 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElastic3D: Controllable Stereo Video Conversion with Guided Latent Decoding
Dec 16, 2025The growing demand for immersive 3D content calls for automated monocular-to-stereo video conversion. We present Elastic3D, a controllable, direct end-to-end method for upgrading a conventional video to a binocular one. Our approach, based on (conditional) latent diffusion, avoids artifacts due to explicit depth estimation and warping. The key to its high-quality stereo video output is a novel, guided VAE decoder that ensures sharp and epipolar-consistent stereo video output. Moreover, our method gives the user control over the strength of the stereo effect (more precisely, the disparity range) at inference time, via an intuitive, scalar tuning knob. Experiments on three different datasets of real-world stereo videos show that our method outperforms both traditional warping-based and recent warping-free baselines and sets a new standard for reliable, controllable stereo video conversion. Please check the project page for the video samples https://elastic3d.github.io.
M2SVid: End-to-End Inpainting and Refinement for Monocular-to-Stereo Video Conversion
May 22, 2025We tackle the problem of monocular-to-stereo video conversion and propose a novel architecture for inpainting and refinement of the warped right view obtained by depth-based reprojection of the input left view. We extend the Stable Video Diffusion (SVD) model to utilize the input left video, the warped right video, and the disocclusion masks as conditioning input to generate a high-quality right camera view. In order to effectively exploit information from neighboring frames for inpainting, we modify the attention layers in SVD to compute full attention for discoccluded pixels. Our model is trained to generate the right view video in an end-to-end manner by minimizing image space losses to ensure high-quality generation. Our approach outperforms previous state-of-the-art methods, obtaining an average rank of 1.43 among the 4 compared methods in a user study, while being 6x faster than the second placed method.
LayoutVLM: Differentiable Optimization of 3D Layout via Vision-Language Models
Dec 03, 2024



Open-universe 3D layout generation arranges unlabeled 3D assets conditioned on language instruction. Large language models (LLMs) struggle with generating physically plausible 3D scenes and adherence to input instructions, particularly in cluttered scenes. We introduce LayoutVLM, a framework and scene layout representation that exploits the semantic knowledge of Vision-Language Models (VLMs) and supports differentiable optimization to ensure physical plausibility. LayoutVLM employs VLMs to generate two mutually reinforcing representations from visually marked images, and a self-consistent decoding process to improve VLMs spatial planning. Our experiments show that LayoutVLM addresses the limitations of existing LLM and constraint-based approaches, producing physically plausible 3D layouts better aligned with the semantic intent of input language instructions. We also demonstrate that fine-tuning VLMs with the proposed scene layout representation extracted from existing scene datasets can improve performance.
Fast Hierarchical Learning for Few-Shot Object Detection
Oct 10, 2022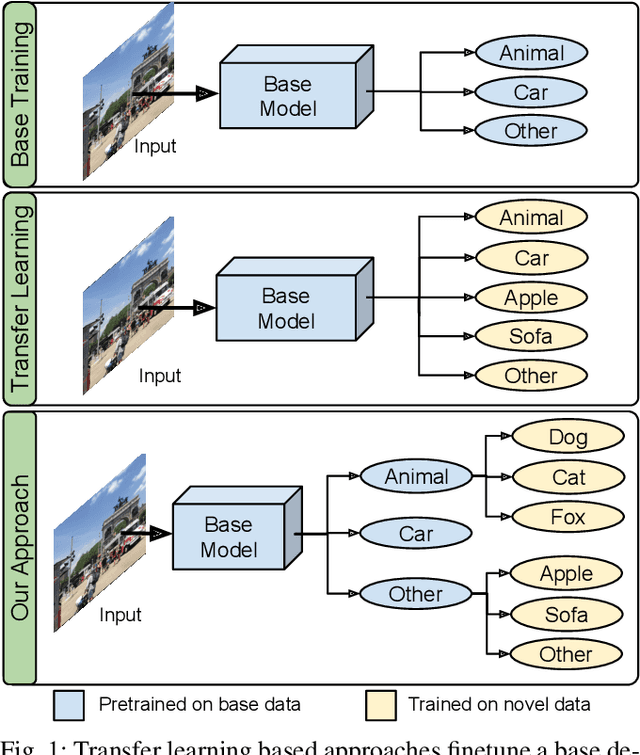
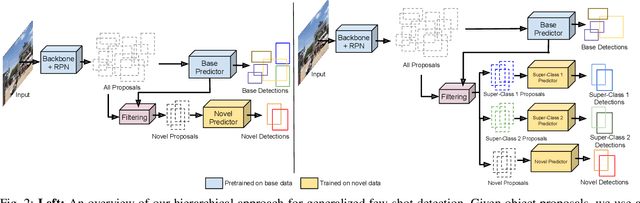
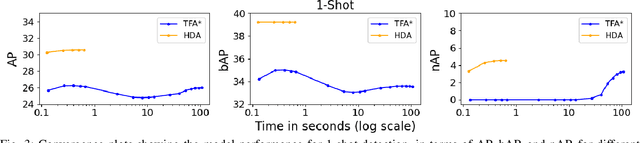

