 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-V2V: Augmenting Video-to-Video Diffusion Models with Memory
Jan 22, 2026Recent foundational video-to-video diffusion models have achieved impressive results in editing user provided videos by modifying appearance, motion, or camera movement. However, real-world video editing is often an iterative process, where users refine results across multiple rounds of interaction. In this multi-turn setting, current video editors struggle to maintain cross-consistency across sequential edits. In this work, we tackle, for the first time, the problem of cross-consistency in multi-turn video editing and introduce Memory-V2V, a simple, yet effective framework that augments existing video-to-video models with explicit memory. Given an external cache of previously edited videos, Memory-V2V employs accurate retrieval and dynamic tokenization strategies to condition the current editing step on prior results. To further mitigate redundancy and computational overhead, we propose a learnable token compressor within the DiT backbone that compresses redundant conditioning tokens while preserving essential visual cues, achieving an overall speedup of 30%. We validate Memory-V2V on challenging tasks including video novel view synthesis and text-conditioned long video editing. Extensive experiments show that Memory-V2V produces videos that are significantly more cross-consistent with minimal computational overhead, while maintaining or even improving task-specific performance over state-of-the-art baselines. Project page: https://dohunlee1.github.io/MemoryV2V
SpaceTimePilot: Generative Rendering of Dynamic Scenes Across Space and Time
Dec 31, 2025We present SpaceTimePilot, a video diffusion model that disentangles space and time for controllable generative rendering. Given a monocular video, SpaceTimePilot can independently alter the camera viewpoint and the motion sequence within the generative process, re-rendering the scene for continuous and arbitrary exploration across space and time. To achieve this, we introduce an effective animation time-embedding mechanism in the diffusion process, allowing explicit control of the output video's motion sequence with respect to that of the source video. As no datasets provide paired videos of the same dynamic scene with continuous temporal variations, we propose a simple yet effective temporal-warping training scheme that repurposes existing multi-view datasets to mimic temporal differences. This strategy effectively supervises the model to learn temporal control and achieve robust space-time disentanglement. To further enhance the precision of dual control, we introduce two additional components: an improved camera-conditioning mechanism that allows altering the camera from the first frame, and CamxTime, the first synthetic space-and-time full-coverage rendering dataset that provides fully free space-time video trajectories within a scene. Joint training on the temporal-warping scheme and the CamxTime dataset yields more precise temporal control. We evaluate SpaceTimePilot on both real-world and synthetic data, demonstrating clear space-time disentanglement and strong results compared to prior work. Project page: https://zheninghuang.github.io/Space-Time-Pilot/ Code: https://github.com/ZheningHuang/spacetimepilot
Improving Video Diffusion Transformer Training by Multi-Feature Fusion and Alignment from Self-Supervised Vision Encoders
Sep 11, 2025



Video diffusion models have advanced rapidly in the recent years as a result of series of architectural innovations (e.g., diffusion transformers) and use of novel training objectives (e.g., flow matching). In contrast, less attention has been paid to improving the feature representation power of such models. In this work, we show that training video diffusion models can benefit from aligning the intermediate features of the video generator with feature representations of pre-trained vision encoders. We propose a new metric and conduct an in-depth analysis of various vision encoders to evaluate their discriminability and temporal consistency, thereby assessing their suitability for video feature alignment. Based on the analysis, we present Align4Gen which provides a novel multi-feature fusion and alignment method integrated into video diffusion model training. We evaluate Align4Gen both for unconditional and class-conditional video generation tasks and show that it results in improved video generation as quantified by various metrics. Full video results are available on our project page: https://align4gen.github.io/align4gen/
Reangle-A-Video: 4D Video Generation as Video-to-Video Translation
Mar 12, 2025



We introduce Reangle-A-Video, a unified framework for generating synchronized multi-view videos from a single input video. Unlike mainstream approaches that train multi-view video diffusion models on large-scale 4D datasets, our method reframes the multi-view video generation task as video-to-videos translation, leveraging publicly available image and video diffusion priors. In essence, Reangle-A-Video operates in two stages. (1) Multi-View Motion Learning: An image-to-video diffusion transformer is synchronously fine-tuned in a self-supervised manner to distill view-invariant motion from a set of warped videos. (2) Multi-View Consistent Image-to-Images Translation: The first frame of the input video is warped and inpainted into various camera perspectives under an inference-time cross-view consistency guidance using DUSt3R, generating multi-view consistent starting images. Extensive experiments on static view transport and dynamic camera control show that Reangle-A-Video surpasses existing methods, establishing a new solution for multi-view video generation. We will publicly release our code and data. Project page: https://hyeonho99.github.io/reangle-a-video/
On Unifying Video Generation and Camera Pose Estimation
Jan 02, 2025



