 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly Detection by Effectively Leveraging Synthetic Images
Dec 29, 2025Anomaly detection plays a vital role in industrial manufacturing. Due to the scarcity of real defect images, unsupervised approaches that rely solely on normal images have been extensively studied. Recently, diffusion-based generative models brought attention to training data synthesis as an alternative solution. In this work, we focus on a strategy to effectively leverage synthetic images to maximize the anomaly detection performance. Previous synthesis strategies are broadly categorized into two groups, presenting a clear trade-off. Rule-based synthesis, such as injecting noise or pasting patches, is cost-effective but often fails to produce realistic defect images. On the other hand, generative model-based synthesis can create high-quality defect images but requires substantial cost. To address this problem, we propose a novel framework that leverages a pre-trained text-guided image-to-image translation model and image retrieval model to efficiently generate synthetic defect images. Specifically, the image retrieval model assesses the similarity of the generated images to real normal images and filters out irrelevant outputs, thereby enhancing the quality and relevance of the generated defect images. To effectively leverage synthetic images, we also introduce a two stage training strategy. In this strategy, the model is first pre-trained on a large volume of images from rule-based synthesis and then fine-tuned on a smaller set of high-quality images. This method significantly reduces the cost for data collection while improving the anomaly detection performance. Experiments on the MVTec AD dataset demonstrate the effectiveness of our approach.
Scene Depth Estimation from Traditional Oriental Landscape Paintings
Mar 07, 2024Scene depth estimation from paintings can streamline the process of 3D sculpture creation so that visually impaired people appreciate the paintings with tactile sense. However, measuring depth of oriental landscape painting images is extremely challenging due to its unique method of depicting depth and poor preservation. To address the problem of scene depth estimation from oriental landscape painting images, we propose a novel framework that consists of two-step Image-to-Image translation method with CLIP-based image matching at the front end to predict the real scene image that best matches with the given oriental landscape painting image. Then, we employ a pre-trained SOTA depth estimation model for the generated real scene image. In the first step, CycleGAN converts an oriental landscape painting image into a pseudo-real scene image. We utilize CLIP to semantically match landscape photo images with an oriental landscape painting image for training CycleGAN in an unsupervised manner. Then, the pseudo-real scene image and oriental landscape painting image are fed into DiffuseIT to predict a final real scene image in the second step. Finally, we measure depth of the generated real scene image using a pre-trained depth estimation model such as MiDaS. Experimental results show that our approach performs well enough to predict real scene images corresponding to oriental landscape painting images. To the best of our knowledge, this is the first study to measure the depth of oriental landscape painting images. Our research potentially assists visually impaired people in experiencing paintings in diverse ways. We will release our code and resulting dataset.
Unsupervised Sim-to-Real Adaptation of Soft Robot Proprioception using a Dual Cross-modal Autoencoder
Oct 21, 2023Soft robotics is a modern robotic paradigm for performing dexterous interactions with the surroundings via morphological flexibility. The desire for autonomous operation requires soft robots to be capable of proprioception and makes it necessary to devise a calibration process. These requirements can be greatly benefited by adopting numerical simulation for computational efficiency. However, the gap between the simulated and real domains limits the accurate, generalized application of the approach. Herein, we propose an unsupervised domain adaptation framework as a data-efficient, generalized alignment of these heterogeneous sensor domains. A dual cross-modal autoencoder was designed to match the sensor domains at a feature level without any extensive labeling process, facilitating the computationally efficient transferability to various tasks. As a proof-of-concept, the methodology was adopted to the famous soft robot design, a multigait soft robot, and two fundamental perception tasks for autonomous robot operation, involving high-fidelity shape estimation and collision detection. The resulting perception demonstrates the digital-twinned calibration process in both the simulated and real domains. The proposed design outperforms the existing prevalent benchmarks for both perception tasks. This unsupervised framework envisions a new approach to imparting embodied intelligence to soft robotic systems via blending simulation.
