 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNative Segmentation Vision Transformers
May 22, 2025Uniform downsampling remains the de facto standard for reducing spatial resolution in vision backbones. In this work, we propose an alternative design built around a content-aware spatial grouping layer, that dynamically assigns tokens to a reduced set based on image boundaries and their semantic content. Stacking our grouping layer across consecutive backbone stages results in hierarchical segmentation that arises natively in the feature extraction process, resulting in our coined Native Segmentation Vision Transformer. We show that a careful design of our architecture enables the emergence of strong segmentation masks solely from grouping layers, that is, without additional segmentation-specific heads. This sets the foundation for a new paradigm of native, backbone-level segmentation, which enables strong zero-shot results without mask supervision, as well as a minimal and efficient standalone model design for downstream segmentation tasks. Our project page is https://research.nvidia.com/labs/dvl/projects/native-segmentation.
Towards Learning to Complete Anything in Lidar
Apr 16, 2025We propose CAL (Complete Anything in Lidar) for Lidar-based shape-completion in-the-wild. This is closely related to Lidar-based semantic/panoptic scene completion. However, contemporary methods can only complete and recognize objects from a closed vocabulary labeled in existing Lidar datasets. Different to that, our zero-shot approach leverages the temporal context from multi-modal sensor sequences to mine object shapes and semantic features of observed objects. These are then distilled into a Lidar-only instance-level completion and recognition model. Although we only mine partial shape completions, we find that our distilled model learns to infer full object shapes from multiple such partial observations across the dataset. We show that our model can be prompted on standard benchmarks for Semantic and Panoptic Scene Completion, localize objects as (amodal) 3D bounding boxes, and recognize objects beyond fixed class vocabularies. Our project page is https://research.nvidia.com/labs/dvl/projects/complete-anything-lidar
Zero-Shot 4D Lidar Panoptic Segmentation
Apr 01, 2025Zero-shot 4D segmentation and recognition of arbitrary objects in Lidar is crucial for embodied navigation, with applications ranging from streaming perception to semantic mapping and localization. However, the primary challenge in advancing research and developing generalized, versatile methods for spatio-temporal scene understanding in Lidar lies in the scarcity of datasets that provide the necessary diversity and scale of annotations.To overcome these challenges, we propose SAL-4D (Segment Anything in Lidar--4D), a method that utilizes multi-modal robotic sensor setups as a bridge to distill recent developments in Video Object Segmentation (VOS) in conjunction with off-the-shelf Vision-Language foundation models to Lidar. We utilize VOS models to pseudo-label tracklets in short video sequences, annotate these tracklets with sequence-level CLIP tokens, and lift them to the 4D Lidar space using calibrated multi-modal sensory setups to distill them to our SAL-4D model. Due to temporal consistent predictions, we outperform prior art in 3D Zero-Shot Lidar Panoptic Segmentation (LPS) over $5$ PQ, and unlock Zero-Shot 4D-LPS.
Better Call SAL: Towards Learning to Segment Anything in Lidar
Mar 19, 2024



We propose $\texttt{SAL}$ ($\texttt{S}$egment $\texttt{A}$nything in $\texttt{L}$idar) method consisting of a text-promptable zero-shot model for segmenting and classifying any object in Lidar, and a pseudo-labeling engine that facilitates model training without manual supervision. While the established paradigm for $\textit{Lidar Panoptic Segmentation}$ (LPS) relies on manual supervision for a handful of object classes defined a priori, we utilize 2D vision foundation models to generate 3D supervision "for free". Our pseudo-labels consist of instance masks and corresponding CLIP tokens, which we lift to Lidar using calibrated multi-modal data. By training our model on these labels, we distill the 2D foundation models into our Lidar $\texttt{SAL}$ model. Even without manual labels, our model achieves $91\%$ in terms of class-agnostic segmentation and $44\%$ in terms of zero-shot LPS of the fully supervised state-of-the-art. Furthermore, we outperform several baselines that do not distill but only lift image features to 3D. More importantly, we demonstrate that $\texttt{SAL}$ supports arbitrary class prompts, can be easily extended to new datasets, and shows significant potential to improve with increasing amounts of self-labeled data.