Inspired by the emergent 3D capabilities in image generators, we explore whether video generators similarly exhibit 3D awareness. Using structure-from-motion (SfM) as a benchmark for 3D tasks, we investigate if intermediate features from OpenSora, a video generation model, can support camera pose estimation. We first examine native 3D awareness in video generation features by routing raw intermediate outputs to SfM-prediction modules like DUSt3R. Then, we explore the impact of fine-tuning on camera pose estimation to enhance 3D awareness. Results indicate that while video generator features have limited inherent 3D awareness, task-specific supervision significantly boosts their accuracy for camera pose estimation, resulting in competitive performance. The proposed unified model, named JOG3R, produces camera pose estimates with competitive quality without degrading video generation quality.
Track4Gen: Teaching Video Diffusion Models to Track Points Improves Video Generation
Dec 10, 2024While recent foundational video generators produce visually rich output, they still struggle with appearance drift, where objects gradually degrade or change inconsistently across frames, breaking visual coherence. We hypothesize that this is because there is no explicit supervision in terms of spatial tracking at the feature level. We propose Track4Gen, a spatially aware video generator that combines video diffusion loss with point tracking across frames, providing enhanced spatial supervision on the diffusion features. Track4Gen merges the video generation and point tracking tasks into a single network by making minimal changes to existing video generation architectures. Using Stable Video Diffusion as a backbone, Track4Gen demonstrates that it is possible to unify video generation and point tracking, which are typically handled as separate tasks. Our extensive evaluations show that Track4Gen effectively reduces appearance drift, resulting in temporally stable and visually coherent video generation. Project page: hyeonho99.github.io/track4gen
Spectral Motion Alignment for Video Motion Transfer using Diffusion Models
Mar 22, 2024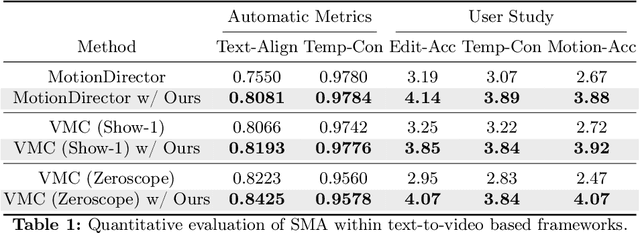
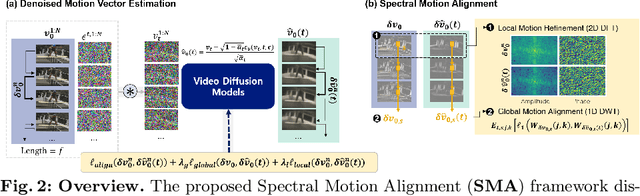
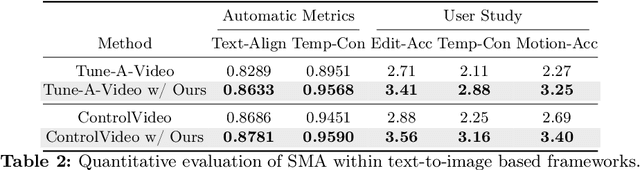