Neural Network Training Strategy to Enhance Anomaly Detection Performance: A Perspective on Reconstruction Loss Amplification
Aug 28, 2023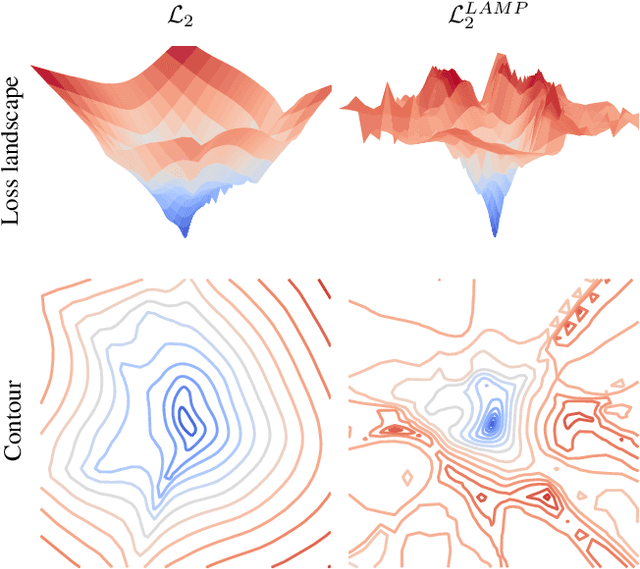
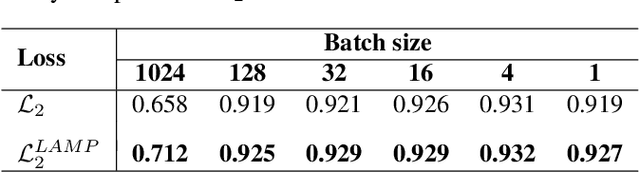
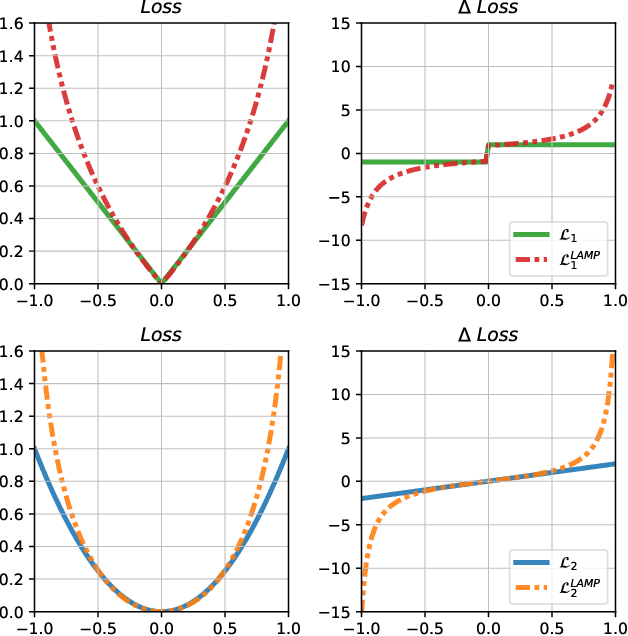
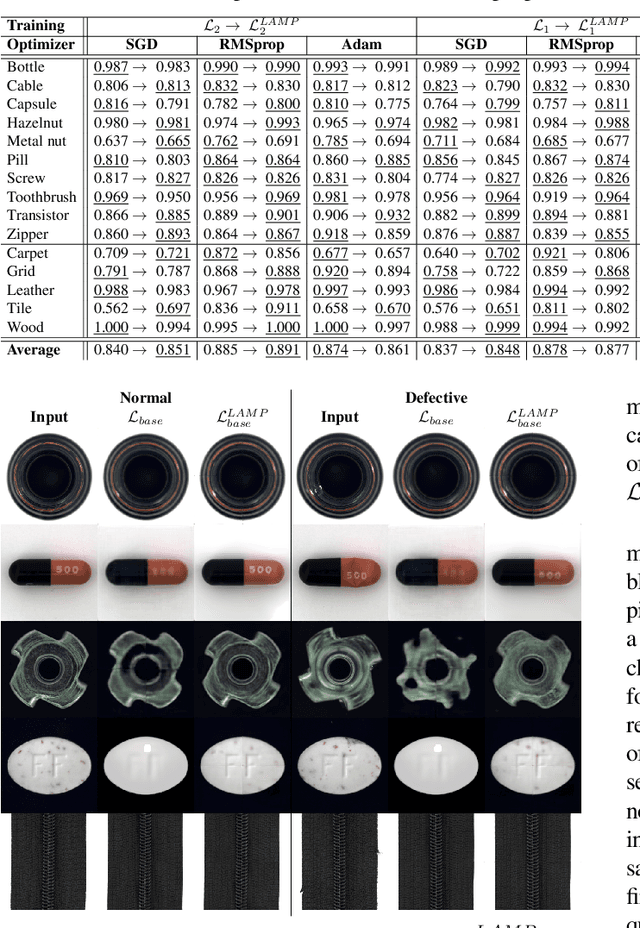
Unsupervised anomaly detection (UAD) is a widely adopted approach in industry due to rare anomaly occurrences and data imbalance. A desirable characteristic of an UAD model is contained generalization ability which excels in the reconstruction of seen normal patterns but struggles with unseen anomalies. Recent studies have pursued to contain the generalization capability of their UAD models in reconstruction from different perspectives, such as design of neural network (NN) structure and training strategy. In contrast, we note that containing of generalization ability in reconstruction can also be obtained simply from steep-shaped loss landscape. Motivated by this, we propose a loss landscape sharpening method by amplifying the reconstruction loss, dubbed Loss AMPlification (LAMP). LAMP deforms the loss landscape into a steep shape so the reconstruction error on unseen anomalies becomes greater. Accordingly, the anomaly detection performance is improved without any change of the NN architecture. Our findings suggest that LAMP can be easily applied to any reconstruction error metrics in UAD settings where the reconstruction model is trained with anomaly-free samples only.
