 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMR: A Large-scale Benchmark Dataset for Multi-target and Multi-granularity Reasoning Segmentation
Mar 18, 2025The fusion of Large Language Models with vision models is pioneering new possibilities in user-interactive vision-language tasks. A notable application is reasoning segmentation, where models generate pixel-level segmentation masks by comprehending implicit meanings in human instructions. However, seamless human-AI interaction demands more than just object-level recognition; it requires understanding both objects and the functions of their detailed parts, particularly in multi-target scenarios. For example, when instructing a robot to \textit{turn on the TV"}, there could be various ways to accomplish this command. Recognizing multiple objects capable of turning on the TV, such as the TV itself or a remote control (multi-target), provides more flexible options and aids in finding the optimized scenario. Furthermore, understanding specific parts of these objects, like the TV's button or the remote's button (part-level), is important for completing the action. Unfortunately, current reasoning segmentation datasets predominantly focus on a single target object-level reasoning, which limits the detailed recognition of an object's parts in multi-target contexts. To address this gap, we construct a large-scale dataset called Multi-target and Multi-granularity Reasoning (MMR). MMR comprises 194K complex and implicit instructions that consider multi-target, object-level, and part-level aspects, based on pre-existing image-mask sets. This dataset supports diverse and context-aware interactions by hierarchically providing object and part information. Moreover, we propose a straightforward yet effective framework for multi-target, object-level, and part-level reasoning segmentation. Experimental results on MMR show that the proposed method can reason effectively in multi-target and multi-granularity scenarios, while the existing reasoning segmentation model still has room for improvement.
Maximizing Discrimination Capability of Knowledge Distillation with Energy-based Score
Nov 24, 2023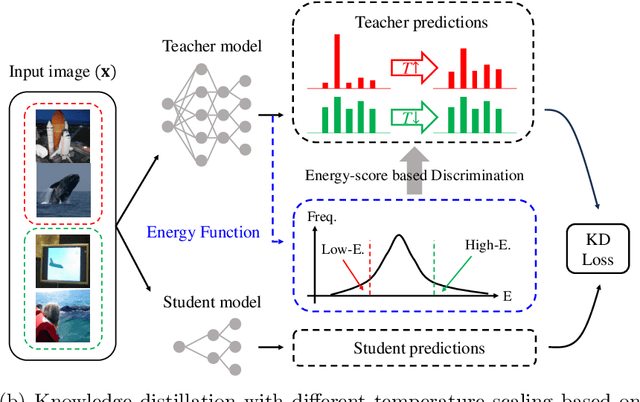
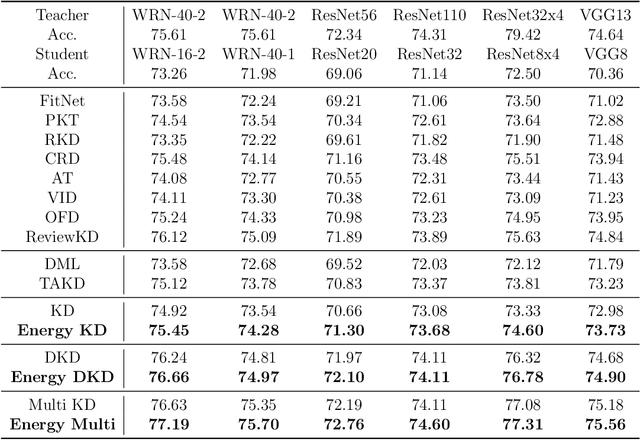
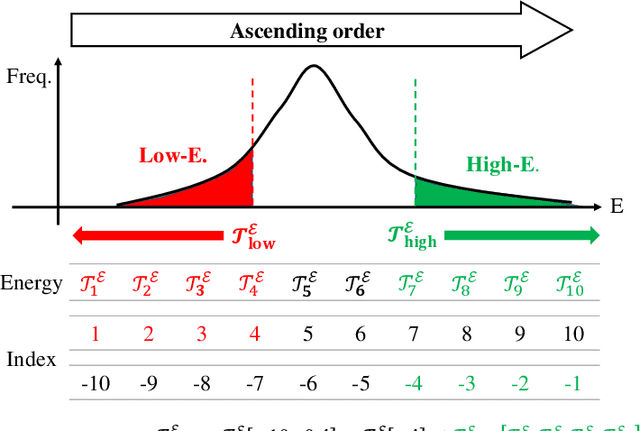
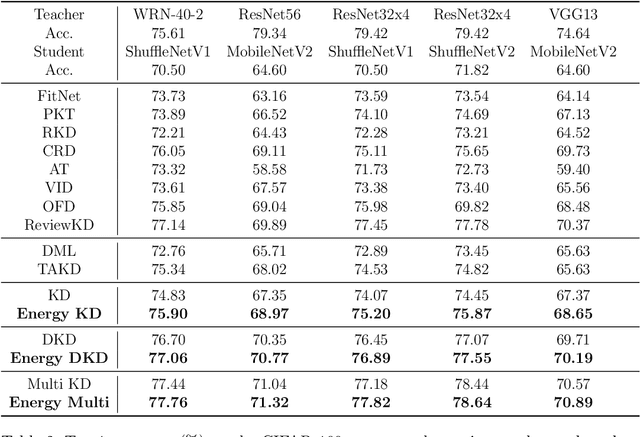
