 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeFlow: Enabling Multi-frame Supervision for Self-Supervised Feed-forward Scene Flow Estimation
Feb 22, 2026Self-supervised feed-forward methods for scene flow estimation offer real-time efficiency, but their supervision from two-frame point correspondences is unreliable and often breaks down under occlusions. Multi-frame supervision has the potential to provide more stable guidance by incorporating motion cues from past frames, yet naive extensions of two-frame objectives are ineffective because point correspondences vary abruptly across frames, producing inconsistent signals. In the paper, we present TeFlow, enabling multi-frame supervision for feed-forward models by mining temporally consistent supervision. TeFlow introduces a temporal ensembling strategy that forms reliable supervisory signals by aggregating the most temporally consistent motion cues from a candidate pool built across multiple frames. Extensive evaluations demonstrate that TeFlow establishes a new state-of-the-art for self-supervised feed-forward methods, achieving performance gains of up to 33\% on the challenging Argoverse 2 and nuScenes datasets. Our method performs on par with leading optimization-based methods, yet speeds up 150 times. The code is open-sourced at https://github.com/KTH-RPL/OpenSceneFlow along with trained model weights.
ALORE: Autonomous Large-Object Rearrangement with a Legged Manipulator
Feb 04, 2026Endowing robots with the ability to rearrange various large and heavy objects, such as furniture, can substantially alleviate human workload. However, this task is extremely challenging due to the need to interact with diverse objects and efficiently rearrange multiple objects in complex environments while ensuring collision-free loco-manipulation. In this work, we present ALORE, an autonomous large-object rearrangement system for a legged manipulator that can rearrange various large objects across diverse scenarios. The proposed system is characterized by three main features: (i) a hierarchical reinforcement learning training pipeline for multi-object environment learning, where a high-level object velocity controller is trained on top of a low-level whole-body controller to achieve efficient and stable joint learning across multiple objects; (ii) two key modules, a unified interaction configuration representation and an object velocity estimator, that allow a single policy to regulate planar velocity of diverse objects accurately; and (iii) a task-and-motion planning framework that jointly optimizes object visitation order and object-to-target assignment, improving task efficiency while enabling online replanning. Comparisons against strong baselines show consistent superiority in policy generalization, object-velocity tracking accuracy, and multi-object rearrangement efficiency. Key modules are systematically evaluated, and extensive simulations and real-world experiments are conducted to validate the robustness and effectiveness of the entire system, which successfully completes 8 continuous loops to rearrange 32 chairs over nearly 40 minutes without a single failure, and executes long-distance autonomous rearrangement over an approximately 40 m route. The open-source packages are available at https://zhihaibi.github.io/Alore/.
RoMa v2: Harder Better Faster Denser Feature Matching
Nov 19, 2025Dense feature matching aims to estimate all correspondences between two images of a 3D scene and has recently been established as the gold-standard due to its high accuracy and robustness. However, existing dense matchers still fail or perform poorly for many hard real-world scenarios, and high-precision models are often slow, limiting their applicability. In this paper, we attack these weaknesses on a wide front through a series of systematic improvements that together yield a significantly better model. In particular, we construct a novel matching architecture and loss, which, combined with a curated diverse training distribution, enables our model to solve many complex matching tasks. We further make training faster through a decoupled two-stage matching-then-refinement pipeline, and at the same time, significantly reduce refinement memory usage through a custom CUDA kernel. Finally, we leverage the recent DINOv3 foundation model along with multiple other insights to make the model more robust and unbiased. In our extensive set of experiments we show that the resulting novel matcher sets a new state-of-the-art, being significantly more accurate than its predecessors. Code is available at https://github.com/Parskatt/romav2
DeltaFlow: An Efficient Multi-frame Scene Flow Estimation Method
Aug 23, 2025



Previous dominant methods for scene flow estimation focus mainly on input from two consecutive frames, neglecting valuable information in the temporal domain. While recent trends shift towards multi-frame reasoning, they suffer from rapidly escalating computational costs as the number of frames grows. To leverage temporal information more efficiently, we propose DeltaFlow ($\Delta$Flow), a lightweight 3D framework that captures motion cues via a $\Delta$ scheme, extracting temporal features with minimal computational cost, regardless of the number of frames. Additionally, scene flow estimation faces challenges such as imbalanced object class distributions and motion inconsistency. To tackle these issues, we introduce a Category-Balanced Loss to enhance learning across underrepresented classes and an Instance Consistency Loss to enforce coherent object motion, improving flow accuracy. Extensive evaluations on the Argoverse 2 and Waymo datasets show that $\Delta$Flow achieves state-of-the-art performance with up to 22% lower error and $2\times$ faster inference compared to the next-best multi-frame supervised method, while also demonstrating a strong cross-domain generalization ability. The code is open-sourced at https://github.com/Kin-Zhang/DeltaFlow along with trained model weights.
