 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero4D: Training-Free 4D Video Generation From Single Video Using Off-the-Shelf Video Diffusion Model
Mar 28, 2025



Recently, multi-view or 4D video generation has emerged as a significant research topic. Nonetheless, recent approaches to 4D generation still struggle with fundamental limitations, as they primarily rely on harnessing multiple video diffusion models with additional training or compute-intensive training of a full 4D diffusion model with limited real-world 4D data and large computational costs. To address these challenges, here we propose the first training-free 4D video generation method that leverages the off-the-shelf video diffusion models to generate multi-view videos from a single input video. Our approach consists of two key steps: (1) By designating the edge frames in the spatio-temporal sampling grid as key frames, we first synthesize them using a video diffusion model, leveraging a depth-based warping technique for guidance. This approach ensures structural consistency across the generated frames, preserving spatial and temporal coherence. (2) We then interpolate the remaining frames using a video diffusion model, constructing a fully populated and temporally coherent sampling grid while preserving spatial and temporal consistency. Through this approach, we extend a single video into a multi-view video along novel camera trajectories while maintaining spatio-temporal consistency. Our method is training-free and fully utilizes an off-the-shelf video diffusion model, offering a practical and effective solution for multi-view video generation.
Unified Editing of Panorama, 3D Scenes, and Videos Through Disentangled Self-Attention Injection
May 27, 2024



While text-to-image models have achieved impressive capabilities in image generation and editing, their application across various modalities often necessitates training separate models. Inspired by existing method of single image editing with self attention injection and video editing with shared attention, we propose a novel unified editing framework that combines the strengths of both approaches by utilizing only a basic 2D image text-to-image (T2I) diffusion model. Specifically, we design a sampling method that facilitates editing consecutive images while maintaining semantic consistency utilizing shared self-attention features during both reference and consecutive image sampling processes. Experimental results confirm that our method enables editing across diverse modalities including 3D scenes, videos, and panorama images.
ED-NeRF: Efficient Text-Guided Editing of 3D Scene using Latent Space NeRF
Oct 04, 2023

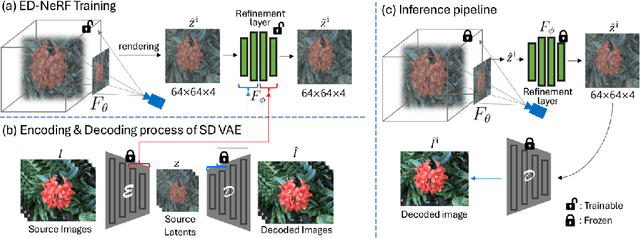

Recently, there has been a significant advancement in text-to-image diffusion models, leading to groundbreaking performance in 2D image generation. These advancements have been extended to 3D models, enabling the generation of novel 3D objects from textual descriptions. This has evolved into NeRF editing methods, which allow the manipulation of existing 3D objects through textual conditioning. However, existing NeRF editing techniques have faced limitations in their performance due to slow training speeds and the use of loss functions that do not adequately consider editing. To address this, here we present a novel 3D NeRF editing approach dubbed ED-NeRF by successfully embedding real-world scenes into the latent space of the latent diffusion model (LDM) through a unique refinement layer. This approach enables us to obtain a NeRF backbone that is not only faster but also more amenable to editing compared to traditional image space NeRF editing. Furthermore, we propose an improved loss function tailored for editing by migrating the delta denoising score (DDS) distillation loss, originally used in 2D image editing to the three-dimensional domain. This novel loss function surpasses the well-known score distillation sampling (SDS) loss in terms of suitability for editing purposes. Our experimental results demonstrate that ED-NeRF achieves faster editing speed while producing improved output quality compared to state-of-the-art 3D editing models.
