 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTexTailor: Customized Text-aligned Texturing via Effective Resampling
Jun 12, 2025We present TexTailor, a novel method for generating consistent object textures from textual descriptions. Existing text-to-texture synthesis approaches utilize depth-aware diffusion models to progressively generate images and synthesize textures across predefined multiple viewpoints. However, these approaches lead to a gradual shift in texture properties across viewpoints due to (1) insufficient integration of previously synthesized textures at each viewpoint during the diffusion process and (2) the autoregressive nature of the texture synthesis process. Moreover, the predefined selection of camera positions, which does not account for the object's geometry, limits the effective use of texture information synthesized from different viewpoints, ultimately degrading overall texture consistency. In TexTailor, we address these issues by (1) applying a resampling scheme that repeatedly integrates information from previously synthesized textures within the diffusion process, and (2) fine-tuning a depth-aware diffusion model on these resampled textures. During this process, we observed that using only a few training images restricts the model's original ability to generate high-fidelity images aligned with the conditioning, and therefore propose an performance preservation loss to mitigate this issue. Additionally, we improve the synthesis of view-consistent textures by adaptively adjusting camera positions based on the object's geometry. Experiments on a subset of the Objaverse dataset and the ShapeNet car dataset demonstrate that TexTailor outperforms state-of-the-art methods in synthesizing view-consistent textures. The source code for TexTailor is available at https://github.com/Adios42/Textailor
MMR: A Large-scale Benchmark Dataset for Multi-target and Multi-granularity Reasoning Segmentation
Mar 18, 2025The fusion of Large Language Models with vision models is pioneering new possibilities in user-interactive vision-language tasks. A notable application is reasoning segmentation, where models generate pixel-level segmentation masks by comprehending implicit meanings in human instructions. However, seamless human-AI interaction demands more than just object-level recognition; it requires understanding both objects and the functions of their detailed parts, particularly in multi-target scenarios. For example, when instructing a robot to \textit{turn on the TV"}, there could be various ways to accomplish this command. Recognizing multiple objects capable of turning on the TV, such as the TV itself or a remote control (multi-target), provides more flexible options and aids in finding the optimized scenario. Furthermore, understanding specific parts of these objects, like the TV's button or the remote's button (part-level), is important for completing the action. Unfortunately, current reasoning segmentation datasets predominantly focus on a single target object-level reasoning, which limits the detailed recognition of an object's parts in multi-target contexts. To address this gap, we construct a large-scale dataset called Multi-target and Multi-granularity Reasoning (MMR). MMR comprises 194K complex and implicit instructions that consider multi-target, object-level, and part-level aspects, based on pre-existing image-mask sets. This dataset supports diverse and context-aware interactions by hierarchically providing object and part information. Moreover, we propose a straightforward yet effective framework for multi-target, object-level, and part-level reasoning segmentation. Experimental results on MMR show that the proposed method can reason effectively in multi-target and multi-granularity scenarios, while the existing reasoning segmentation model still has room for improvement.
Decoding fMRI Data into Captions using Prefix Language Modeling
Jan 05, 2025With the advancements in Large Language and Latent Diffusion models, brain decoding has achieved remarkable results in recent years. The works on the NSD dataset, with stimuli images from the COCO dataset, leverage the embeddings from the CLIP model for image reconstruction and GIT for captioning. However, the current captioning approach introduces the challenge of potential data contamination given that the GIT model was trained on the COCO dataset. In this work, we present an alternative method for decoding brain signals into image captions by predicting a DINOv2 model's embedding of an image from the corresponding fMRI signal and then providing its [CLS] token as the prefix to the GPT-2 language model which decreases computational requirements considerably. Additionally, instead of commonly used Linear Regression, we explore 3D Convolutional Neural Network mapping of fMRI signals to image embedding space for better accounting positional information of voxels.
Unsupervised Image Denoising with Frequency Domain Knowledge
Nov 29, 2021
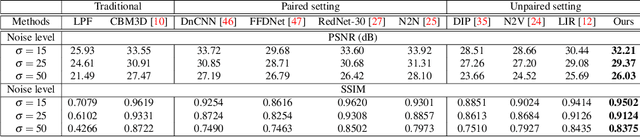
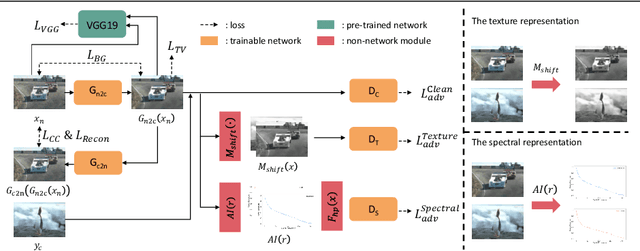

