 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximizing Discrimination Capability of Knowledge Distillation with Energy-based Score
Nov 24, 2023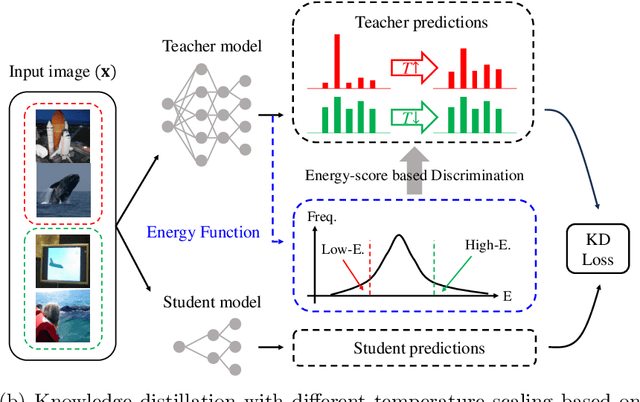
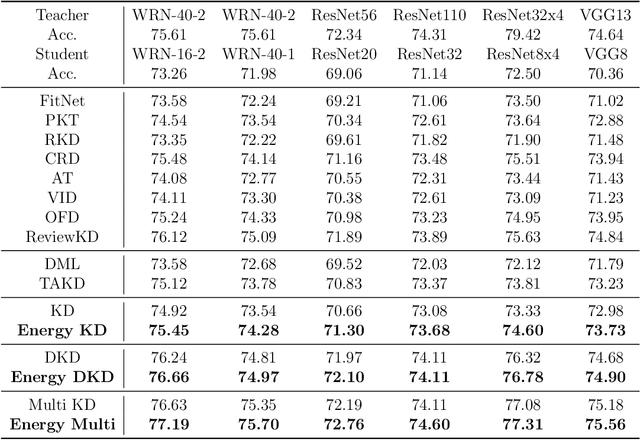
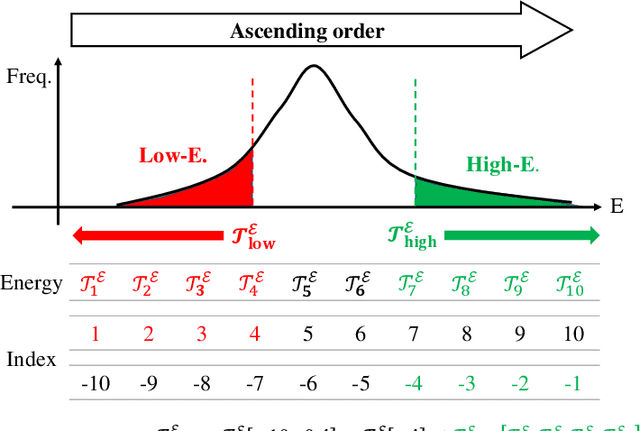
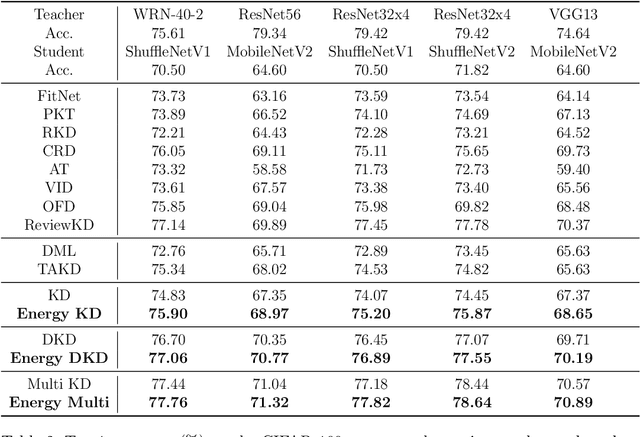
To apply the latest computer vision techniques that require a large computational cost in real industrial applications, knowledge distillation methods (KDs) are essential. Existing logit-based KDs apply the constant temperature scaling to all samples in dataset, limiting the utilization of knowledge inherent in each sample individually. In our approach, we classify the dataset into two categories (i.e., low energy and high energy samples) based on their energy score. Through experiments, we have confirmed that low energy samples exhibit high confidence scores, indicating certain predictions, while high energy samples yield low confidence scores, meaning uncertain predictions. To distill optimal knowledge by adjusting non-target class predictions, we apply a higher temperature to low energy samples to create smoother distributions and a lower temperature to high energy samples to achieve sharper distributions. When compared to previous logit-based and feature-based methods, our energy-based KD (Energy KD) achieves better performance on various datasets. Especially, Energy KD shows significant improvements on CIFAR-100-LT and ImageNet datasets, which contain many challenging samples. Furthermore, we propose high energy-based data augmentation (HE-DA) for further improving the performance. We demonstrate that meaningful performance improvement could be achieved by augmenting only 20-50% of dataset, suggesting that it can be employed on resource-limited devices. To the best of our knowledge, this paper represents the first attempt to make use of energy scores in KD and DA, and we believe it will greatly contribute to future research.
