 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace Photo-Sketch Recognition Using Bidirectional Collaborative Synthesis Network
Paper and Code
Aug 23, 2021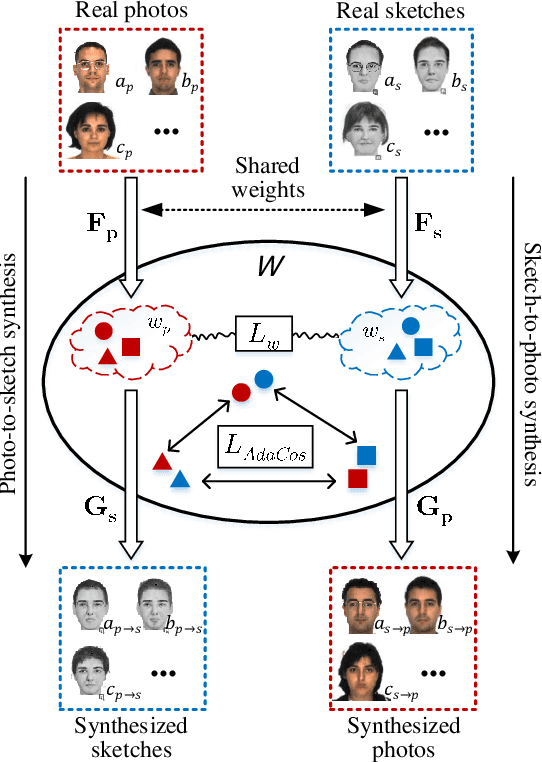

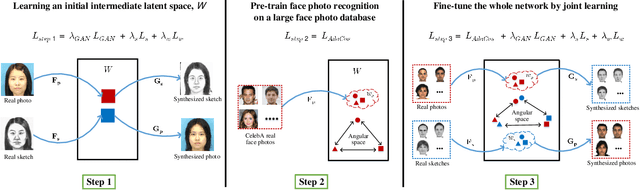

This research features a deep-learning based framework to address the problem of matching a given face sketch image against a face photo database. The problem of photo-sketch matching is challenging because 1) there is large modality gap between photo and sketch, and 2) the number of paired training samples is insufficient to train deep learning based networks. To circumvent the problem of large modality gap, our approach is to use an intermediate latent space between the two modalities. We effectively align the distributions of the two modalities in this latent space by employing a bidirectional (photo -> sketch and sketch -> photo) collaborative synthesis network. A StyleGAN-like architecture is utilized to make the intermediate latent space be equipped with rich representation power. To resolve the problem of insufficient training samples, we introduce a three-step training scheme. Extensive evaluation on public composite face sketch database confirms superior performance of our method compared to existing state-of-the-art methods. The proposed methodology can be employed in matching other modality pairs.