Transfer learning based approaches have recently achieved promising results on the few-shot detection task. These approaches however suffer from ``catastrophic forgetting'' issue due to finetuning of base detector, leading to sub-optimal performance on the base classes. Furthermore, the slow convergence rate of stochastic gradient descent (SGD) results in high latency and consequently restricts real-time applications. We tackle the aforementioned issues in this work. We pose few-shot detection as a hierarchical learning problem, where the novel classes are treated as the child classes of existing base classes and the background class. The detection heads for the novel classes are then trained using a specialized optimization strategy, leading to significantly lower training times compared to SGD. Our approach obtains competitive novel class performance on few-shot MS-COCO benchmark, while completely retaining the performance of the initial model on the base classes. We further demonstrate the application of our approach to a new class-refined few-shot detection task.
Transforming Model Prediction for Tracking
Mar 21, 2022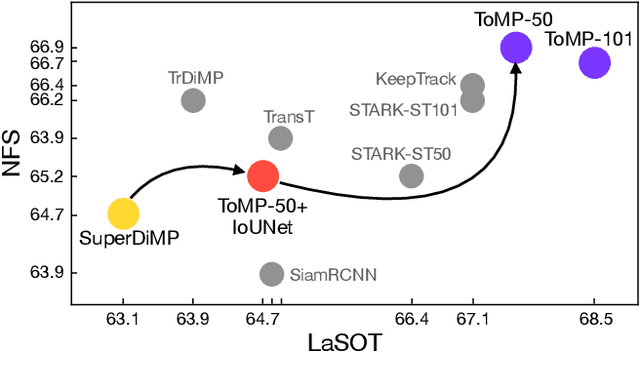
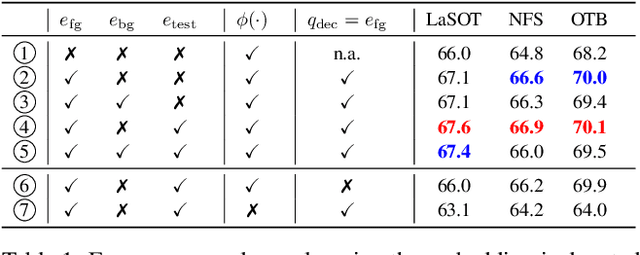
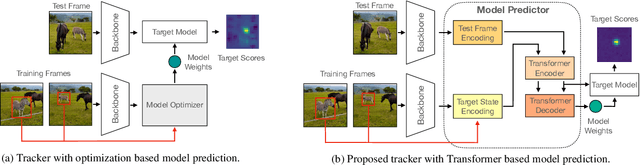