The evolution of diffusion models has greatly impacted video generation and understanding. Particularly, text-to-video diffusion models (VDMs) have significantly facilitated the customization of input video with target appearance, motion, etc. Despite these advances, challenges persist in accurately distilling motion information from video frames. While existing works leverage the consecutive frame residual as the target motion vector, they inherently lack global motion context and are vulnerable to frame-wise distortions. To address this, we present Spectral Motion Alignment (SMA), a novel framework that refines and aligns motion vectors using Fourier and wavelet transforms. SMA learns motion patterns by incorporating frequency-domain regularization, facilitating the learning of whole-frame global motion dynamics, and mitigating spatial artifacts. Extensive experiments demonstrate SMA's efficacy in improving motion transfer while maintaining computational efficiency and compatibility across various video customization frameworks.
DreamMotion: Space-Time Self-Similarity Score Distillation for Zero-Shot Video Editing
Mar 18, 2024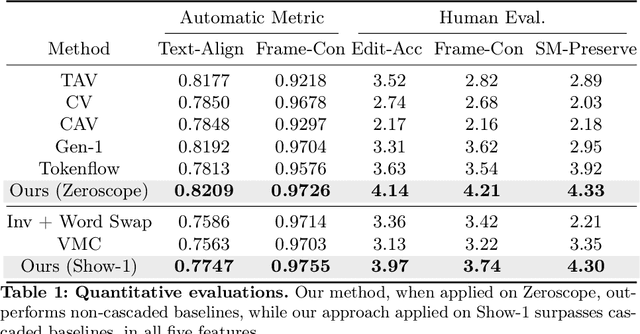


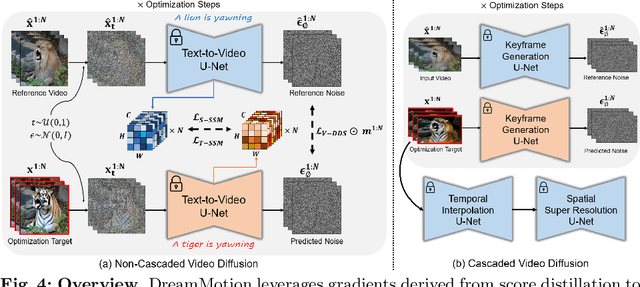
Text-driven diffusion-based video editing presents a unique challenge not encountered in image editing literature: establishing real-world motion. Unlike existing video editing approaches, here we focus on score distillation sampling to circumvent the standard reverse diffusion process and initiate optimization from videos that already exhibit natural motion. Our analysis reveals that while video score distillation can effectively introduce new content indicated by target text, it can also cause significant structure and motion deviation. To counteract this, we propose to match space-time self-similarities of the original video and the edited video during the score distillation. Thanks to the use of score distillation, our approach is model-agnostic, which can be applied for both cascaded and non-cascaded video diffusion frameworks. Through extensive comparisons with leading methods, our approach demonstrates its superiority in altering appearances while accurately preserving the original structure and motion.
VMC: Video Motion Customization using Temporal Attention Adaption for Text-to-Video Diffusion Models
Dec 01, 2023Text-to-video diffusion models have advanced video generation significantly. However, customizing these models to generate videos with tailored motions presents a substantial challenge. In specific, they encounter hurdles in (a) accurately reproducing motion from a target video, and (b) creating diverse visual variations. For example, straightforward extensions of static image customization methods to video often lead to intricate entanglements of appearance and motion data. To tackle this, here we present the Video Motion Customization (VMC) framework, a novel one-shot tuning approach crafted to adapt temporal attention layers within video diffusion models. Our approach introduces a novel motion distillation objective using residual vectors between consecutive frames as a motion reference. The diffusion process then preserves low-frequency motion trajectories while mitigating high-frequency motion-unrelated noise in image space. We validate our method against state-of-the-art video generative models across diverse real-world motions and contexts. Our codes, data and the project demo can be found at https://video-motion-customization.github.io
Ground-A-Video: Zero-shot Grounded Video Editing using Text-to-image Diffusion Models
Oct 02, 2023Recent endeavors in video editing have showcased promising results in single-attribute editing or style transfer tasks, either by training text-to-video (T2V) models on text-video data or adopting training-free methods. However, when confronted with the complexities of multi-attribute editing scenarios, they exhibit shortcomings such as omitting or overlooking intended attribute changes, modifying the wrong elements of the input video, and failing to preserve regions of the input video that should remain intact. To address this, here we present a novel grounding-guided video-to-video translation framework called Ground-A-Video for multi-attribute video editing. Ground-A-Video attains temporally consistent multi-attribute editing of input videos in a training-free manner without aforementioned shortcomings. Central to our method is the introduction of Cross-Frame Gated Attention which incorporates groundings information into the latent representations in a temporally consistent fashion, along with Modulated Cross-Attention and optical flow guided inverted latents smoothing. Extensive experiments and applications demonstrate that Ground-A-Video's zero-shot capacity outperforms other baseline methods in terms of edit-accuracy and frame consistency. Further results and codes are provided at our project page (http://ground-a-video.github.io).