Cosine Similarity Knowledge Distillation for Individual Class Information Transfer
Nov 24, 2023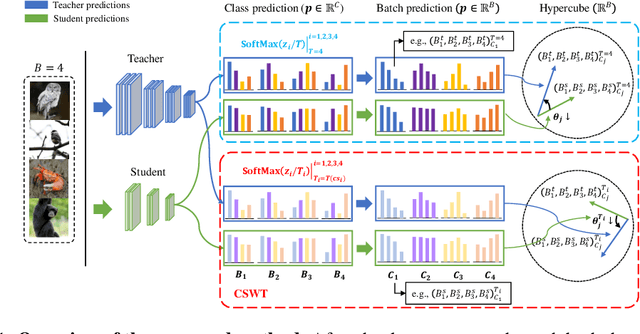

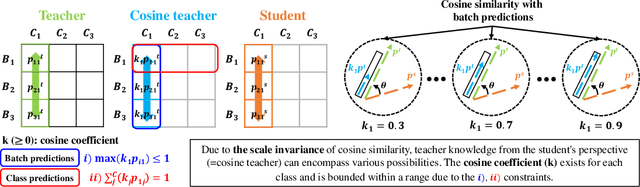

Previous logits-based Knowledge Distillation (KD) have utilized predictions about multiple categories within each sample (i.e., class predictions) and have employed Kullback-Leibler (KL) divergence to reduce the discrepancy between the student and teacher predictions. Despite the proliferation of KD techniques, the student model continues to fall short of achieving a similar level as teachers. In response, we introduce a novel and effective KD method capable of achieving results on par with or superior to the teacher models performance. We utilize teacher and student predictions about multiple samples for each category (i.e., batch predictions) and apply cosine similarity, a commonly used technique in Natural Language Processing (NLP) for measuring the resemblance between text embeddings. This metric's inherent scale-invariance property, which relies solely on vector direction and not magnitude, allows the student to dynamically learn from the teacher's knowledge, rather than being bound by a fixed distribution of the teacher's knowledge. Furthermore, we propose a method called cosine similarity weighted temperature (CSWT) to improve the performance. CSWT reduces the temperature scaling in KD when the cosine similarity between the student and teacher models is high, and conversely, it increases the temperature scaling when the cosine similarity is low. This adjustment optimizes the transfer of information from the teacher to the student model. Extensive experimental results show that our proposed method serves as a viable alternative to existing methods. We anticipate that this approach will offer valuable insights for future research on model compression.
