 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReviving ConvNeXt for Efficient Convolutional Diffusion Models
Mar 10, 2026Recent diffusion models increasingly favor Transformer backbones, motivated by the remarkable scalability of fully attentional architectures. Yet the locality bias, parameter efficiency, and hardware friendliness--the attributes that established ConvNets as the efficient vision backbone--have seen limited exploration in modern generative modeling. Here we introduce the fully convolutional diffusion model (FCDM), a model having a backbone similar to ConvNeXt, but designed for conditional diffusion modeling. We find that using only 50% of the FLOPs of DiT-XL/2, FCDM-XL achieves competitive performance with 7$\times$ and 7.5$\times$ fewer training steps at 256$\times$256 and 512$\times$512 resolutions, respectively. Remarkably, FCDM-XL can be trained on a 4-GPU system, highlighting the exceptional training efficiency of our architecture. Our results demonstrate that modern convolutional designs provide a competitive and highly efficient alternative for scaling diffusion models, reviving ConvNeXt as a simple yet powerful building block for efficient generative modeling.
Zero4D: Training-Free 4D Video Generation From Single Video Using Off-the-Shelf Video Diffusion Model
Mar 28, 2025



Recently, multi-view or 4D video generation has emerged as a significant research topic. Nonetheless, recent approaches to 4D generation still struggle with fundamental limitations, as they primarily rely on harnessing multiple video diffusion models with additional training or compute-intensive training of a full 4D diffusion model with limited real-world 4D data and large computational costs. To address these challenges, here we propose the first training-free 4D video generation method that leverages the off-the-shelf video diffusion models to generate multi-view videos from a single input video. Our approach consists of two key steps: (1) By designating the edge frames in the spatio-temporal sampling grid as key frames, we first synthesize them using a video diffusion model, leveraging a depth-based warping technique for guidance. This approach ensures structural consistency across the generated frames, preserving spatial and temporal coherence. (2) We then interpolate the remaining frames using a video diffusion model, constructing a fully populated and temporally coherent sampling grid while preserving spatial and temporal consistency. Through this approach, we extend a single video into a multi-view video along novel camera trajectories while maintaining spatio-temporal consistency. Our method is training-free and fully utilizes an off-the-shelf video diffusion model, offering a practical and effective solution for multi-view video generation.
VISION-XL: High Definition Video Inverse Problem Solver using Latent Image Diffusion Models
Dec 03, 2024



In this paper, we propose a novel framework for solving high-definition video inverse problems using latent image diffusion models. Building on recent advancements in spatio-temporal optimization for video inverse problems using image diffusion models, our approach leverages latent-space diffusion models to achieve enhanced video quality and resolution. To address the high computational demands of processing high-resolution frames, we introduce a pseudo-batch consistent sampling strategy, allowing efficient operation on a single GPU. Additionally, to improve temporal consistency, we present batch-consistent inversion, an initialization technique that incorporates informative latents from the measurement frame. By integrating with SDXL, our framework achieves state-of-the-art video reconstruction across a wide range of spatio-temporal inverse problems, including complex combinations of frame averaging and various spatial degradations, such as deblurring, super-resolution, and inpainting. Unlike previous methods, our approach supports multiple aspect ratios (landscape, vertical, and square) and delivers HD-resolution reconstructions (exceeding 1280x720) in under 2.5 minutes on a single NVIDIA 4090 GPU.
ViBiDSampler: Enhancing Video Interpolation Using Bidirectional Diffusion Sampler
Oct 08, 2024Recent progress in large-scale text-to-video (T2V) and image-to-video (I2V) diffusion models has greatly enhanced video generation, especially in terms of keyframe interpolation. However, current image-to-video diffusion models, while powerful in generating videos from a single conditioning frame, need adaptation for two-frame (start & end) conditioned generation, which is essential for effective bounded interpolation. Unfortunately, existing approaches that fuse temporally forward and backward paths in parallel often suffer from off-manifold issues, leading to artifacts or requiring multiple iterative re-noising steps. In this work, we introduce a novel, bidirectional sampling strategy to address these off-manifold issues without requiring extensive re-noising or fine-tuning. Our method employs sequential sampling along both forward and backward paths, conditioned on the start and end frames, respectively, ensuring more coherent and on-manifold generation of intermediate frames. Additionally, we incorporate advanced guidance techniques, CFG++ and DDS, to further enhance the interpolation process. By integrating these, our method achieves state-of-the-art performance, efficiently generating high-quality, smooth videos between keyframes. On a single 3090 GPU, our method can interpolate 25 frames at 1024 x 576 resolution in just 195 seconds, establishing it as a leading solution for keyframe interpolation.
Solving Video Inverse Problems Using Image Diffusion Models
Sep 04, 2024



