 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Equivariant Hyperspheres
May 24, 2023This paper presents an approach to learning nD features equivariant under orthogonal transformations for point cloud analysis, utilizing hyperspheres and regular n-simplexes. Our main contributions are theoretical and tackle major issues in geometric deep learning such as equivariance and invariance under geometric transformations. Namely, we enrich the recently developed theory of steerable 3D spherical neurons -- SO(3)-equivariant filter banks based on neurons with spherical decision surfaces -- by extending said neurons to nD, which we call deep equivariant hyperspheres, and enabling their stacking in multiple layers. Using the ModelNet40 benchmark, we experimentally verify our theoretical contributions and show a potential practical configuration of the proposed equivariant hyperspheres.
Flow-guided Semi-supervised Video Object Segmentation
Jan 25, 2023We propose an optical flow-guided approach for semi-supervised video object segmentation. Optical flow is usually exploited as additional guidance information in unsupervised video object segmentation. However, its relevance in semi-supervised video object segmentation has not been fully explored. In this work, we follow an encoder-decoder approach to address the segmentation task. A model to extract the combined information from optical flow and the image is proposed, which is then used as input to the target model and the decoder network. Unlike previous methods where concatenation is used to integrate information from image data and optical flow, a simple yet effective attention mechanism is exploited in our work. Experiments on DAVIS 2017 and YouTube-VOS 2019 show that by integrating the information extracted from optical flow into the original image branch results in a strong performance gain and our method achieves state-of-the-art performance.
TetraSphere: A Neural Descriptor for O(3)-Invariant Point Cloud Classification
Nov 26, 2022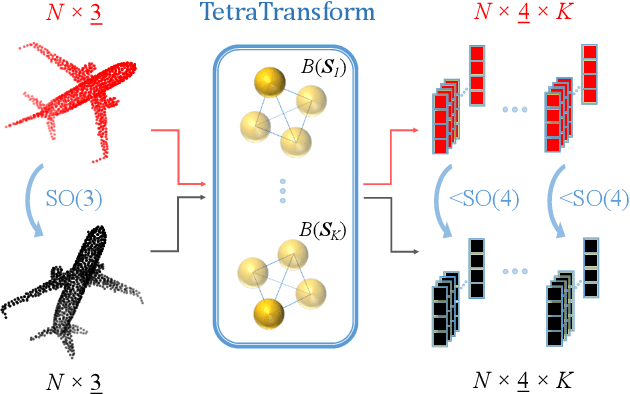
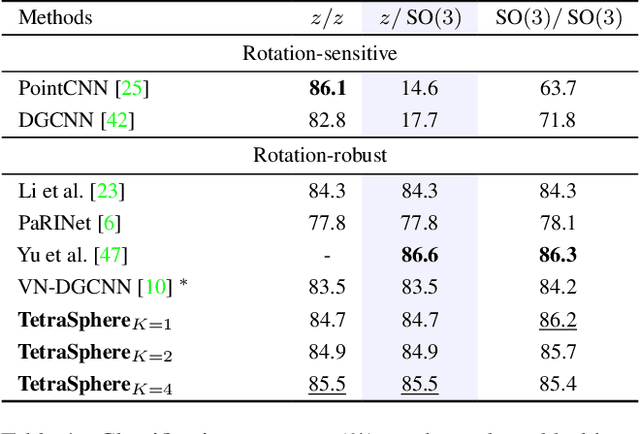
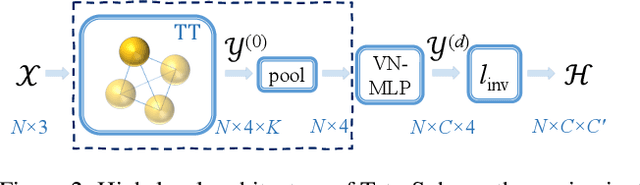
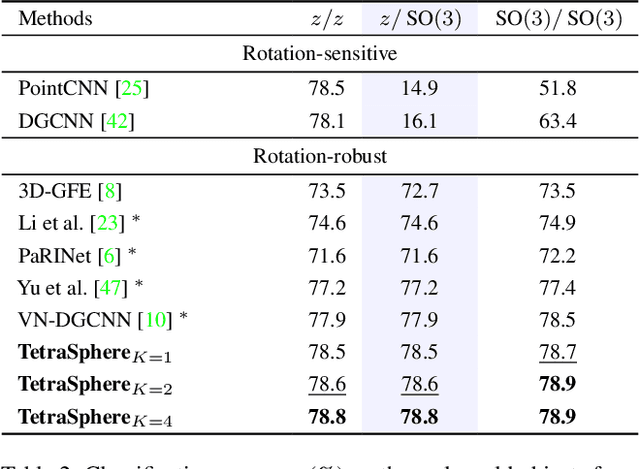