SeMoLi: What Moves Together Belongs Together
Feb 29, 2024



We tackle semi-supervised object detection based on motion cues. Recent results suggest that heuristic-based clustering methods in conjunction with object trackers can be used to pseudo-label instances of moving objects and use these as supervisory signals to train 3D object detectors in Lidar data without manual supervision. We re-think this approach and suggest that both, object detection, as well as motion-inspired pseudo-labeling, can be tackled in a data-driven manner. We leverage recent advances in scene flow estimation to obtain point trajectories from which we extract long-term, class-agnostic motion patterns. Revisiting correlation clustering in the context of message passing networks, we learn to group those motion patterns to cluster points to object instances. By estimating the full extent of the objects, we obtain per-scan 3D bounding boxes that we use to supervise a Lidar object detection network. Our method not only outperforms prior heuristic-based approaches (57.5 AP, +14 improvement over prior work), more importantly, we show we can pseudo-label and train object detectors across datasets.
Lidar Panoptic Segmentation and Tracking without Bells and Whistles
Oct 19, 2023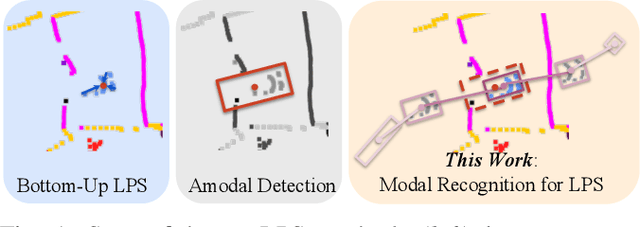
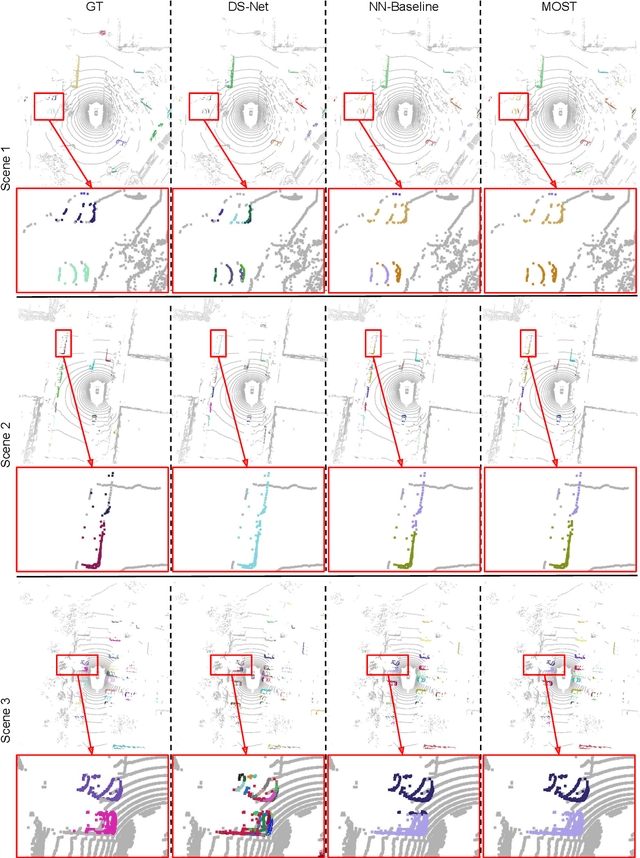
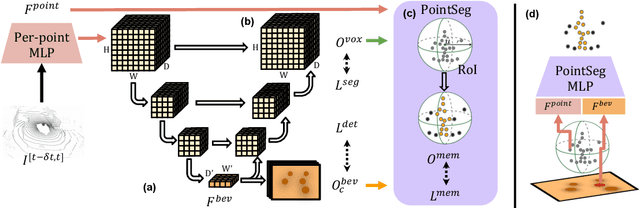
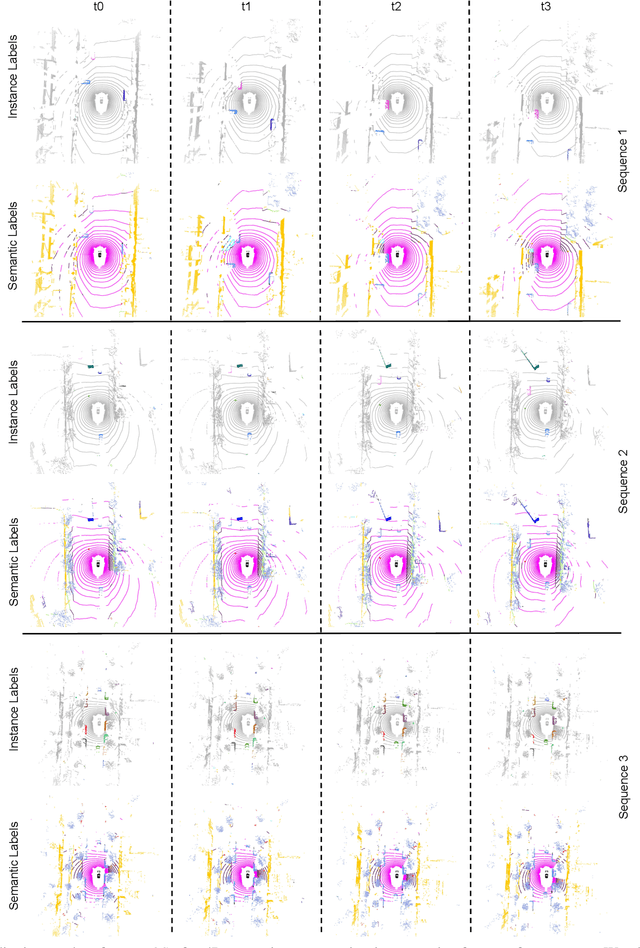
State-of-the-art lidar panoptic segmentation (LPS) methods follow bottom-up segmentation-centric fashion wherein they build upon semantic segmentation networks by utilizing clustering to obtain object instances. In this paper, we re-think this approach and propose a surprisingly simple yet effective detection-centric network for both LPS and tracking. Our network is modular by design and optimized for all aspects of both the panoptic segmentation and tracking task. One of the core components of our network is the object instance detection branch, which we train using point-level (modal) annotations, as available in segmentation-centric datasets. In the absence of amodal (cuboid) annotations, we regress modal centroids and object extent using trajectory-level supervision that provides information about object size, which cannot be inferred from single scans due to occlusions and the sparse nature of the lidar data. We obtain fine-grained instance segments by learning to associate lidar points with detected centroids. We evaluate our method on several 3D/4D LPS benchmarks and observe that our model establishes a new state-of-the-art among open-sourced models, outperforming recent query-based models.
