 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMindFormer: A Transformer Architecture for Multi-Subject Brain Decoding via fMRI
May 28, 2024Research efforts to understand neural signals have been ongoing for many years, with visual decoding from fMRI signals attracting considerable attention. Particularly, the advent of image diffusion models has advanced the reconstruction of images from fMRI data significantly. However, existing approaches often introduce inter- and intra- subject variations in the reconstructed images, which can compromise accuracy. To address current limitations in multi-subject brain decoding, we introduce a new Transformer architecture called MindFormer. This model is specifically designed to generate fMRI-conditioned feature vectors that can be used for conditioning Stable Diffusion model. More specifically, MindFormer incorporates two key innovations: 1) a novel training strategy based on the IP-Adapter to extract semantically meaningful features from fMRI signals, and 2) a subject specific token and linear layer that effectively capture individual differences in fMRI signals while synergistically combines multi subject fMRI data for training. Our experimental results demonstrate that Stable Diffusion, when integrated with MindFormer, produces semantically consistent images across different subjects. This capability significantly surpasses existing models in multi-subject brain decoding. Such advancements not only improve the accuracy of our reconstructions but also deepen our understanding of neural processing variations among individuals.
Highly Personalized Text Embedding for Image Manipulation by Stable Diffusion
Mar 15, 2023



Diffusion models have shown superior performance in image generation and manipulation, but the inherent stochasticity presents challenges in preserving and manipulating image content and identity. While previous approaches like DreamBooth and Textual Inversion have proposed model or latent representation personalization to maintain the content, their reliance on multiple reference images and complex training limits their practicality. In this paper, we present a simple yet highly effective approach to personalization using highly personalized (HiPer) text embedding by decomposing the CLIP embedding space for personalization and content manipulation. Our method does not require model fine-tuning or identifiers, yet still enables manipulation of background, texture, and motion with just a single image and target text. Through experiments on diverse target texts, we demonstrate that our approach produces highly personalized and complex semantic image edits across a wide range of tasks. We believe that the novel understanding of the text embedding space presented in this work has the potential to inspire further research across various tasks.
DiffuseMorph: Unsupervised Deformable Image Registration Along Continuous Trajectory Using Diffusion Models
Dec 09, 2021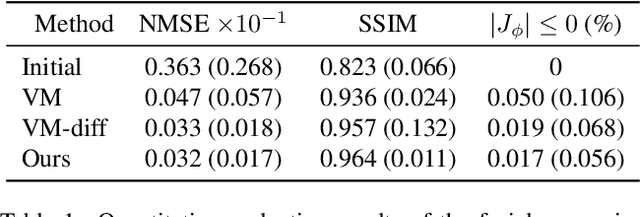
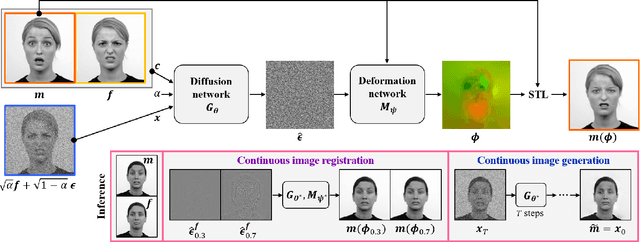
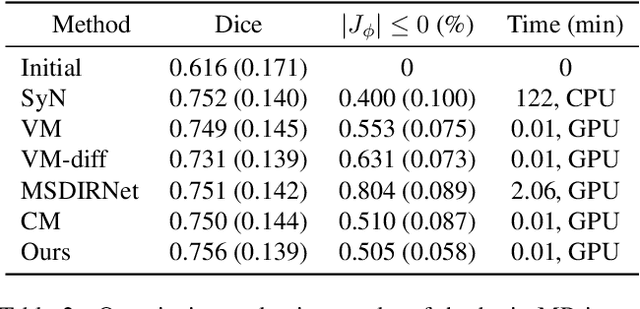
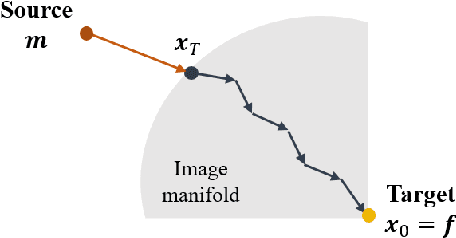
Deformable image registration is one of the fundamental tasks for medical imaging and computer vision. Classical registration algorithms usually rely on iterative optimization approaches to provide accurate deformation, which requires high computational cost. Although many deep-learning-based methods have been developed to carry out fast image registration, it is still challenging to estimate the deformation field with less topological folding problem. Furthermore, these approaches only enable registration to a single fixed image, and it is not possible to obtain continuously varying registration results between the moving and fixed images. To address this, here we present a novel approach of diffusion model-based probabilistic image registration, called DiffuseMorph. Specifically, our model learns the score function of the deformation between moving and fixed images. Similar to the existing diffusion models, DiffuseMorph not only provides synthetic deformed images through a reverse diffusion process, but also enables various levels of deformation of the moving image along with the latent space. Experimental results on 2D face expression image and 3D brain image registration tasks demonstrate that our method can provide flexible and accurate deformation with a capability of topology preservation.