 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly Detection by Effectively Leveraging Synthetic Images
Dec 29, 2025Anomaly detection plays a vital role in industrial manufacturing. Due to the scarcity of real defect images, unsupervised approaches that rely solely on normal images have been extensively studied. Recently, diffusion-based generative models brought attention to training data synthesis as an alternative solution. In this work, we focus on a strategy to effectively leverage synthetic images to maximize the anomaly detection performance. Previous synthesis strategies are broadly categorized into two groups, presenting a clear trade-off. Rule-based synthesis, such as injecting noise or pasting patches, is cost-effective but often fails to produce realistic defect images. On the other hand, generative model-based synthesis can create high-quality defect images but requires substantial cost. To address this problem, we propose a novel framework that leverages a pre-trained text-guided image-to-image translation model and image retrieval model to efficiently generate synthetic defect images. Specifically, the image retrieval model assesses the similarity of the generated images to real normal images and filters out irrelevant outputs, thereby enhancing the quality and relevance of the generated defect images. To effectively leverage synthetic images, we also introduce a two stage training strategy. In this strategy, the model is first pre-trained on a large volume of images from rule-based synthesis and then fine-tuned on a smaller set of high-quality images. This method significantly reduces the cost for data collection while improving the anomaly detection performance. Experiments on the MVTec AD dataset demonstrate the effectiveness of our approach.
Contrastive Language Prompting to Ease False Positives in Medical Anomaly Detection
Nov 12, 2024A pre-trained visual-language model, contrastive language-image pre-training (CLIP), successfully accomplishes various downstream tasks with text prompts, such as finding images or localizing regions within the image. Despite CLIP's strong multi-modal data capabilities, it remains limited in specialized environments, such as medical applications. For this purpose, many CLIP variants-i.e., BioMedCLIP, and MedCLIP-SAMv2-have emerged, but false positives related to normal regions persist. Thus, we aim to present a simple yet important goal of reducing false positives in medical anomaly detection. We introduce a Contrastive LAnguage Prompting (CLAP) method that leverages both positive and negative text prompts. This straightforward approach identifies potential lesion regions by visual attention to the positive prompts in the given image. To reduce false positives, we attenuate attention on normal regions using negative prompts. Extensive experiments with the BMAD dataset, including six biomedical benchmarks, demonstrate that CLAP method enhances anomaly detection performance. Our future plans include developing an automated fine prompting method for more practical usage.
Feature Attenuation of Defective Representation Can Resolve Incomplete Masking on Anomaly Detection
Jul 05, 2024
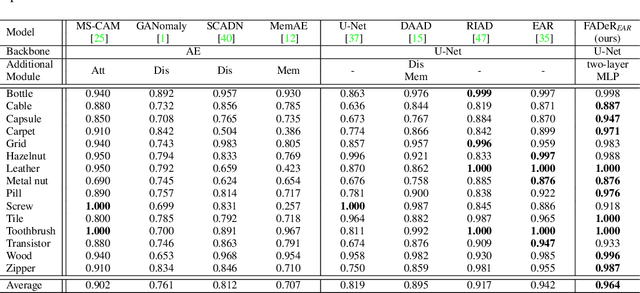
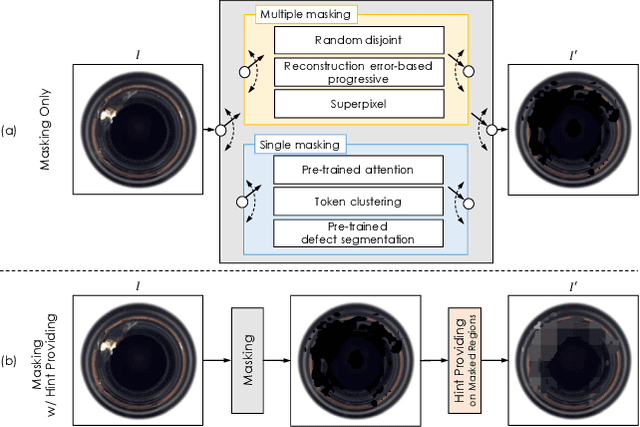

In unsupervised anomaly detection (UAD) research, while state-of-the-art models have reached a saturation point with extensive studies on public benchmark datasets, they adopt large-scale tailor-made neural networks (NN) for detection performance or pursued unified models for various tasks. Towards edge computing, it is necessary to develop a computationally efficient and scalable solution that avoids large-scale complex NNs. Motivated by this, we aim to optimize the UAD performance with minimal changes to NN settings. Thus, we revisit the reconstruction-by-inpainting approach and rethink to improve it by analyzing strengths and weaknesses. The strength of the SOTA methods is a single deterministic masking approach that addresses the challenges of random multiple masking that is inference latency and output inconsistency. Nevertheless, the issue of failure to provide a mask to completely cover anomalous regions is a remaining weakness. To mitigate this issue, we propose Feature Attenuation of Defective Representation (FADeR) that only employs two MLP layers which attenuates feature information of anomaly reconstruction during decoding. By leveraging FADeR, features of unseen anomaly patterns are reconstructed into seen normal patterns, reducing false alarms. Experimental results demonstrate that FADeR achieves enhanced performance compared to similar-scale NNs. Furthermore, our approach exhibits scalability in performance enhancement when integrated with other single deterministic masking methods in a plug-and-play manner.