Robustness-Reinforced Knowledge Distillation with Correlation Distance and Network Pruning
Nov 23, 2023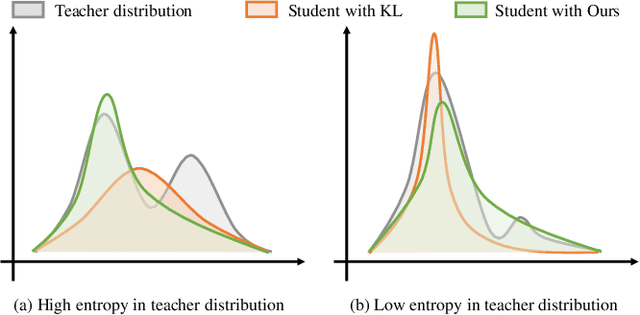
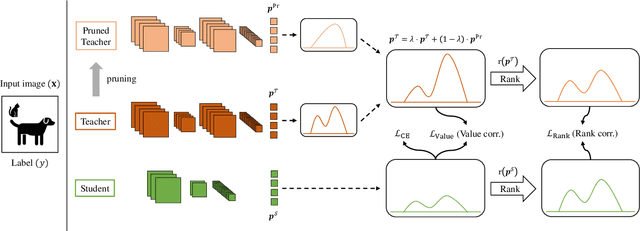
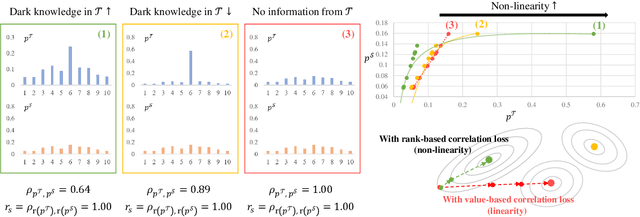
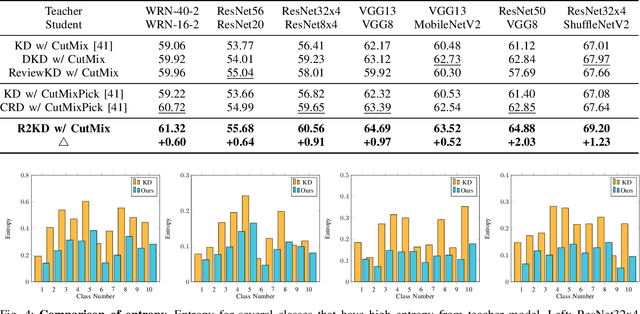
The improvement in the performance of efficient and lightweight models (i.e., the student model) is achieved through knowledge distillation (KD), which involves transferring knowledge from more complex models (i.e., the teacher model). However, most existing KD techniques rely on Kullback-Leibler (KL) divergence, which has certain limitations. First, if the teacher distribution has high entropy, the KL divergence's mode-averaging nature hinders the transfer of sufficient target information. Second, when the teacher distribution has low entropy, the KL divergence tends to excessively focus on specific modes, which fails to convey an abundant amount of valuable knowledge to the student. Consequently, when dealing with datasets that contain numerous confounding or challenging samples, student models may struggle to acquire sufficient knowledge, resulting in subpar performance. Furthermore, in previous KD approaches, we observed that data augmentation, a technique aimed at enhancing a model's generalization, can have an adverse impact. Therefore, we propose a Robustness-Reinforced Knowledge Distillation (R2KD) that leverages correlation distance and network pruning. This approach enables KD to effectively incorporate data augmentation for performance improvement. Extensive experiments on various datasets, including CIFAR-100, FGVR, TinyImagenet, and ImageNet, demonstrate our method's superiority over current state-of-the-art methods.
NTIRE 2021 Challenge on Burst Super-Resolution: Methods and Results
Jun 07, 2021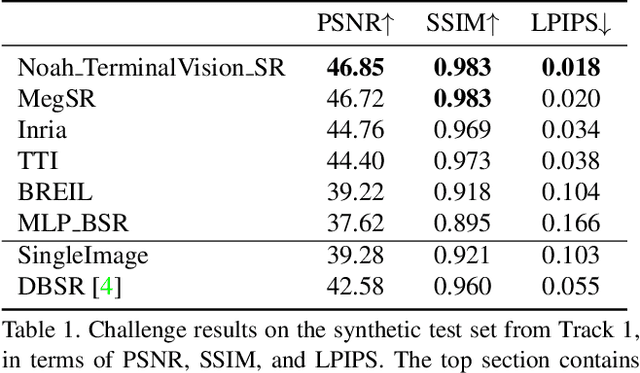

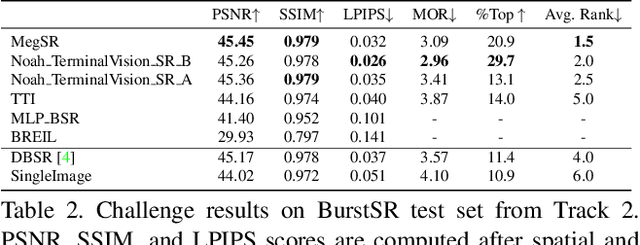

This paper reviews the NTIRE2021 challenge on burst super-resolution. Given a RAW noisy burst as input, the task in the challenge was to generate a clean RGB image with 4 times higher resolution. The challenge contained two tracks; Track 1 evaluating on synthetically generated data, and Track 2 using real-world bursts from mobile camera. In the final testing phase, 6 teams submitted results using a diverse set of solutions. The top-performing methods set a new state-of-the-art for the burst super-resolution task.
