 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Language Prompting to Ease False Positives in Medical Anomaly Detection
Nov 12, 2024A pre-trained visual-language model, contrastive language-image pre-training (CLIP), successfully accomplishes various downstream tasks with text prompts, such as finding images or localizing regions within the image. Despite CLIP's strong multi-modal data capabilities, it remains limited in specialized environments, such as medical applications. For this purpose, many CLIP variants-i.e., BioMedCLIP, and MedCLIP-SAMv2-have emerged, but false positives related to normal regions persist. Thus, we aim to present a simple yet important goal of reducing false positives in medical anomaly detection. We introduce a Contrastive LAnguage Prompting (CLAP) method that leverages both positive and negative text prompts. This straightforward approach identifies potential lesion regions by visual attention to the positive prompts in the given image. To reduce false positives, we attenuate attention on normal regions using negative prompts. Extensive experiments with the BMAD dataset, including six biomedical benchmarks, demonstrate that CLAP method enhances anomaly detection performance. Our future plans include developing an automated fine prompting method for more practical usage.
Feature Attenuation of Defective Representation Can Resolve Incomplete Masking on Anomaly Detection
Jul 05, 2024
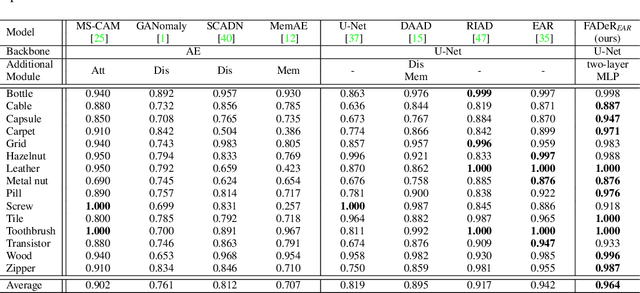
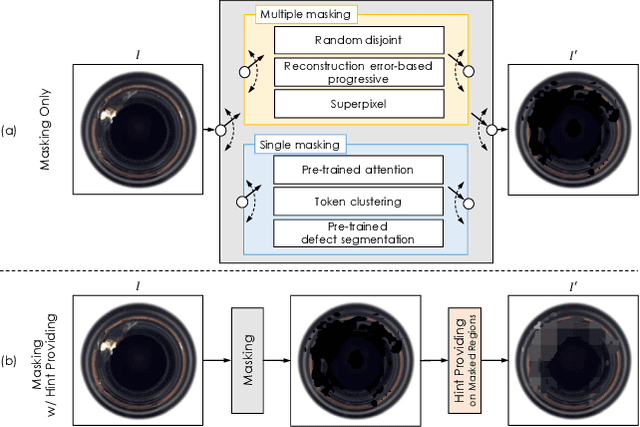

In unsupervised anomaly detection (UAD) research, while state-of-the-art models have reached a saturation point with extensive studies on public benchmark datasets, they adopt large-scale tailor-made neural networks (NN) for detection performance or pursued unified models for various tasks. Towards edge computing, it is necessary to develop a computationally efficient and scalable solution that avoids large-scale complex NNs. Motivated by this, we aim to optimize the UAD performance with minimal changes to NN settings. Thus, we revisit the reconstruction-by-inpainting approach and rethink to improve it by analyzing strengths and weaknesses. The strength of the SOTA methods is a single deterministic masking approach that addresses the challenges of random multiple masking that is inference latency and output inconsistency. Nevertheless, the issue of failure to provide a mask to completely cover anomalous regions is a remaining weakness. To mitigate this issue, we propose Feature Attenuation of Defective Representation (FADeR) that only employs two MLP layers which attenuates feature information of anomaly reconstruction during decoding. By leveraging FADeR, features of unseen anomaly patterns are reconstructed into seen normal patterns, reducing false alarms. Experimental results demonstrate that FADeR achieves enhanced performance compared to similar-scale NNs. Furthermore, our approach exhibits scalability in performance enhancement when integrated with other single deterministic masking methods in a plug-and-play manner.
Excision and Recovery: Enhancing Surface Anomaly Detection with Attention-based Single Deterministic Masking
Oct 06, 2023Anomaly detection (AD) in surface inspection is an essential yet challenging task in manufacturing due to the quantity imbalance problem of scarce abnormal data. To overcome the above, a reconstruction encoder-decoder (ED) such as autoencoder or U-Net which is trained with only anomaly-free samples is widely adopted, in the hope that unseen abnormals should yield a larger reconstruction error than normal. Over the past years, researches on self-supervised reconstruction-by-inpainting have been reported. They mask out suspected defective regions for inpainting in order to make them invisible to the reconstruction ED to deliberately cause inaccurate reconstruction for abnormals. However, their limitation is multiple random masking to cover the whole input image due to defective regions not being known in advance. We propose a novel reconstruction-by-inpainting method dubbed Excision and Recovery (EAR) that features single deterministic masking. For this, we exploit a pre-trained spatial attention model to predict potential suspected defective regions that should be masked out. We also employ a variant of U-Net as our ED to further limit the reconstruction ability of the U-Net model for abnormals, in which skip connections of different layers can be selectively disabled. In the training phase, all the skip connections are switched on to fully take the benefits from the U-Net architecture. In contrast, for inferencing, we only keep deeper skip connections with shallower connections off. We validate the effectiveness of EAR using an MNIST pre-trained attention for a commonly used surface AD dataset, KolektorSDD2. The experimental results show that EAR achieves both better AD performance and higher throughput than state-of-the-art methods. We expect that the proposed EAR model can be widely adopted as training and inference strategies for AD purposes.