Long-Term Missing Value Imputation for Time Series Data Using Deep Neural Networks
Feb 25, 2022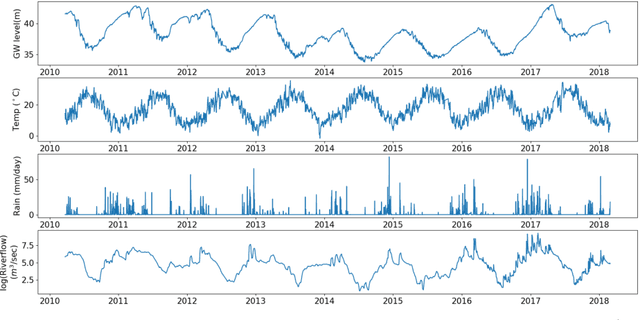
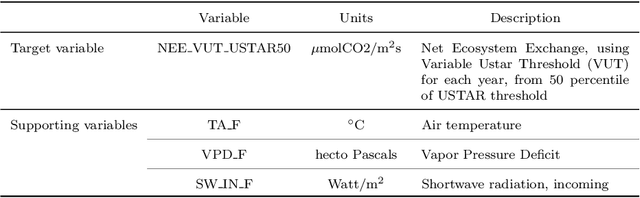
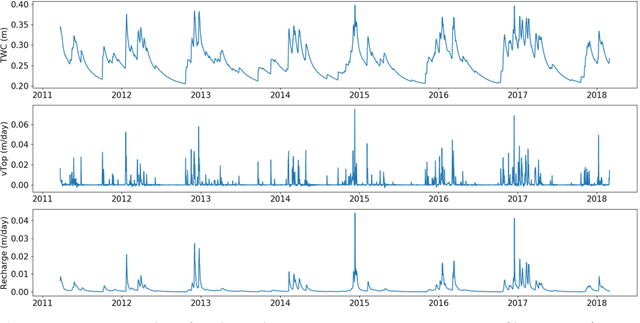
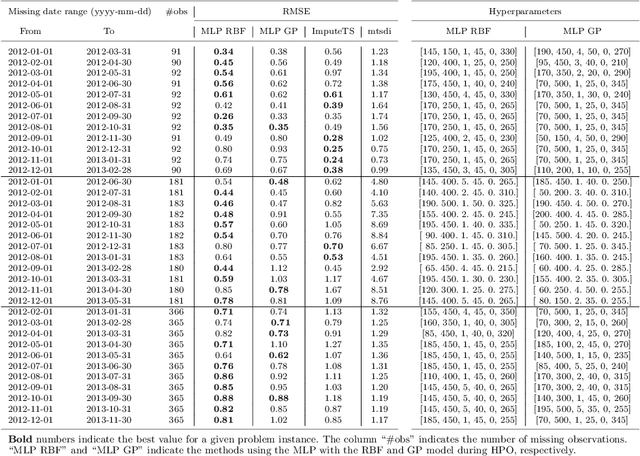
We present an approach that uses a deep learning model, in particular, a MultiLayer Perceptron (MLP), for estimating the missing values of a variable in multivariate time series data. We focus on filling a long continuous gap (e.g., multiple months of missing daily observations) rather than on individual randomly missing observations. Our proposed gap filling algorithm uses an automated method for determining the optimal MLP model architecture, thus allowing for optimal prediction performance for the given time series. We tested our approach by filling gaps of various lengths (three months to three years) in three environmental datasets with different time series characteristics, namely daily groundwater levels, daily soil moisture, and hourly Net Ecosystem Exchange. We compared the accuracy of the gap-filled values obtained with our approach to the widely-used R-based time series gap filling methods ImputeTS and mtsdi. The results indicate that using an MLP for filling a large gap leads to better results, especially when the data behave nonlinearly. Thus, our approach enables the use of datasets that have a large gap in one variable, which is common in many long-term environmental monitoring observations.
