampled images achieving superior results. Such misaligned evaluation settings severely hinder the development of DD. Therefore, we propose DD-Ranking, a unified evaluation framework, along with new general evaluation metrics to uncover the true performance improvements achieved by different methods. By refocusing on the actual information enhancement of distilled datasets, DD-Ranking provides a more comprehensive and fair evaluation standard for future research advancements.
COMPACT: COMPositional Atomic-to-Complex Visual Capability Tuning
Apr 30, 2025Multimodal Large Language Models (MLLMs) excel at simple vision-language tasks but struggle when faced with complex tasks that require multiple capabilities, such as simultaneously recognizing objects, counting them, and understanding their spatial relationships. This might be partially the result of the fact that Visual Instruction Tuning (VIT), a critical training step for MLLMs, has traditionally focused on scaling data volume, but not the compositional complexity of training examples. We propose COMPACT (COMPositional Atomic-to-complex visual Capability Tuning), which generates a training dataset explicitly controlling for the compositional complexity of the training examples. The data from COMPACT allows MLLMs to train on combinations of atomic capabilities to learn complex capabilities more efficiently. Across all benchmarks, COMPACT achieves comparable performance to the LLaVA-665k VIT while using less than 10% of its data budget, and even outperforms it on several, especially those involving complex multi-capability tasks. For example, COMPACT achieves substantial 83.3% improvement on MMStar and 94.0% improvement on MM-Vet compared to the full-scale VIT on particularly complex questions that require four or more atomic capabilities. COMPACT offers a scalable, data-efficient, visual compositional tuning recipe to improve on complex visual-language tasks.
ICONS: Influence Consensus for Vision-Language Data Selection
Jan 06, 2025



Visual Instruction Tuning typically requires a large amount of vision-language training data. This data often containing redundant information that increases computational costs without proportional performance gains. In this work, we introduce ICONS, a gradient-driven Influence CONsensus approach for vision-language data Selection that selects a compact training dataset for efficient multi-task training. The key element of our approach is cross-task influence consensus, which uses majority voting across task-specific influence matrices to identify samples that are consistently valuable across multiple tasks, allowing us to effectively prioritize data that optimizes for overall performance. Experiments show that models trained on our selected data (20% of LLaVA-665K) achieve 98.6% of the relative performance obtained using the full dataset. Additionally, we release this subset, LLaVA-ICONS-133K, a compact yet highly informative subset of LLaVA-665K visual instruction tuning data, preserving high impact training data for efficient vision-language model development.
SWE-bench Multimodal: Do AI Systems Generalize to Visual Software Domains?
Oct 04, 2024



Autonomous systems for software engineering are now capable of fixing bugs and developing features. These systems are commonly evaluated on SWE-bench (Jimenez et al., 2024a), which assesses their ability to solve software issues from GitHub repositories. However, SWE-bench uses only Python repositories, with problem statements presented predominantly as text and lacking visual elements such as images. This limited coverage motivates our inquiry into how existing systems might perform on unrepresented software engineering domains (e.g., front-end, game development, DevOps), which use different programming languages and paradigms. Therefore, we propose SWE-bench Multimodal (SWE-bench M), to evaluate systems on their ability to fix bugs in visual, user-facing JavaScript software. SWE-bench M features 617 task instances collected from 17 JavaScript libraries used for web interface design, diagramming, data visualization, syntax highlighting, and interactive mapping. Each SWE-bench M task instance contains at least one image in its problem statement or unit tests. Our analysis finds that top-performing SWE-bench systems struggle with SWE-bench M, revealing limitations in visual problem-solving and cross-language generalization. Lastly, we show that SWE-agent's flexible language-agnostic features enable it to substantially outperform alternatives on SWE-bench M, resolving 12% of task instances compared to 6% for the next best system.