Rotation invariance is an important requirement for the analysis of 3D point clouds. In this paper, we present TetraSphere -- a learnable descriptor for rotation- and reflection-invariant 3D point cloud classification based on recently introduced steerable 3D spherical neurons and vector neurons, as well as the Gram matrix method. Taking 3D points as input, TetraSphere performs TetraTransform -- lifts the 3D input to 4D -- and extracts rotation-equivariant features, subsequently computing pair-wise O(3)-invariant inner products of these features. Remarkably, TetraSphere can be embedded into common point cloud processing models. We demonstrate its effectiveness and versatility by integrating it into DGCNN and VN-DGCNN, performing the classification of arbitrarily rotated ModelNet40 shapes. We show that using TetraSphere improves the performance and reduces the computational complexity by about 10% of the respective baseline methods.
Learning What to Learn for Video Object Segmentation
May 01, 2020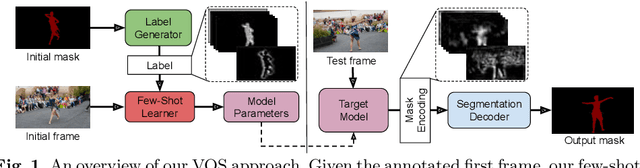

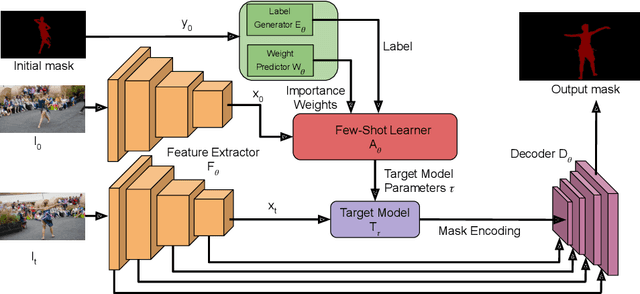
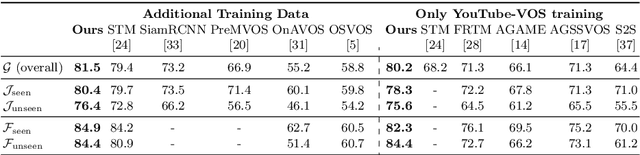
Video object segmentation (VOS) is a highly challenging problem, since the target object is only defined during inference with a given first-frame reference mask. The problem of how to capture and utilize this limited target information remains a fundamental research question. We address this by introducing an end-to-end trainable VOS architecture that integrates a differentiable few-shot learning module. This internal learner is designed to predict a powerful parametric model of the target by minimizing a segmentation error in the first frame. We further go beyond standard few-shot learning techniques by learning what the few-shot learner should learn. This allows us to achieve a rich internal representation of the target in the current frame, significantly increasing the segmentation accuracy of our approach. We perform extensive experiments on multiple benchmarks. Our approach sets a new state-of-the-art on the large-scale YouTube-VOS 2018 dataset by achieving an overall score of 81.5, corresponding to a 2.6% relative improvement over the previous best result.