Surrogate Optimization of Deep Neural Networks for Groundwater Predictions
Aug 30, 2019
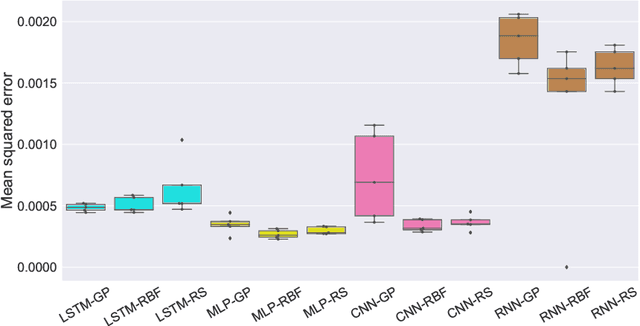
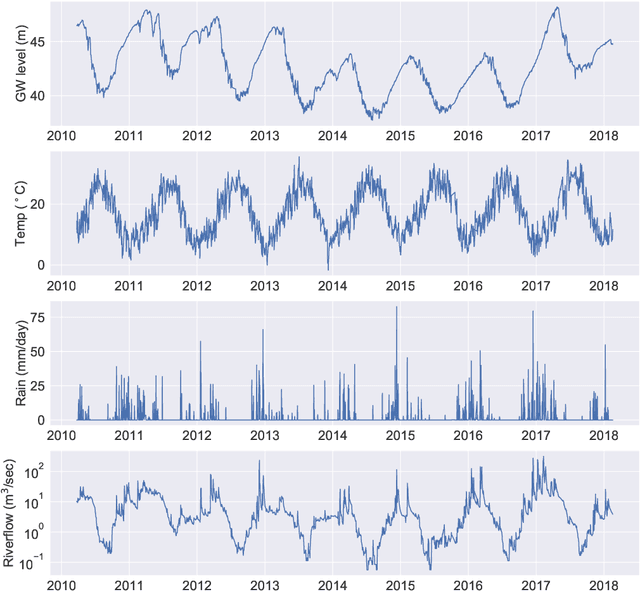
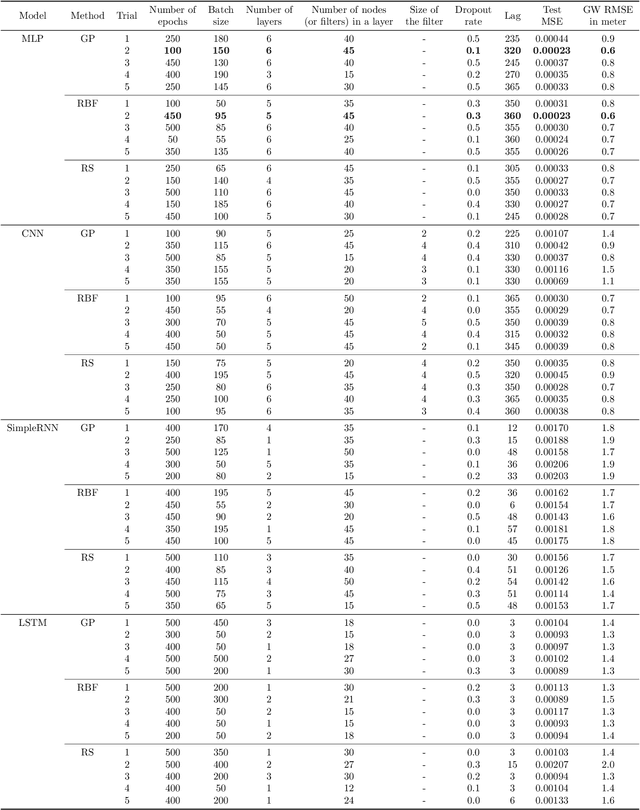
Sustainable management of groundwater resources under changing climatic conditions require an application of reliable and accurate predictions of groundwater levels. Mechanistic multi-scale, multi-physics simulation models are often too hard to use for this purpose, especially for groundwater managers who do not have access to the complex compute resources and data. Therefore, we analyzed the applicability and performance of four modern deep learning computational models for predictions of groundwater levels. We compare three methods for optimizing the models' hyperparameters, including two surrogate model-based algorithms and a random sampling method. The models were tested using predictions of the groundwater level in Butte County, California, USA, taking into account the temporal variability of streamflow, precipitation, and ambient temperature. Our numerical study shows that the optimization of the hyperparameters can lead to reasonably accurate performance of all models, but the "simplest" network, namely a multilayer perceptron (MLP) performs overall better for learning and predicting groundwater data than the more advanced long short-term memory or convolutional neural networks in terms of prediction accuracy and time-to-solution, making the MLP a suitable candidate for groundwater prediction.