 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximizing Discrimination Capability of Knowledge Distillation with Energy-based Score
Paper and Code
Nov 24, 2023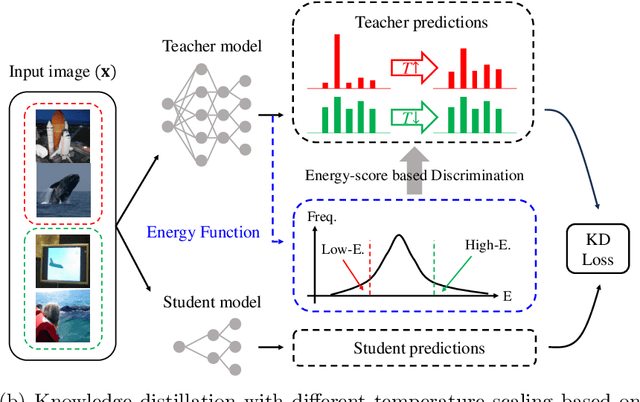
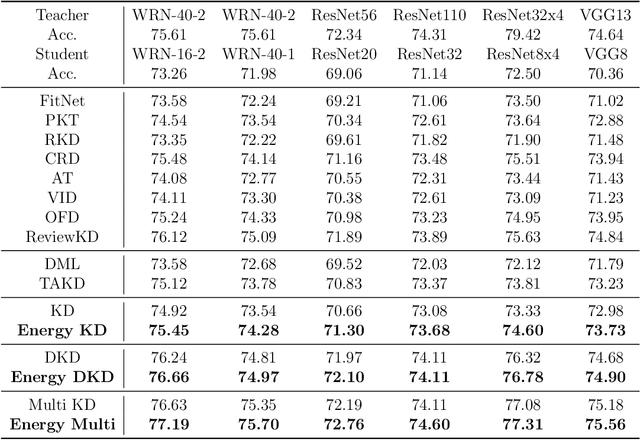
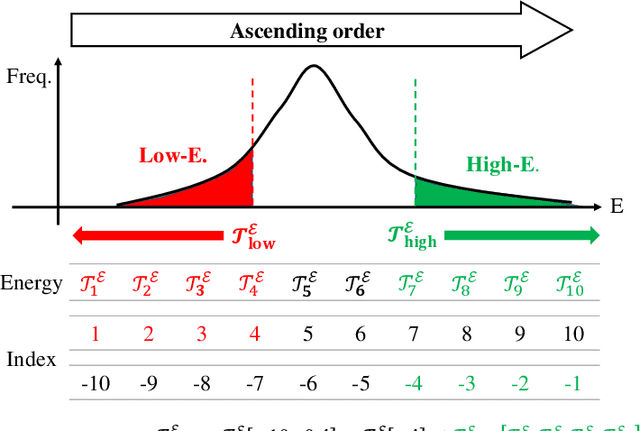
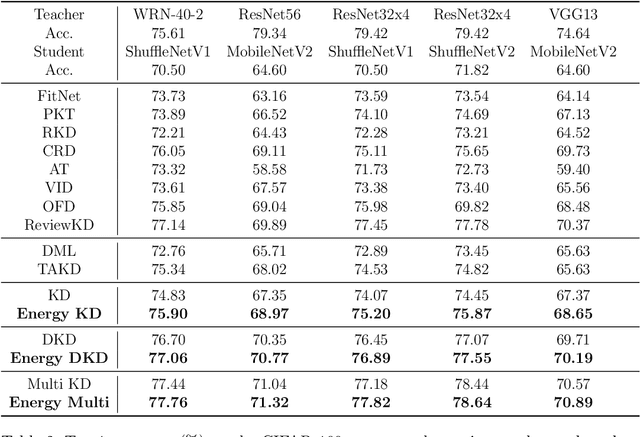
To apply the latest computer vision techniques that require a large computational cost in real industrial applications, knowledge distillation methods (KDs) are essential. Existing logit-based KDs apply the constant temperature scaling to all samples in dataset, limiting the utilization of knowledge inherent in each sample individually. In our approach, we classify the dataset into two categories (i.e., low energy and high energy samples) based on their energy score. Through experiments, we have confirmed that low energy samples exhibit high confidence scores, indicating certain predictions, while high energy samples yield low confidence scores, meaning uncertain predictions. To distill optimal knowledge by adjusting non-target class predictions, we apply a higher temperature to low energy samples to create smoother distributions and a lower temperature to high energy samples to achieve sharper distributions. When compared to previous logit-based and feature-based methods, our energy-based KD (Energy KD) achieves better performance on various datasets. Especially, Energy KD shows significant improvements on CIFAR-100-LT and ImageNet datasets, which contain many challenging samples. Furthermore, we propose high energy-based data augmentation (HE-DA) for further improving the performance. We demonstrate that meaningful performance improvement could be achieved by augmenting only 20-50% of dataset, suggesting that it can be employed on resource-limited devices. To the best of our knowledge, this paper represents the first attempt to make use of energy scores in KD and DA, and we believe it will greatly contribute to future research.