Progress Extrapolating Algorithmic Learning to Arbitrary Sequence Lengths
Mar 23, 2020
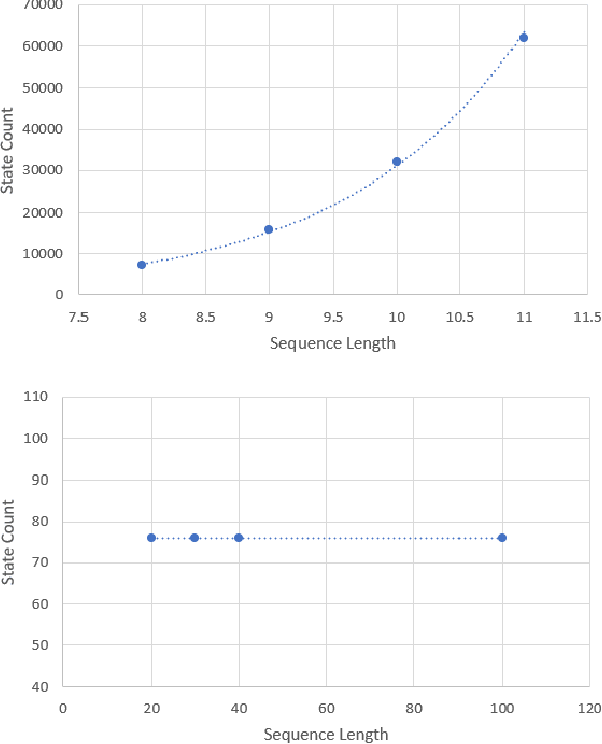
Recent neural network models for algorithmic tasks have led to significant improvements in extrapolation to sequences much longer than training, but it remains an outstanding problem that the performance still degrades for very long or adversarial sequences. We present alternative architectures and loss-terms to address these issues, and our testing of these approaches has not detected any remaining extrapolation errors within memory constraints. We focus on linear time algorithmic tasks including copy, parentheses parsing, and binary addition. First, activation binning was used to discretize the trained network in order to avoid computational drift from continuous operations, and a binning-based digital loss term was added to encourage discretizable representations. In addition, a localized differentiable memory (LDM) architecture, in contrast to distributed memory access, addressed remaining extrapolation errors and avoided unbounded growth of internal computational states. Previous work has found that algorithmic extrapolation issues can also be alleviated with approaches relying on program traces, but the current effort does not rely on such traces.
Learning Fast and Robust Target Models for Video Object Segmentation
Feb 27, 2020

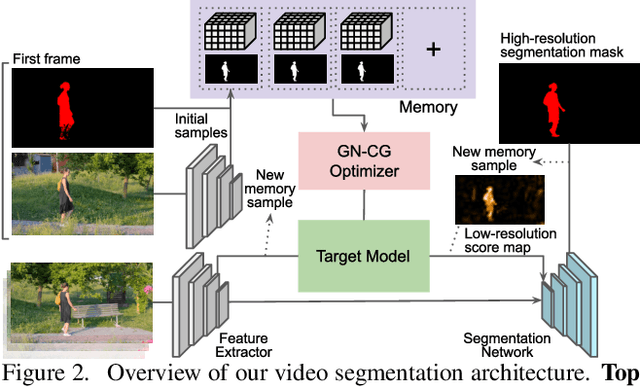
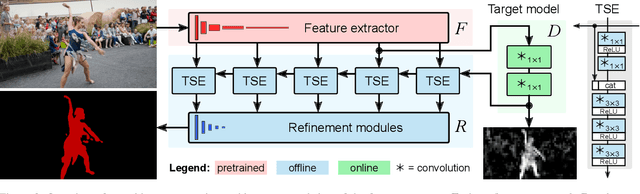
Video object segmentation (VOS) is a highly challenging problem since the initial mask, defining the target object, is only given at test-time. The main difficulty is to effectively handle appearance changes and similar background objects, while maintaining accurate segmentation. Most previous approaches fine-tune segmentation networks on the first frame, resulting in impractical frame-rates and risk of overfitting. More recent methods integrate generative target appearance models, but either achieve limited robustness or require large amounts of training data. We propose a novel VOS architecture consisting of two network components. The target appearance model consists of a light-weight module, learned during the inference stage using fast optimization techniques to predict a coarse but robust target segmentation. The segmentation model is exclusively trained offline, designed to process the coarse scores into high quality segmentation masks. Our method is fast, easily trainable and remains is highly effective in cases of limited training data. We perform extensive experiments on the challenging YouTube-VOS and DAVIS datasets. Our network achieves favorable performance, while operating at significantly higher frame-rates compared to state-of-the-art. Code is available at https://github.com/andr345/frtm-vos.