Optimization based tracking methods have been widely successful by integrating a target model prediction module, providing effective global reasoning by minimizing an objective function. While this inductive bias integrates valuable domain knowledge, it limits the expressivity of the tracking network. In this work, we therefore propose a tracker architecture employing a Transformer-based model prediction module. Transformers capture global relations with little inductive bias, allowing it to learn the prediction of more powerful target models. We further extend the model predictor to estimate a second set of weights that are applied for accurate bounding box regression. The resulting tracker relies on training and on test frame information in order to predict all weights transductively. We train the proposed tracker end-to-end and validate its performance by conducting comprehensive experiments on multiple tracking datasets. Our tracker sets a new state of the art on three benchmarks, achieving an AUC of 68.5% on the challenging LaSOT dataset.
Deep Reparametrization of Multi-Frame Super-Resolution and Denoising
Aug 18, 2021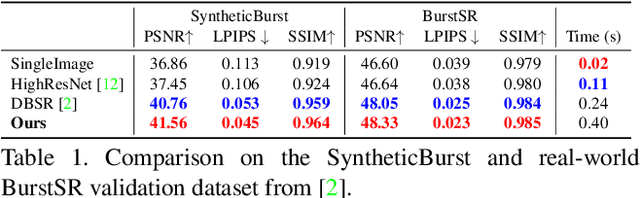
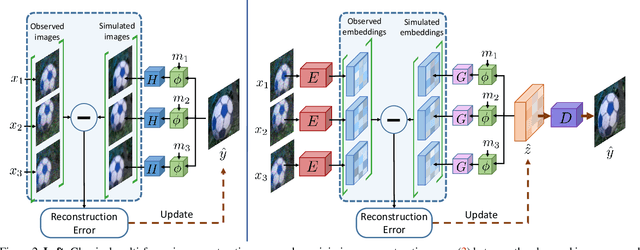
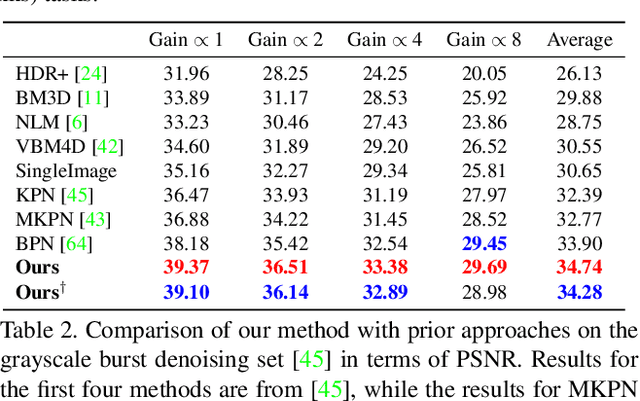

We propose a deep reparametrization of the maximum a posteriori formulation commonly employed in multi-frame image restoration tasks. Our approach is derived by introducing a learned error metric and a latent representation of the target image, which transforms the MAP objective to a deep feature space. The deep reparametrization allows us to directly model the image formation process in the latent space, and to integrate learned image priors into the prediction. Our approach thereby leverages the advantages of deep learning, while also benefiting from the principled multi-frame fusion provided by the classical MAP formulation. We validate our approach through comprehensive experiments on burst denoising and burst super-resolution datasets. Our approach sets a new state-of-the-art for both tasks, demonstrating the generality and effectiveness of the proposed formulation.
NTIRE 2021 Challenge on Burst Super-Resolution: Methods and Results
Jun 07, 2021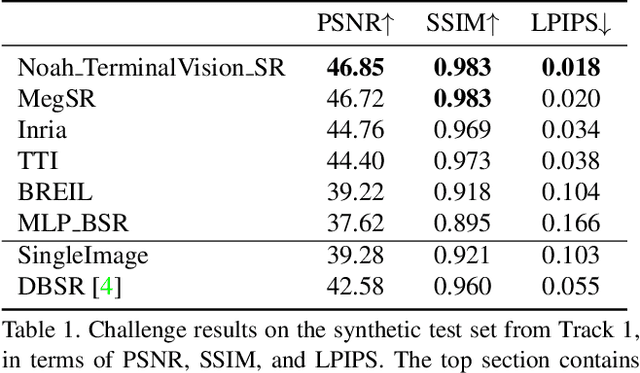