Supervised learning-based methods yield robust denoising results, yet they are inherently limited by the need for large-scale clean/noisy paired datasets. The use of unsupervised denoisers, on the other hand, necessitates a more detailed understanding of the underlying image statistics. In particular, it is well known that apparent differences between clean and noisy images are most prominent on high-frequency bands, justifying the use of low-pass filters as part of conventional image preprocessing steps. However, most learning-based denoising methods utilize only one-sided information from the spatial domain without considering frequency domain information. To address this limitation, in this study we propose a frequency-sensitive unsupervised denoising method. To this end, a generative adversarial network (GAN) is used as a base structure. Subsequently, we include spectral discriminator and frequency reconstruction loss to transfer frequency knowledge into the generator. Results using natural and synthetic datasets indicate that our unsupervised learning method augmented with frequency information achieves state-of-the-art denoising performance, suggesting that frequency domain information could be a viable factor in improving the overall performance of unsupervised learning-based methods.
Variational Mutual Information Maximization Framework for VAE Latent Codes with Continuous and Discrete Priors
Jun 02, 2020
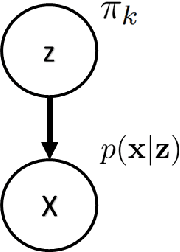

Learning interpretable and disentangled representations of data is a key topic in machine learning research. Variational Autoencoder (VAE) is a scalable method for learning directed latent variable models of complex data. It employs a clear and interpretable objective that can be easily optimized. However, this objective does not provide an explicit measure for the quality of latent variable representations which may result in their poor quality. We propose Variational Mutual Information Maximization Framework for VAE to address this issue. In comparison to other methods, it provides an explicit objective that maximizes lower bound on mutual information between latent codes and observations. The objective acts as a regularizer that forces VAE to not ignore the latent variable and allows one to select particular components of it to be most informative with respect to the observations. On top of that, the proposed framework provides a way to evaluate mutual information between latent codes and observations for a fixed VAE model. We have conducted our experiments on VAE models with Gaussian and joint Gaussian and discrete latent variables. Our results illustrate that the proposed approach strengthens relationships between latent codes and observations and improves learned representations.
VMI-VAE: Variational Mutual Information Maximization Framework for VAE With Discrete and Continuous Priors
May 28, 2020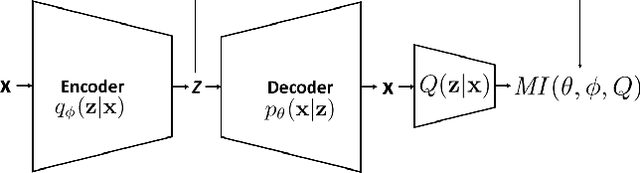



Variational Autoencoder is a scalable method for learning latent variable models of complex data. It employs a clear objective that can be easily optimized. However, it does not explicitly measure the quality of learned representations. We propose a Variational Mutual Information Maximization Framework for VAE to address this issue. It provides an objective that maximizes the mutual information between latent codes and observations. The objective acts as a regularizer that forces VAE to not ignore the latent code and allows one to select particular components of it to be most informative with respect to the observations. On top of that, the proposed framework provides a way to evaluate mutual information between latent codes and observations for a fixed VAE model.
Progressive Face Super-Resolution via Attention to Facial Landmark
Aug 22, 2019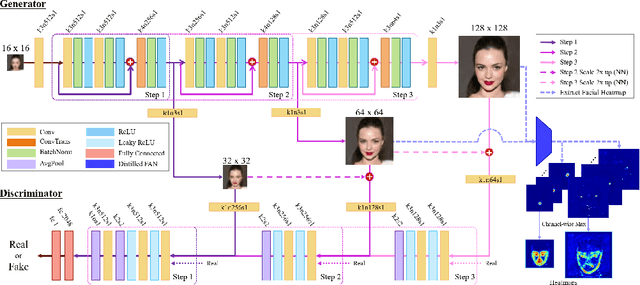

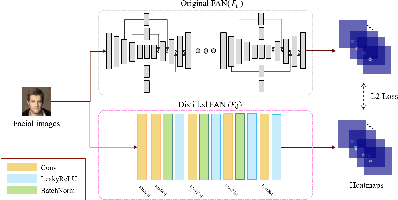

Face Super-Resolution (SR) is a subfield of the SR domain that specifically targets the reconstruction of face images. The main challenge of face SR is to restore essential facial features without distortion. We propose a novel face SR method that generates photo-realistic 8x super-resolved face images with fully retained facial details. To that end, we adopt a progressive training method, which allows stable training by splitting the network into successive steps, each producing output with a progressively higher resolution. We also propose a novel facial attention loss and apply it at each step to focus on restoring facial attributes in greater details by multiplying the pixel difference and heatmap values. Lastly, we propose a compressed version of the state-of-the-art face alignment network (FAN) for landmark heatmap extraction. With the proposed FAN, we can extract the heatmaps suitable for face SR and also reduce the overall training time. Experimental results verify that our method outperforms state-of-the-art methods in both qualitative and quantitative measurements, especially in perceptual quality.