Discriminative Online Learning for Fast Video Object Segmentation
Apr 18, 2019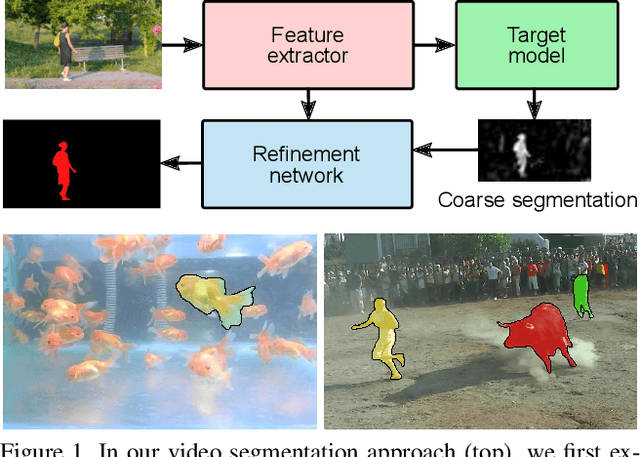

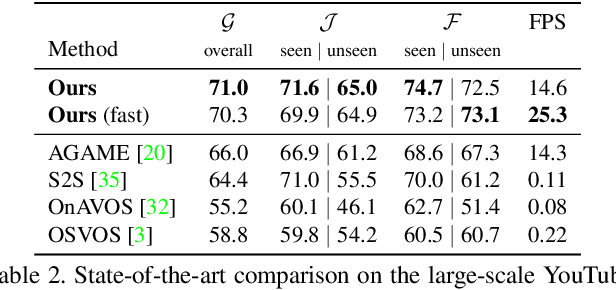
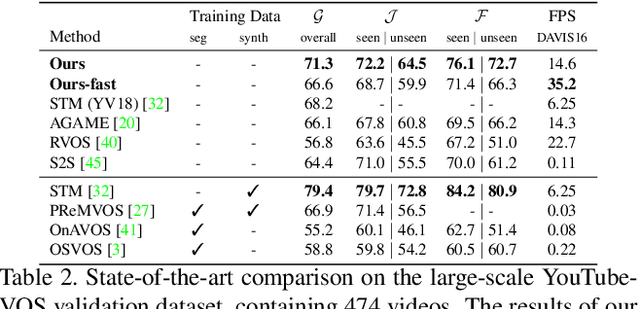
We address the highly challenging problem of video object segmentation. Given only the initial mask, the task is to segment the target in the subsequent frames. In order to effectively handle appearance changes and similar background objects, a robust representation of the target is required. Previous approaches either rely on fine-tuning a segmentation network on the first frame, or employ generative appearance models. Although partially successful, these methods often suffer from impractically low frame rates or unsatisfactory robustness. We propose a novel approach, based on a dedicated target appearance model that is exclusively learned online to discriminate between the target and background image regions. Importantly, we design a specialized loss and customized optimization techniques to enable highly efficient online training. Our light-weight target model is integrated into a carefully designed segmentation network, trained offline to enhance the predictions generated by the target model. Extensive experiments are performed on three datasets. Our approach achieves an overall score of over 70 on YouTube-VOS, while operating at 25 frames per second.
Beyond Correlation Filters: Learning Continuous Convolution Operators for Visual Tracking
Aug 29, 2016


Discriminative Correlation Filters (DCF) have demonstrated excellent performance for visual object tracking. The key to their success is the ability to efficiently exploit available negative data by including all shifted versions of a training sample. However, the underlying DCF formulation is restricted to single-resolution feature maps, significantly limiting its potential. In this paper, we go beyond the conventional DCF framework and introduce a novel formulation for training continuous convolution filters. We employ an implicit interpolation model to pose the learning problem in the continuous spatial domain. Our proposed formulation enables efficient integration of multi-resolution deep feature maps, leading to superior results on three object tracking benchmarks: OTB-2015 (+5.1% in mean OP), Temple-Color (+4.6% in mean OP), and VOT2015 (20% relative reduction in failure rate). Additionally, our approach is capable of sub-pixel localization, crucial for the task of accurate feature point tracking. We also demonstrate the effectiveness of our learning formulation in extensive feature point tracking experiments. Code and supplementary material are available at http://www.cvl.isy.liu.se/research/objrec/visualtracking/conttrack/index.html.
* Accepted at ECCV 2016