Recently, diffusion model-based inverse problem solvers (DIS) have emerged as state-of-the-art approaches for addressing inverse problems, including image super-resolution, deblurring, inpainting, etc. However, their application to video inverse problems arising from spatio-temporal degradation remains largely unexplored due to the challenges in training video diffusion models. To address this issue, here we introduce an innovative video inverse solver that leverages only image diffusion models. Specifically, by drawing inspiration from the success of the recent decomposed diffusion sampler (DDS), our method treats the time dimension of a video as the batch dimension of image diffusion models and solves spatio-temporal optimization problems within denoised spatio-temporal batches derived from each image diffusion model. Moreover, we introduce a batch-consistent diffusion sampling strategy that encourages consistency across batches by synchronizing the stochastic noise components in image diffusion models. Our approach synergistically combines batch-consistent sampling with simultaneous optimization of denoised spatio-temporal batches at each reverse diffusion step, resulting in a novel and efficient diffusion sampling strategy for video inverse problems. Experimental results demonstrate that our method effectively addresses various spatio-temporal degradations in video inverse problems, achieving state-of-the-art reconstructions. Project page: https://solving-video-inverse.github.io/main/
Highly Personalized Text Embedding for Image Manipulation by Stable Diffusion
Mar 15, 2023



Diffusion models have shown superior performance in image generation and manipulation, but the inherent stochasticity presents challenges in preserving and manipulating image content and identity. While previous approaches like DreamBooth and Textual Inversion have proposed model or latent representation personalization to maintain the content, their reliance on multiple reference images and complex training limits their practicality. In this paper, we present a simple yet highly effective approach to personalization using highly personalized (HiPer) text embedding by decomposing the CLIP embedding space for personalization and content manipulation. Our method does not require model fine-tuning or identifiers, yet still enables manipulation of background, texture, and motion with just a single image and target text. Through experiments on diverse target texts, we demonstrate that our approach produces highly personalized and complex semantic image edits across a wide range of tasks. We believe that the novel understanding of the text embedding space presented in this work has the potential to inspire further research across various tasks.
Noise Distribution Adaptive Self-Supervised Image Denoising using Tweedie Distribution and Score Matching
Dec 05, 2021
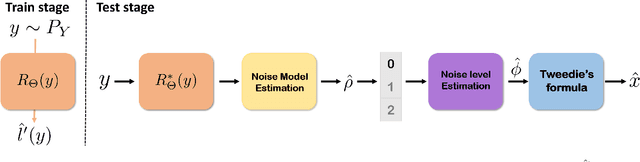
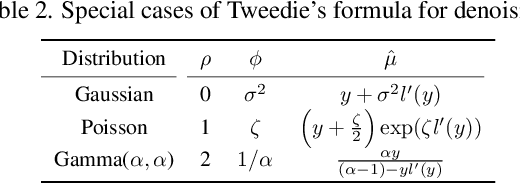

Tweedie distributions are a special case of exponential dispersion models, which are often used in classical statistics as distributions for generalized linear models. Here, we reveal that Tweedie distributions also play key roles in modern deep learning era, leading to a distribution independent self-supervised image denoising formula without clean reference images. Specifically, by combining with the recent Noise2Score self-supervised image denoising approach and the saddle point approximation of Tweedie distribution, we can provide a general closed-form denoising formula that can be used for large classes of noise distributions without ever knowing the underlying noise distribution. Similar to the original Noise2Score, the new approach is composed of two successive steps: score matching using perturbed noisy images, followed by a closed form image denoising formula via distribution-independent Tweedie's formula. This also suggests a systematic algorithm to estimate the noise model and noise parameters for a given noisy image data set. Through extensive experiments, we demonstrate that the proposed method can accurately estimate noise models and parameters, and provide the state-of-the-art self-supervised image denoising performance in the benchmark dataset and real-world dataset.
Cycle-free CycleGAN using Invertible Generator for Unsupervised Low-Dose CT Denoising
Apr 17, 2021



Recently, CycleGAN was shown to provide high-performance, ultra-fast denoising for low-dose X-ray computed tomography (CT) without the need for a paired training dataset. Although this was possible thanks to cycle consistency, CycleGAN requires two generators and two discriminators to enforce cycle consistency, demanding significant GPU resources and technical skills for training. A recent proposal of tunable CycleGAN with Adaptive Instance Normalization (AdaIN) alleviates the problem in part by using a single generator. However, two discriminators and an additional AdaIN code generator are still required for training. To solve this problem, here we present a novel cycle-free Cycle-GAN architecture, which consists of a single generator and a discriminator but still guarantees cycle consistency. The main innovation comes from the observation that the use of an invertible generator automatically fulfills the cycle consistency condition and eliminates the additional discriminator in the CycleGAN formulation. To make the invertible generator more effective, our network is implemented in the wavelet residual domain. Extensive experiments using various levels of low-dose CT images confirm that our method can significantly improve denoising performance using only 10% of learnable parameters and faster training time compared to the conventional CycleGAN.