Running-time Analysis of ($μ+λ$) Evolutionary Combinatorial Optimization Based on Multiple-gain Estimation
Jul 03, 2025The running-time analysis of evolutionary combinatorial optimization is a fundamental topic in evolutionary computation. However, theoretical results regarding the $(\mu+\lambda)$ evolutionary algorithm (EA) for combinatorial optimization problems remain relatively scarce compared to those for simple pseudo-Boolean problems. This paper proposes a multiple-gain model to analyze the running time of EAs for combinatorial optimization problems. The proposed model is an improved version of the average gain model, which is a fitness-difference drift approach under the sigma-algebra condition to estimate the running time of evolutionary numerical optimization. The improvement yields a framework for estimating the expected first hitting time of a stochastic process in both average-case and worst-case scenarios. It also introduces novel running-time results of evolutionary combinatorial optimization, including two tighter time complexity upper bounds than the known results in the case of ($\mu+\lambda$) EA for the knapsack problem with favorably correlated weights, a closed-form expression of time complexity upper bound in the case of ($\mu+\lambda$) EA for general $k$-MAX-SAT problems and a tighter time complexity upper bounds than the known results in the case of ($\mu+\lambda$) EA for the traveling salesperson problem. Experimental results indicate that the practical running time aligns with the theoretical results, verifying that the multiple-gain model is an effective tool for running-time analysis of ($\mu+\lambda$) EA for combinatorial optimization problems.
Zero-Shot 4D Lidar Panoptic Segmentation
Apr 01, 2025Zero-shot 4D segmentation and recognition of arbitrary objects in Lidar is crucial for embodied navigation, with applications ranging from streaming perception to semantic mapping and localization. However, the primary challenge in advancing research and developing generalized, versatile methods for spatio-temporal scene understanding in Lidar lies in the scarcity of datasets that provide the necessary diversity and scale of annotations.To overcome these challenges, we propose SAL-4D (Segment Anything in Lidar--4D), a method that utilizes multi-modal robotic sensor setups as a bridge to distill recent developments in Video Object Segmentation (VOS) in conjunction with off-the-shelf Vision-Language foundation models to Lidar. We utilize VOS models to pseudo-label tracklets in short video sequences, annotate these tracklets with sequence-level CLIP tokens, and lift them to the 4D Lidar space using calibrated multi-modal sensory setups to distill them to our SAL-4D model. Due to temporal consistent predictions, we outperform prior art in 3D Zero-Shot Lidar Panoptic Segmentation (LPS) over $5$ PQ, and unlock Zero-Shot 4D-LPS.
Multiple-gain Estimation for Running Time of Evolutionary Combinatorial Optimization
Jan 13, 2025



The running-time analysis of evolutionary combinatorial optimization is a fundamental topic in evolutionary computation. Its current research mainly focuses on specific algorithms for simplified problems due to the challenge posed by fluctuating fitness values. This paper proposes a multiple-gain model to estimate the fitness trend of population during iterations. The proposed model is an improved version of the average gain model, which is the approach to estimate the running time of evolutionary algorithms for numerical optimization. The improvement yields novel results of evolutionary combinatorial optimization, including a briefer proof for the time complexity upper bound in the case of (1+1) EA for the Onemax problem, two tighter time complexity upper bounds than the known results in the case of (1+$\lambda$) EA for the knapsack problem with favorably correlated weights and a closed-form expression of time complexity upper bound in the case of (1+$\lambda$) EA for general $k$-MAX-SAT problems. The results indicate that the practical running time aligns with the theoretical results, verifying that the multiple-gain model is more general for running-time analysis of evolutionary combinatorial optimization than state-of-the-art methods.
