 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowLong: Inference-time Long Video Generation via Manifold-constrained Tweedie Matching
May 20, 2026Extending the generation horizon of video diffusion models to long sequences remains a long-standing and important challenge. Existing training-free approaches fall into two categories: extensions of bidirectional models, which are tightly coupled to specific architectures and suffer from quality degradation over long horizons, and autoregressive models, which accumulate drift errors due to exposure bias and tend to produce repetitive motion patterns. To address these issues, we propose a novel but simple inference-time approach for long video generation that is architecture-agnostic and requires no additional training. Our method generates long videos via overlapping sliding windows, where predicted clean samples from adjacent windows are blended via \emph{Tweedie matching} to enforce both \textbf{manifold constraint and temporal consistency} across overlap regions. \emph{Stochastic early-phase sampling} then synchronizes per-window trajectories by injecting fresh noise after each Tweedie matching correction in the high-noise phase, before transitioning to deterministic ODE sampling to preserve fine-grained visual fidelity. Applied to various video generation models, our method generates videos several times longer than the native window length while outperforming both training-free and autoregressive baselines in temporal consistency and visual quality, and further extends to audio-video joint generation and text-to-3DGS without any fine-tuning.
TweedieMix: Improving Multi-Concept Fusion for Diffusion-based Image/Video Generation
Oct 08, 2024
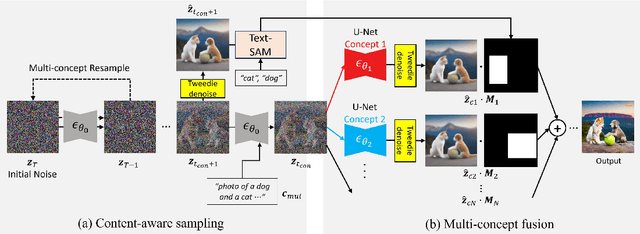

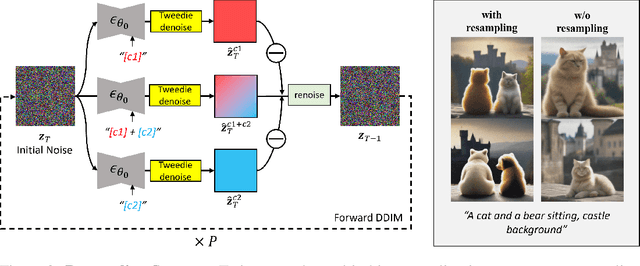
Despite significant advancements in customizing text-to-image and video generation models, generating images and videos that effectively integrate multiple personalized concepts remains a challenging task. To address this, we present TweedieMix, a novel method for composing customized diffusion models during the inference phase. By analyzing the properties of reverse diffusion sampling, our approach divides the sampling process into two stages. During the initial steps, we apply a multiple object-aware sampling technique to ensure the inclusion of the desired target objects. In the later steps, we blend the appearances of the custom concepts in the de-noised image space using Tweedie's formula. Our results demonstrate that TweedieMix can generate multiple personalized concepts with higher fidelity than existing methods. Moreover, our framework can be effortlessly extended to image-to-video diffusion models, enabling the generation of videos that feature multiple personalized concepts. Results and source code are in our anonymous project page.
Unified Editing of Panorama, 3D Scenes, and Videos Through Disentangled Self-Attention Injection
May 27, 2024



While text-to-image models have achieved impressive capabilities in image generation and editing, their application across various modalities often necessitates training separate models. Inspired by existing method of single image editing with self attention injection and video editing with shared attention, we propose a novel unified editing framework that combines the strengths of both approaches by utilizing only a basic 2D image text-to-image (T2I) diffusion model. Specifically, we design a sampling method that facilitates editing consecutive images while maintaining semantic consistency utilizing shared self-attention features during both reference and consecutive image sampling processes. Experimental results confirm that our method enables editing across diverse modalities including 3D scenes, videos, and panorama images.