Walking Your LiDOG: A Journey Through Multiple Domains for LiDAR Semantic Segmentation
Apr 23, 2023



The ability to deploy robots that can operate safely in diverse environments is crucial for developing embodied intelligent agents. As a community, we have made tremendous progress in within-domain LiDAR semantic segmentation. However, do these methods generalize across domains? To answer this question, we design the first experimental setup for studying domain generalization (DG) for LiDAR semantic segmentation (DG-LSS). Our results confirm a significant gap between methods, evaluated in a cross-domain setting: for example, a model trained on the source dataset (SemanticKITTI) obtains $26.53$ mIoU on the target data, compared to $48.49$ mIoU obtained by the model trained on the target domain (nuScenes). To tackle this gap, we propose the first method specifically designed for DG-LSS, which obtains $34.88$ mIoU on the target domain, outperforming all baselines. Our method augments a sparse-convolutional encoder-decoder 3D segmentation network with an additional, dense 2D convolutional decoder that learns to classify a birds-eye view of the point cloud. This simple auxiliary task encourages the 3D network to learn features that are robust to sensor placement shifts and resolution, and are transferable across domains. With this work, we aim to inspire the community to develop and evaluate future models in such cross-domain conditions.
Pix2Map: Cross-modal Retrieval for Inferring Street Maps from Images
Jan 10, 2023



Self-driving vehicles rely on urban street maps for autonomous navigation. In this paper, we introduce Pix2Map, a method for inferring urban street map topology directly from ego-view images, as needed to continually update and expand existing maps. This is a challenging task, as we need to infer a complex urban road topology directly from raw image data. The main insight of this paper is that this problem can be posed as cross-modal retrieval by learning a joint, cross-modal embedding space for images and existing maps, represented as discrete graphs that encode the topological layout of the visual surroundings. We conduct our experimental evaluation using the Argoverse dataset and show that it is indeed possible to accurately retrieve street maps corresponding to both seen and unseen roads solely from image data. Moreover, we show that our retrieved maps can be used to update or expand existing maps and even show proof-of-concept results for visual localization and image retrieval from spatial graphs.