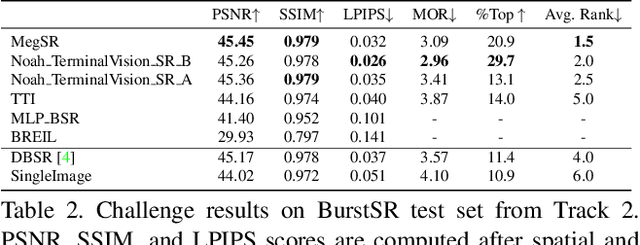

This paper reviews the NTIRE2021 challenge on burst super-resolution. Given a RAW noisy burst as input, the task in the challenge was to generate a clean RGB image with 4 times higher resolution. The challenge contained two tracks; Track 1 evaluating on synthetically generated data, and Track 2 using real-world bursts from mobile camera. In the final testing phase, 6 teams submitted results using a diverse set of solutions. The top-performing methods set a new state-of-the-art for the burst super-resolution task.
Deep Burst Super-Resolution
Jan 26, 2021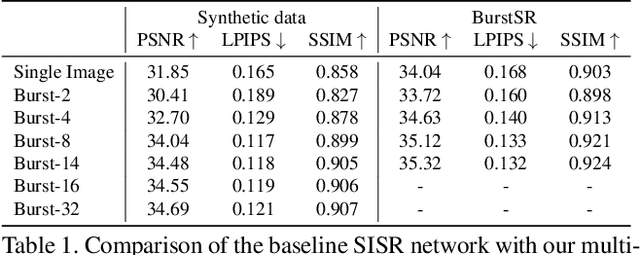
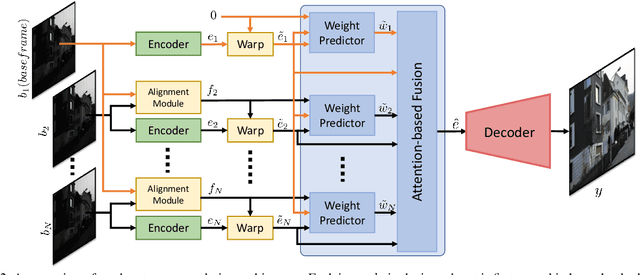
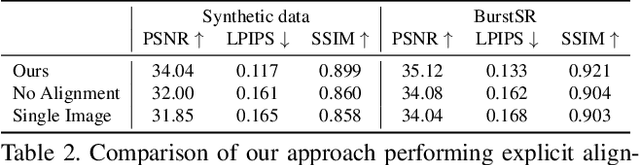
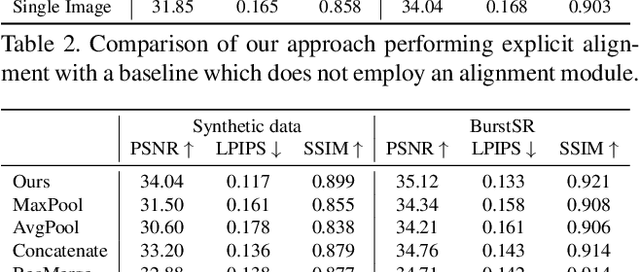
While single-image super-resolution (SISR) has attracted substantial interest in recent years, the proposed approaches are limited to learning image priors in order to add high frequency details. In contrast, multi-frame super-resolution (MFSR) offers the possibility of reconstructing rich details by combining signal information from multiple shifted images. This key advantage, along with the increasing popularity of burst photography, have made MFSR an important problem for real-world applications. We propose a novel architecture for the burst super-resolution task. Our network takes multiple noisy RAW images as input, and generates a denoised, super-resolved RGB image as output. This is achieved by explicitly aligning deep embeddings of the input frames using pixel-wise optical flow. The information from all frames are then adaptively merged using an attention-based fusion module. In order to enable training and evaluation on real-world data, we additionally introduce the BurstSR dataset, consisting of smartphone bursts and high-resolution DSLR ground-truth. We perform comprehensive experimental analysis, demonstrating the effectiveness of the proposed architecture.
Generating Masks from Boxes by Mining Spatio-Temporal Consistencies in Videos
Jan 06, 2021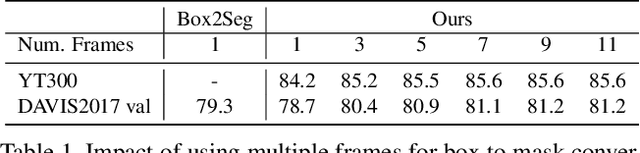
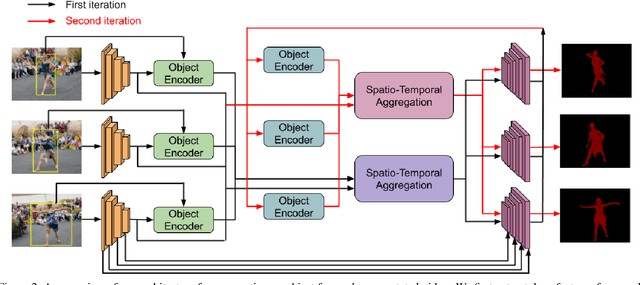