Face Photo-Sketch Recognition Using Bidirectional Collaborative Synthesis Network
Aug 23, 2021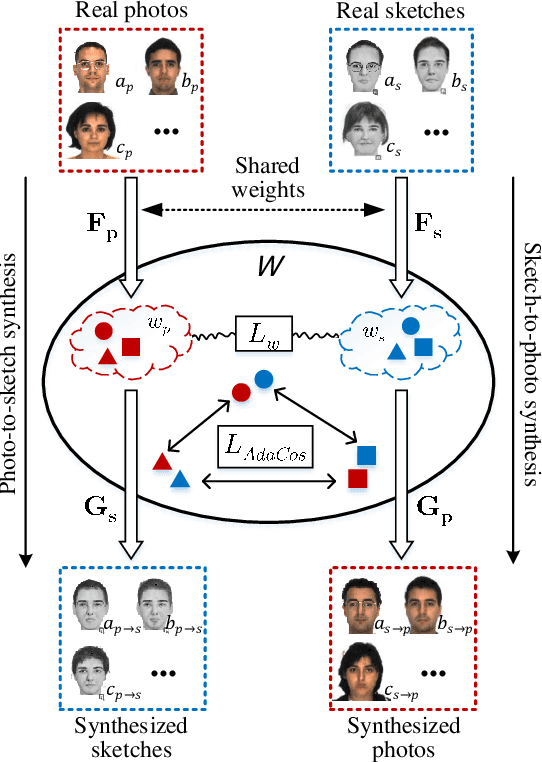

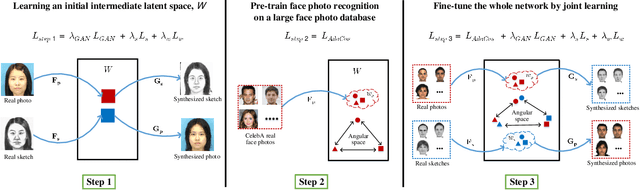

This research features a deep-learning based framework to address the problem of matching a given face sketch image against a face photo database. The problem of photo-sketch matching is challenging because 1) there is large modality gap between photo and sketch, and 2) the number of paired training samples is insufficient to train deep learning based networks. To circumvent the problem of large modality gap, our approach is to use an intermediate latent space between the two modalities. We effectively align the distributions of the two modalities in this latent space by employing a bidirectional (photo -> sketch and sketch -> photo) collaborative synthesis network. A StyleGAN-like architecture is utilized to make the intermediate latent space be equipped with rich representation power. To resolve the problem of insufficient training samples, we introduce a three-step training scheme. Extensive evaluation on public composite face sketch database confirms superior performance of our method compared to existing state-of-the-art methods. The proposed methodology can be employed in matching other modality pairs.