To apply the latest computer vision techniques that require a large computational cost in real industrial applications, knowledge distillation methods (KDs) are essential. Existing logit-based KDs apply the constant temperature scaling to all samples in dataset, limiting the utilization of knowledge inherent in each sample individually. In our approach, we classify the dataset into two categories (i.e., low energy and high energy samples) based on their energy score. Through experiments, we have confirmed that low energy samples exhibit high confidence scores, indicating certain predictions, while high energy samples yield low confidence scores, meaning uncertain predictions. To distill optimal knowledge by adjusting non-target class predictions, we apply a higher temperature to low energy samples to create smoother distributions and a lower temperature to high energy samples to achieve sharper distributions. When compared to previous logit-based and feature-based methods, our energy-based KD (Energy KD) achieves better performance on various datasets. Especially, Energy KD shows significant improvements on CIFAR-100-LT and ImageNet datasets, which contain many challenging samples. Furthermore, we propose high energy-based data augmentation (HE-DA) for further improving the performance. We demonstrate that meaningful performance improvement could be achieved by augmenting only 20-50% of dataset, suggesting that it can be employed on resource-limited devices. To the best of our knowledge, this paper represents the first attempt to make use of energy scores in KD and DA, and we believe it will greatly contribute to future research.
Unsupervised Image Denoising with Frequency Domain Knowledge
Nov 29, 2021
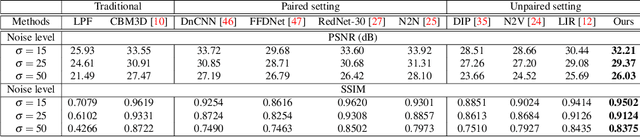
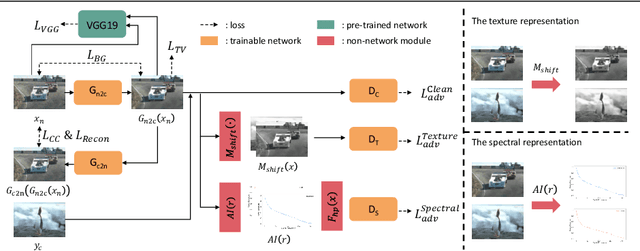

Supervised learning-based methods yield robust denoising results, yet they are inherently limited by the need for large-scale clean/noisy paired datasets. The use of unsupervised denoisers, on the other hand, necessitates a more detailed understanding of the underlying image statistics. In particular, it is well known that apparent differences between clean and noisy images are most prominent on high-frequency bands, justifying the use of low-pass filters as part of conventional image preprocessing steps. However, most learning-based denoising methods utilize only one-sided information from the spatial domain without considering frequency domain information. To address this limitation, in this study we propose a frequency-sensitive unsupervised denoising method. To this end, a generative adversarial network (GAN) is used as a base structure. Subsequently, we include spectral discriminator and frequency reconstruction loss to transfer frequency knowledge into the generator. Results using natural and synthetic datasets indicate that our unsupervised learning method augmented with frequency information achieves state-of-the-art denoising performance, suggesting that frequency domain information could be a viable factor in improving the overall performance of unsupervised learning-based methods.