Learning to Discover and Detect Objects
Oct 19, 2022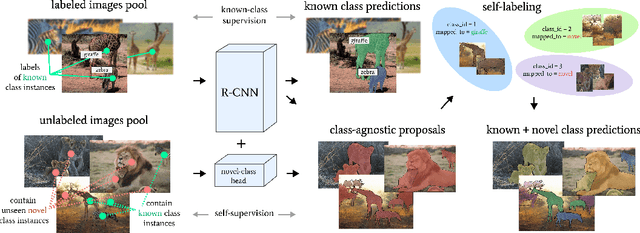



We tackle the problem of novel class discovery, detection, and localization (NCDL). In this setting, we assume a source dataset with labels for objects of commonly observed classes. Instances of other classes need to be discovered, classified, and localized automatically based on visual similarity, without human supervision. To this end, we propose a two-stage object detection network Region-based NCDL (RNCDL), that uses a region proposal network to localize object candidates and is trained to classify each candidate, either as one of the known classes, seen in the source dataset, or one of the extended set of novel classes, with a long-tail distribution constraint on the class assignments, reflecting the natural frequency of classes in the real world. By training our detection network with this objective in an end-to-end manner, it learns to classify all region proposals for a large variety of classes, including those that are not part of the labeled object class vocabulary. Our experiments conducted using COCO and LVIS datasets reveal that our method is significantly more effective compared to multi-stage pipelines that rely on traditional clustering algorithms or use pre-extracted crops. Furthermore, we demonstrate the generality of our approach by applying our method to a large-scale Visual Genome dataset, where our network successfully learns to detect various semantic classes without explicit supervision.
Quo Vadis: Is Trajectory Forecasting the Key Towards Long-Term Multi-Object Tracking?
Oct 14, 2022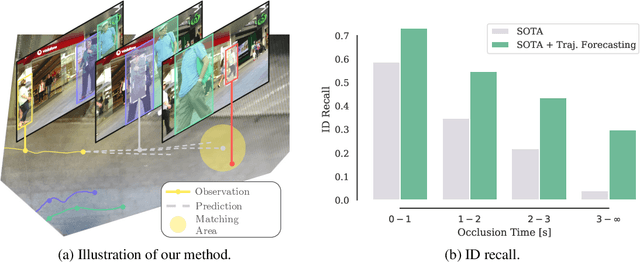
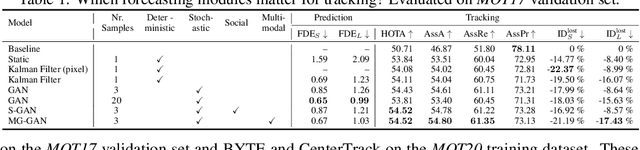
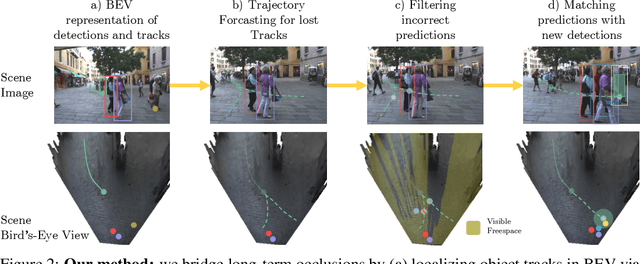
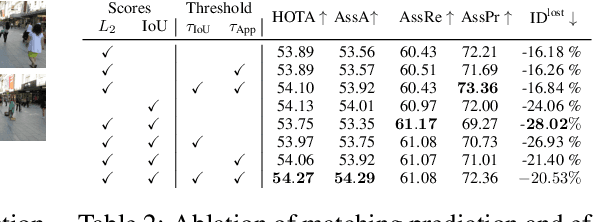
Recent developments in monocular multi-object tracking have been very successful in tracking visible objects and bridging short occlusion gaps, mainly relying on data-driven appearance models. While we have significantly advanced short-term tracking performance, bridging longer occlusion gaps remains elusive: state-of-the-art object trackers only bridge less than 10% of occlusions longer than three seconds. We suggest that the missing key is reasoning about future trajectories over a longer time horizon. Intuitively, the longer the occlusion gap, the larger the search space for possible associations. In this paper, we show that even a small yet diverse set of trajectory predictions for moving agents will significantly reduce this search space and thus improve long-term tracking robustness. Our experiments suggest that the crucial components of our approach are reasoning in a bird's-eye view space and generating a small yet diverse set of forecasts while accounting for their localization uncertainty. This way, we can advance state-of-the-art trackers on the MOTChallenge dataset and significantly improve their long-term tracking performance. This paper's source code and experimental data are available at https://github.com/dendorferpatrick/QuoVadis.