Concept Weaver: Enabling Multi-Concept Fusion in Text-to-Image Models
Apr 05, 2024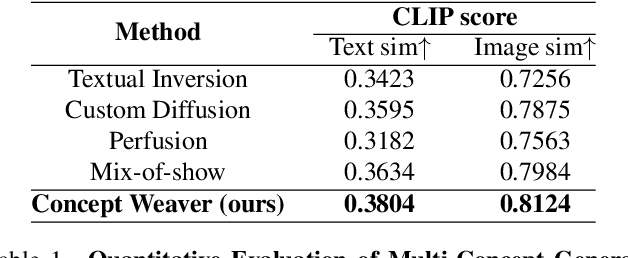
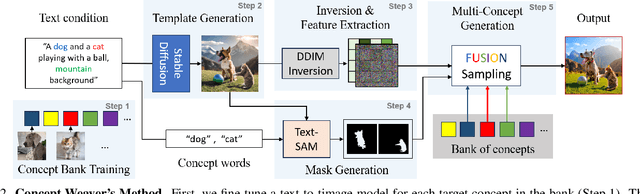
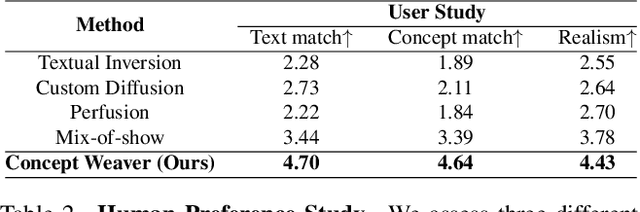
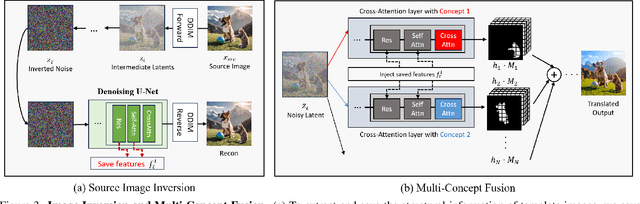
While there has been significant progress in customizing text-to-image generation models, generating images that combine multiple personalized concepts remains challenging. In this work, we introduce Concept Weaver, a method for composing customized text-to-image diffusion models at inference time. Specifically, the method breaks the process into two steps: creating a template image aligned with the semantics of input prompts, and then personalizing the template using a concept fusion strategy. The fusion strategy incorporates the appearance of the target concepts into the template image while retaining its structural details. The results indicate that our method can generate multiple custom concepts with higher identity fidelity compared to alternative approaches. Furthermore, the method is shown to seamlessly handle more than two concepts and closely follow the semantic meaning of the input prompt without blending appearances across different subjects.
Patch-wise Graph Contrastive Learning for Image Translation
Dec 13, 2023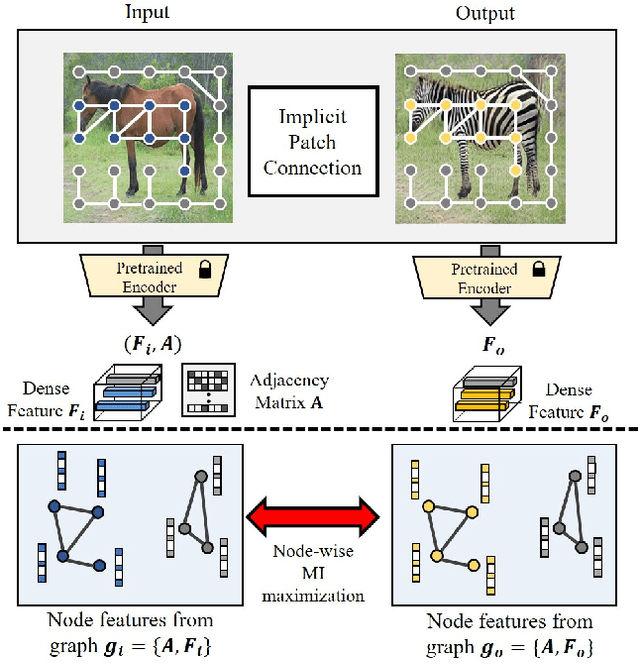
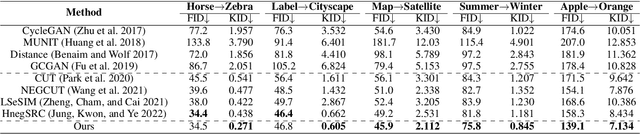
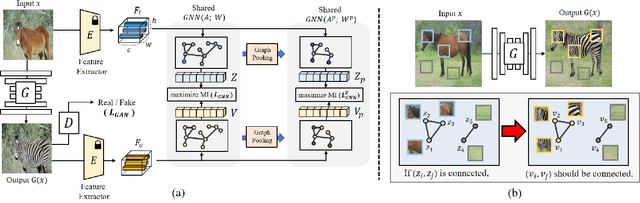
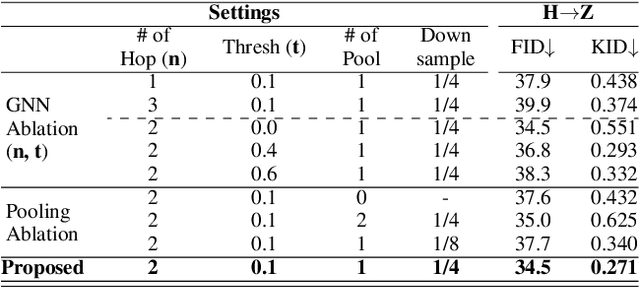
Recently, patch-wise contrastive learning is drawing attention for the image translation by exploring the semantic correspondence between the input and output images. To further explore the patch-wise topology for high-level semantic understanding, here we exploit the graph neural network to capture the topology-aware features. Specifically, we construct the graph based on the patch-wise similarity from a pretrained encoder, whose adjacency matrix is shared to enhance the consistency of patch-wise relation between the input and the output. Then, we obtain the node feature from the graph neural network, and enhance the correspondence