DiffSF: Diffusion Models for Scene Flow Estimation
Mar 14, 2024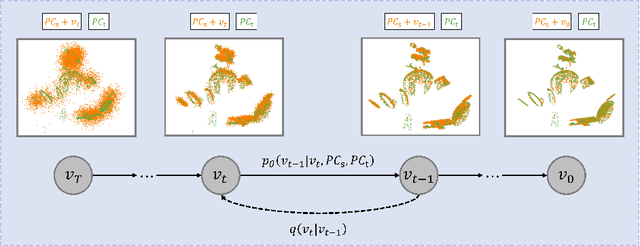
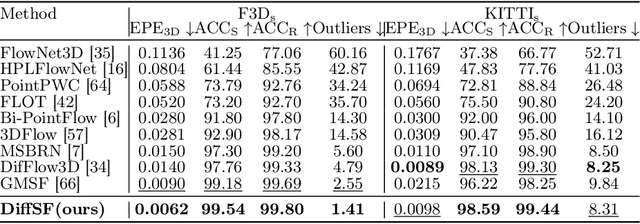
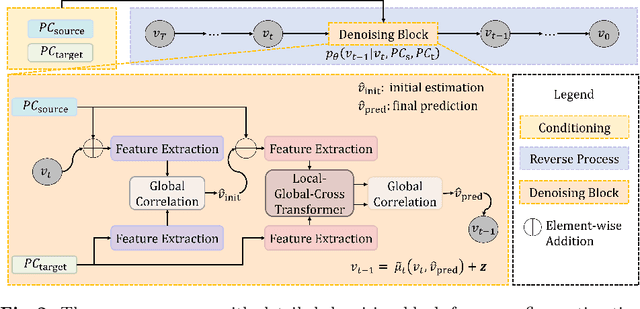
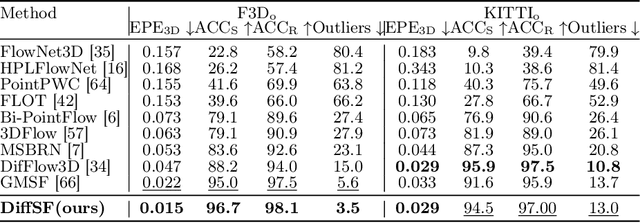
Scene flow estimation is an essential ingredient for a variety of real-world applications, especially for autonomous agents, such as self-driving cars and robots. While recent scene flow estimation approaches achieve a reasonable accuracy, their applicability to real-world systems additionally benefits from a reliability measure. Aiming at improving accuracy while additionally providing an estimate for uncertainty, we propose DiffSF that combines transformer-based scene flow estimation with denoising diffusion models. In the diffusion process, the ground truth scene flow vector field is gradually perturbed by adding Gaussian noise. In the reverse process, starting from randomly sampled Gaussian noise, the scene flow vector field prediction is recovered by conditioning on a source and a target point cloud. We show that the diffusion process greatly increases the robustness of predictions compared to prior approaches resulting in state-of-the-art performance on standard scene flow estimation benchmarks. Moreover, by sampling multiple times with different initial states, the denoising process predicts multiple hypotheses, which enables measuring the output uncertainty, allowing our approach to detect a majority of the inaccurate predictions. The code is available at https://github.com/ZhangYushan3/DiffSF.
GMSF: Global Matching Scene Flow
May 27, 2023We tackle the task of scene flow estimation from point clouds. Given a source and a target point cloud, the objective is to estimate a translation from each point in the source point cloud to the target, resulting in a 3D motion vector field. Previous dominant scene flow estimation methods require complicated coarse-to-fine or recurrent architectures as a multi-stage refinement. In contrast, we propose a significantly simpler single-scale one-shot global matching to address the problem. Our key finding is that reliable feature similarity between point pairs is essential and sufficient to estimate accurate scene flow. To this end, we propose to decompose the feature extraction step via a hybrid local-global-cross transformer architecture which is crucial to accurate and robust feature representations. Extensive experiments show that GMSF sets a new state-of-the-art on multiple scene flow estimation benchmarks. On FlyingThings3D, with the presence of occlusion points, GMSF reduces the outlier percentage from the previous best performance of 27.4% to 11.7%. On KITTI Scene Flow, without any fine-tuning, our proposed method shows state-of-the-art performance.
High-fidelity Pseudo-labels for Boosting Weakly-Supervised Segmentation
Apr 05, 2023



The task of image-level weakly-supervised semantic segmentation (WSSS) has gained popularity in recent years, as it reduces the vast data annotation cost for training segmentation models. The typical approach for WSSS involves training an image classification network using global average pooling (GAP) on convolutional feature maps. This enables the estimation of object locations based on class activation maps (CAMs), which identify the importance of image regions. The CAMs are then used to generate pseudo-labels, in the form of segmentation masks, to supervise a segmentation model in the absence of pixel-level ground truth. In case of the SEAM baseline, a previous work proposed to improve CAM learning in two ways: (1) Importance sampling, which is a substitute for GAP, and (2) the feature similarity loss, which utilizes a heuristic that object contours almost exclusively align with color edges in images. In this work, we propose a different probabilistic interpretation of CAMs for these techniques, rendering the likelihood more appropriate than the multinomial posterior. As a result, we propose an add-on method that can boost essentially any previous WSSS method, improving both the region similarity and contour quality of all implemented state-of-the-art baselines. This is demonstrated on a wide variety of baselines on the PASCAL VOC dataset. Experiments on the MS COCO dataset show that performance gains can also be achieved in a large-scale setting. Our code is available at https://github.com/arvijj/hfpl.