MHSAN: Multi-Head Self-Attention Network for Visual Semantic Embedding
Jan 11, 2020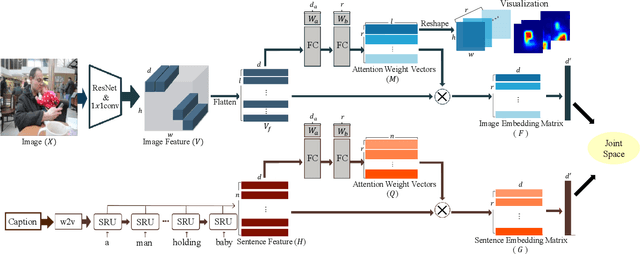
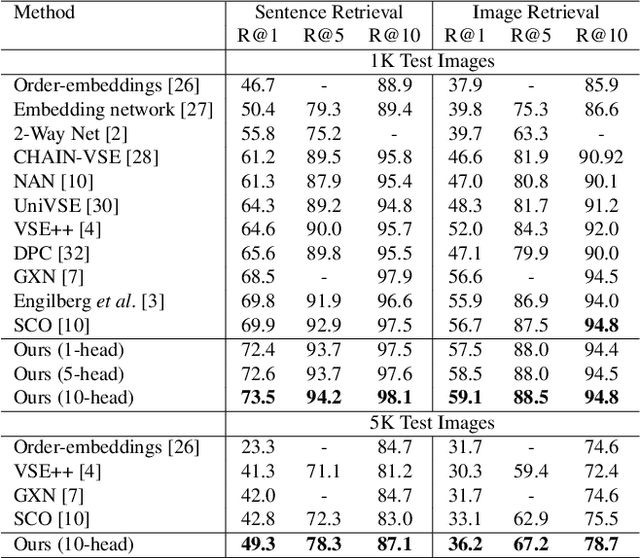
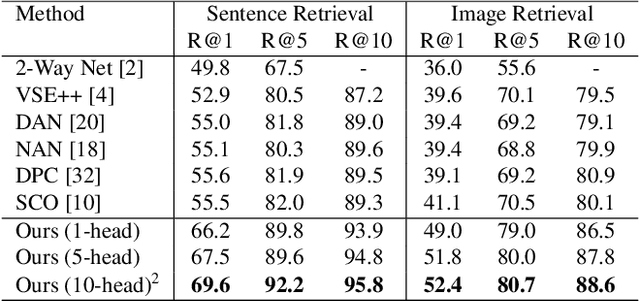

Visual-semantic embedding enables various tasks such as image-text retrieval, image captioning, and visual question answering. The key to successful visual-semantic embedding is to express visual and textual data properly by accounting for their intricate relationship. While previous studies have achieved much advance by encoding the visual and textual data into a joint space where similar concepts are closely located, they often represent data by a single vector ignoring the presence of multiple important components in an image or text. Thus, in addition to the joint embedding space, we propose a novel multi-head self-attention network to capture various components of visual and textual data by attending to important parts in data. Our approach achieves the new state-of-the-art results in image-text retrieval tasks on MS-COCO and Flicker30K datasets. Through the visualization of the attention maps that capture distinct semantic components at multiple positions in the image and the text, we demonstrate that our method achieves an effective and interpretable visual-semantic joint space.