Segmenting objects in videos is a fundamental computer vision task. The current deep learning based paradigm offers a powerful, but data-hungry solution. However, current datasets are limited by the cost and human effort of annotating object masks in videos. This effectively limits the performance and generalization capabilities of existing video segmentation methods. To address this issue, we explore weaker form of bounding box annotations. We introduce a method for generating segmentation masks from per-frame bounding box annotations in videos. To this end, we propose a spatio-temporal aggregation module that effectively mines consistencies in the object and background appearance across multiple frames. We use our resulting accurate masks for weakly supervised training of video object segmentation (VOS) networks. We generate segmentation masks for large scale tracking datasets, using only their bounding box annotations. The additional data provides substantially better generalization performance leading to state-of-the-art results in both the VOS and more challenging tracking domain.
Know Your Surroundings: Exploiting Scene Information for Object Tracking
May 01, 2020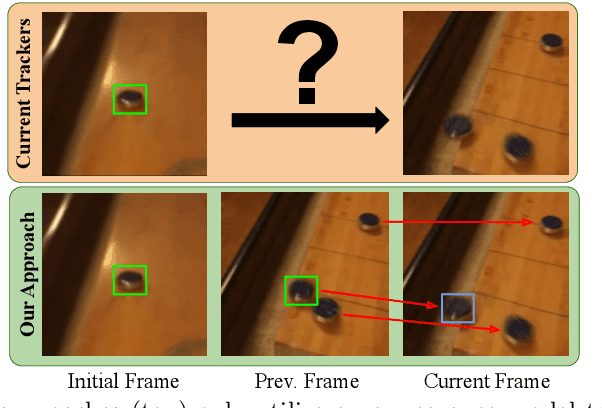

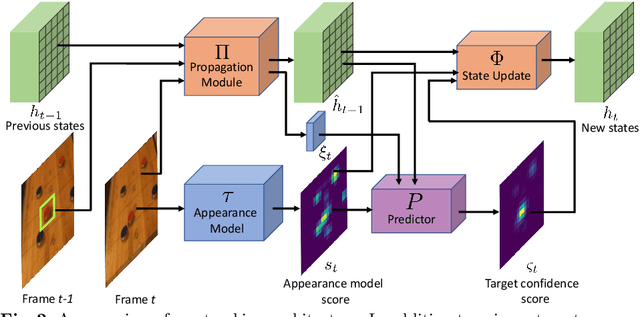

Current state-of-the-art trackers only rely on a target appearance model in order to localize the object in each frame. Such approaches are however prone to fail in case of e.g. fast appearance changes or presence of distractor objects, where a target appearance model alone is insufficient for robust tracking. Having the knowledge about the presence and locations of other objects in the surrounding scene can be highly beneficial in such cases. This scene information can be propagated through the sequence and used to, for instance, explicitly avoid distractor objects and eliminate target candidate regions. In this work, we propose a novel tracking architecture which can utilize scene information for tracking. Our tracker represents such information as dense localized state vectors, which can encode, for example, if the local region is target, background, or distractor. These state vectors are propagated through the sequence and combined with the appearance model output to localize the target. Our network is learned to effectively utilize the scene information by directly maximizing tracking performance on video segments. The proposed approach sets a new state-of-the-art on 3 tracking benchmarks, achieving an AO score of 63.6% on the recent GOT-10k dataset.