Neural Network Training Strategy to Enhance Anomaly Detection Performance: A Perspective on Reconstruction Loss Amplification
Aug 28, 2023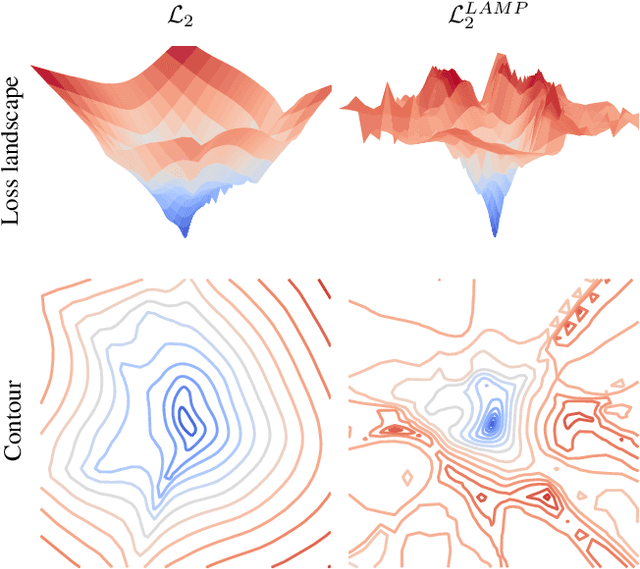
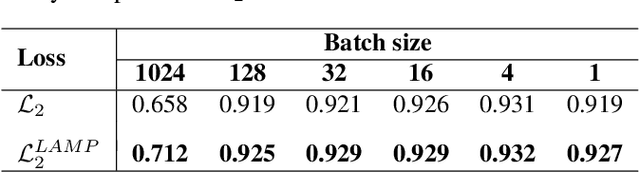
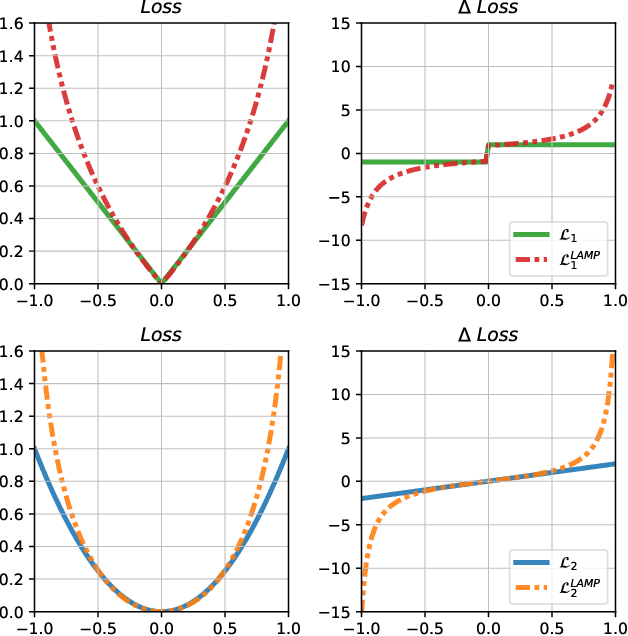
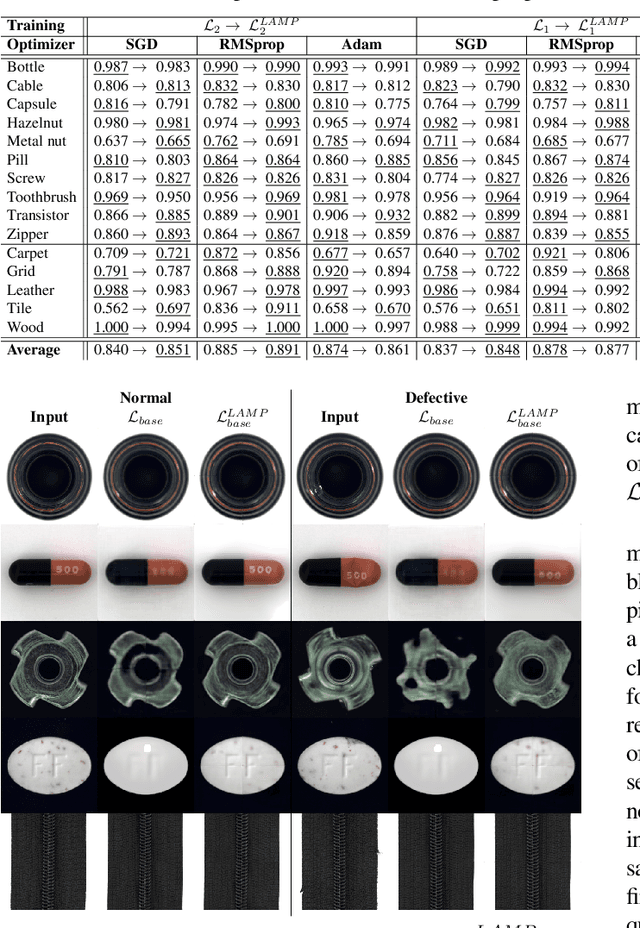
Unsupervised anomaly detection (UAD) is a widely adopted approach in industry due to rare anomaly occurrences and data imbalance. A desirable characteristic of an UAD model is contained generalization ability which excels in the reconstruction of seen normal patterns but struggles with unseen anomalies. Recent studies have pursued to contain the generalization capability of their UAD models in reconstruction from different perspectives, such as design of neural network (NN) structure and training strategy. In contrast, we note that containing of generalization ability in reconstruction can also be obtained simply from steep-shaped loss landscape. Motivated by this, we propose a loss landscape sharpening method by amplifying the reconstruction loss, dubbed Loss AMPlification (LAMP). LAMP deforms the loss landscape into a steep shape so the reconstruction error on unseen anomalies becomes greater. Accordingly, the anomaly detection performance is improved without any change of the NN architecture. Our findings suggest that LAMP can be easily applied to any reconstruction error metrics in UAD settings where the reconstruction model is trained with anomaly-free samples only.
Edge Storage Management Recipe with Zero-Shot Data Compression for Road Anomaly Detection
Jul 10, 2023Recent studies show edge computing-based road anomaly detection systems which may also conduct data collection simultaneously. However, the edge computers will have small data storage but we need to store the collected audio samples for a long time in order to update existing models or develop a novel method. Therefore, we should consider an approach for efficient storage management methods while preserving