Representation of White- and Black-Box Adversarial Examples in Deep Neural Networks and Humans: A Functional Magnetic Resonance Imaging Study
May 07, 2019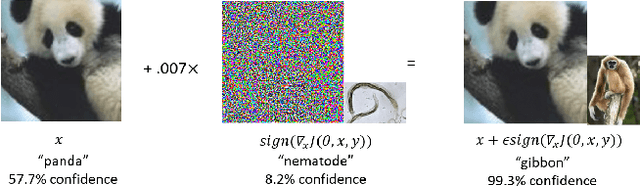
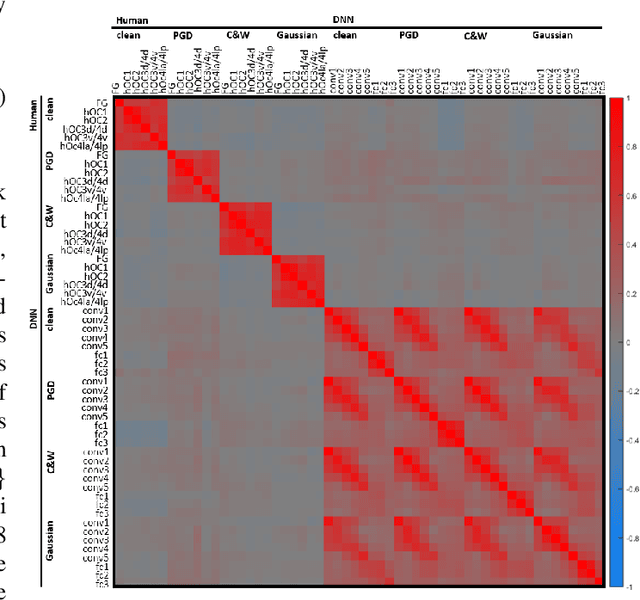
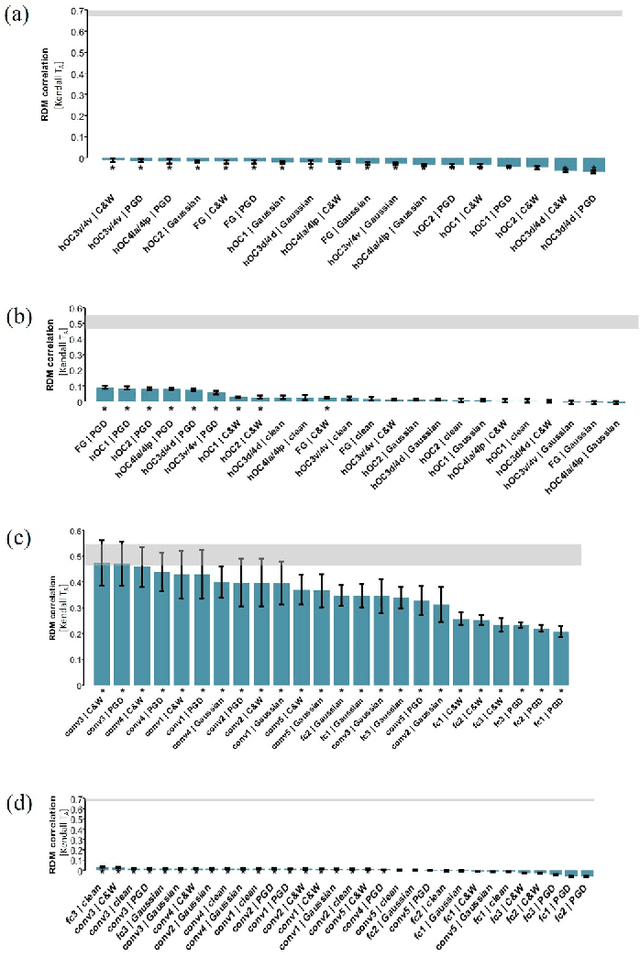
The recent success of brain-inspired deep neural networks (DNNs) in solving complex, high-level visual tasks has led to rising expectations for their potential to match the human visual system. However, DNNs exhibit idiosyncrasies that suggest their visual representation and processing might be substantially different from human vision. One limitation of DNNs is that they are vulnerable to adversarial examples, input images on which subtle, carefully designed noises are added to fool a machine classifier. The robustness of the human visual system against adversarial examples is potentially of great importance as it could uncover a key mechanistic feature that machine vision is yet to incorporate. In this study, we compare the visual representations of white- and black-box adversarial examples in DNNs and humans by leveraging functional magnetic resonance imaging (fMRI). We find a small but significant difference in representation patterns for different (i.e. white- versus black- box) types of adversarial examples for both humans and DNNs. However, human performance on categorical judgment is not degraded by noise regardless of the type unlike DNN. These results suggest that adversarial examples may be differentially represented in the human visual system, but unable to affect the perceptual experience.