between the nodes by increasing mutual information using the contrastive loss. In order to capture the hierarchical semantic structure, we further propose the graph pooling. Experimental results demonstrate the state-of-art results for the image translation thanks to the semantic encoding by the constructed graphs.
Contrastive Denoising Score for Text-guided Latent Diffusion Image Editing
Nov 30, 2023



With the remarkable advent of text-to-image diffusion models, image editing methods have become more diverse and continue to evolve. A promising recent approach in this realm is Delta Denoising Score (DDS) - an image editing technique based on Score Distillation Sampling (SDS) framework that leverages the rich generative prior of text-to-image diffusion models. However, relying solely on the difference between scoring functions is insufficient for preserving specific structural elements from the original image, a crucial aspect of image editing. Inspired by the similarity and importance differences between DDS and the contrastive learning for unpaired image-to-image translation (CUT), here we present an embarrassingly simple yet very powerful modification of DDS, called Contrastive Denoising Score (CDS), for latent diffusion models (LDM). Specifically, to enforce structural correspondence between the input and output while maintaining the controllability of contents, we introduce a straightforward approach to regulate structural consistency using CUT loss within the DDS framework. To calculate this loss, instead of employing auxiliary networks, we utilize the intermediate features of LDM, in particular, those from the self-attention layers, which possesses rich spatial information. Our approach enables zero-shot image-to-image translation and neural radiance field (NeRF) editing, achieving a well-balanced interplay between maintaining the structural details and transforming content. Qualitative results and comparisons demonstrates the effectiveness of our proposed method. Project page with code is available at https://hyelinnam.github.io/CDS/.