high-fidelity audio. A hardware-perspective approach, such as using a low-resolution microphone, is an intuitive way to reduce file size but is not recommended because it fundamentally cuts off high-frequency components. On the other hand, a computational file compression approach that encodes collected high-resolution audio into a compact code should be recommended because it also provides a corresponding decoding method. Motivated by this, we propose a way of simple yet effective pre-trained autoencoder-based data compression method. The pre-trained autoencoder is trained for the purpose of audio super-resolution so it can be utilized to encode or decode any arbitrary sampling rate. Moreover, it will reduce the communication cost for data transmission from the edge to the central server. Via the comparative experiments, we confirm that the zero-shot audio compression and decompression highly preserve anomaly detection performance while enhancing storage and transmission efficiency.
Noise Reduction and Driving Event Extraction Method for Performance Improvement on Driving Noise-based Surface Anomaly Detection
Dec 14, 2021
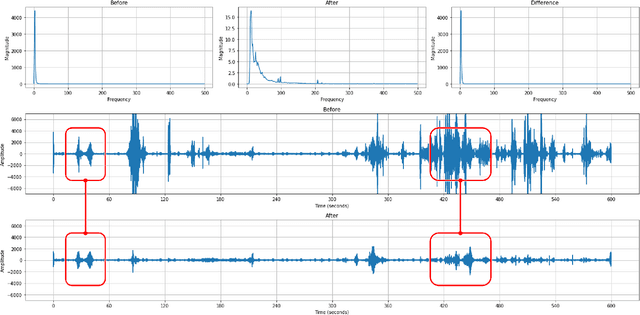
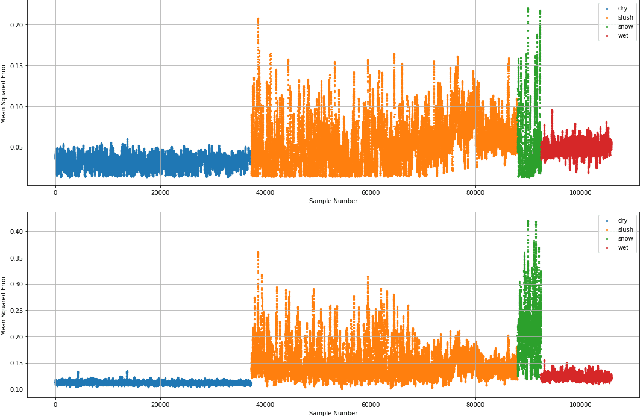

Foreign substances on the road surface, such as rainwater or black ice, reduce the friction between the tire and the surface. The above situation will reduce the braking performance and make difficult to control the vehicle body posture. In that case, there is a possibility of property damage at least. In the worst case, personal damage will be occured. To avoid this problem, a road anomaly detection model is proposed based on vehicle driving noise. However, the prior proposal does not consider the extra noise, mixed with driving noise, and skipping calculations for moments without vehicle driving. In this paper, we propose a simple driving event extraction method and noise reduction method for improving computational efficiency and anomaly detection performance.