ED-NeRF: Efficient Text-Guided Editing of 3D Scene using Latent Space NeRF
Oct 04, 2023

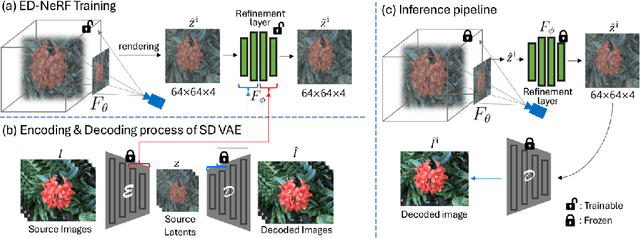

Recently, there has been a significant advancement in text-to-image diffusion models, leading to groundbreaking performance in 2D image generation. These advancements have been extended to 3D models, enabling the generation of novel 3D objects from textual descriptions. This has evolved into NeRF editing methods, which allow the manipulation of existing 3D objects through textual conditioning. However, existing NeRF editing techniques have faced limitations in their performance due to slow training speeds and the use of loss functions that do not adequately consider editing. To address this, here we present a novel 3D NeRF editing approach dubbed ED-NeRF by successfully embedding real-world scenes into the latent space of the latent diffusion model (LDM) through a unique refinement layer. This approach enables us to obtain a NeRF backbone that is not only faster but also more amenable to editing compared to traditional image space NeRF editing. Furthermore, we propose an improved loss function tailored for editing by migrating the delta denoising score (DDS) distillation loss, originally used in 2D image editing to the three-dimensional domain. This novel loss function surpasses the well-known score distillation sampling (SDS) loss in terms of suitability for editing purposes. Our experimental results demonstrate that ED-NeRF achieves faster editing speed while producing improved output quality compared to state-of-the-art 3D editing models.
Improving Diffusion-based Image Translation using Asymmetric Gradient Guidance
Jun 07, 2023Diffusion models have shown significant progress in image translation tasks recently. However, due to their stochastic nature, there's often a trade-off between style transformation and content preservation. Current strategies aim to disentangle style and content, preserving the source image's structure while successfully transitioning from a source to a target domain under text or one-shot image conditions. Yet, these methods often require computationally intense fine-tuning of diffusion models or additional neural networks. To address these challenges, here we present an approach that guides the reverse process of diffusion sampling by applying asymmetric gradient guidance. This results in quicker and more stable image manipulation for both text-guided and image-guided image translation. Our model's adaptability allows it to be implemented with both image- and latent-diffusion models. Experiments show that our method outperforms various state-of-the-art models in image translation tasks.
Unpaired Image-to-Image Translation via Neural Schrödinger Bridge
May 24, 2023Diffusion models are a powerful class of generative models which simulate stochastic differential equations (SDEs) to generate data from noise. Although diffusion models have achieved remarkable progress in recent years, they have limitations in the unpaired image-to-image translation tasks due to the Gaussian prior assumption. Schr\"odinger Bridge (SB), which learns an SDE to translate between two arbitrary distributions, have risen as an attractive solution to this problem. However, none of SB models so far have been successful at unpaired translation between high-resolution images. In this work, we propose the Unpaired Neural Schr\"odinger Bridge (UNSB), which combines SB with adversarial training and regularization to learn a SB between unpaired data. We demonstrate that UNSB is scalable, and that it successfully solves various unpaired image-to-image translation tasks. Code: \url{https://github.com/cyclomon/UNSB}
Zero-shot Generation of Coherent Storybook from Plain Text Story using Diffusion Models
Feb 08, 2023Recent advancements in large scale text-to-image models have opened new possibilities for guiding the creation of images through human-devised natural language. However, while prior literature has primarily focused on the generation of individual images, it is essential to consider the capability of these models to ensure coherency within a sequence of images to fulfill the demands of real-world applications such as storytelling. To address this, here we present a novel neural pipeline for generating a coherent storybook from the plain text of a story. Specifically, we leverage a combination of a pre-trained Large Language Model and a text-guided Latent Diffusion Model to generate coherent images. While previous story synthesis frameworks typically require a large-scale text-to-image model trained on expensive image-caption pairs to maintain the coherency, we employ simple textual inversion techniques along with detector-based semantic image editing which allows zero-shot generation of the coherent storybook. Experimental results show that our proposed method outperforms state-of-the-art image editing baselines.