Scene Depth Estimation from Traditional Oriental Landscape Paintings
Mar 07, 2024Scene depth estimation from paintings can streamline the process of 3D sculpture creation so that visually impaired people appreciate the paintings with tactile sense. However, measuring depth of oriental landscape painting images is extremely challenging due to its unique method of depicting depth and poor preservation. To address the problem of scene depth estimation from oriental landscape painting images, we propose a novel framework that consists of two-step Image-to-Image translation method with CLIP-based image matching at the front end to predict the real scene image that best matches with the given oriental landscape painting image. Then, we employ a pre-trained SOTA depth estimation model for the generated real scene image. In the first step, CycleGAN converts an oriental landscape painting image into a pseudo-real scene image. We utilize CLIP to semantically match landscape photo images with an oriental landscape painting image for training CycleGAN in an unsupervised manner. Then, the pseudo-real scene image and oriental landscape painting image are fed into DiffuseIT to predict a final real scene image in the second step. Finally, we measure depth of the generated real scene image using a pre-trained depth estimation model such as MiDaS. Experimental results show that our approach performs well enough to predict real scene images corresponding to oriental landscape painting images. To the best of our knowledge, this is the first study to measure the depth of oriental landscape painting images. Our research potentially assists visually impaired people in experiencing paintings in diverse ways. We will release our code and resulting dataset.
Empirical Analysis of Anomaly Detection on Hyperspectral Imaging Using Dimension Reduction Methods
Jan 09, 2024Recent studies try to use hyperspectral imaging (HSI) to detect foreign matters in products because it enables to visualize the invisible wavelengths including ultraviolet and infrared. Considering the enormous image channels of the HSI, several dimension reduction methods-e.g., PCA or UMAP-can be considered to reduce but those cannot ease the fundamental limitations, as follows: (1) latency of HSI capturing. (2) less explanation ability of the important channels. In this paper, to circumvent the aforementioned methods, one of the ways to channel reduction, on anomaly detection proposed HSI. Different from feature extraction methods (i.e., PCA or UMAP), feature selection can sort the feature by impact and show better explainability so we might redesign the task-optimized and cost-effective spectroscopic camera. Via the extensive experiment results with synthesized MVTec AD dataset, we confirm that the feature selection method shows 6.90x faster at the inference phase compared with feature extraction-based approaches while preserving anomaly detection performance. Ultimately, we conclude the advantage of feature selection which is effective yet fast.
Excision and Recovery: Enhancing Surface Anomaly Detection with Attention-based Single Deterministic Masking
Oct 06, 2023Anomaly detection (AD) in surface inspection is an essential yet challenging task in manufacturing due to the quantity imbalance problem of scarce abnormal data. To overcome the above, a reconstruction encoder-decoder (ED) such as autoencoder or U-Net which is trained with only anomaly-free samples is widely adopted, in the hope that unseen abnormals should yield a larger reconstruction error than normal. Over the past years, researches on self-supervised reconstruction-by-inpainting have been reported. They mask out suspected defective regions for inpainting in order to make them invisible to the reconstruction ED to deliberately cause inaccurate reconstruction for abnormals. However, their limitation is multiple random masking to cover the whole input image due to defective regions not being known in advance. We propose a novel reconstruction-by-inpainting method dubbed Excision and Recovery (EAR) that features single deterministic masking. For this, we exploit a pre-trained spatial attention model to predict potential suspected defective regions that should be masked out. We also employ a variant of U-Net as our ED to further limit the reconstruction ability of the U-Net model for abnormals, in which skip connections of different layers can be selectively disabled. In the training phase, all the skip connections are switched on to fully take the benefits from the U-Net architecture. In contrast, for inferencing, we only keep deeper skip connections with shallower connections off. We validate the effectiveness of EAR using an MNIST pre-trained attention for a commonly used surface AD dataset, KolektorSDD2. The experimental results show that EAR achieves both better AD performance and higher throughput than state-of-the-art methods. We expect that the proposed EAR model can be widely adopted as training and inference strategies for AD purposes.
Neural Network Training Strategy to Enhance Anomaly Detection Performance: A Perspective on Reconstruction Loss Amplification
Aug 28, 2023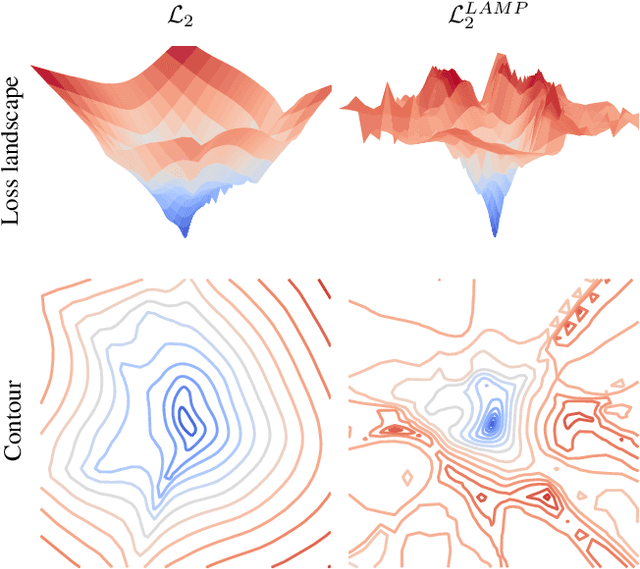
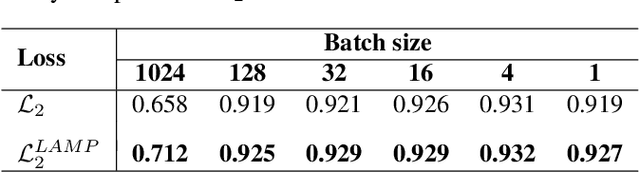
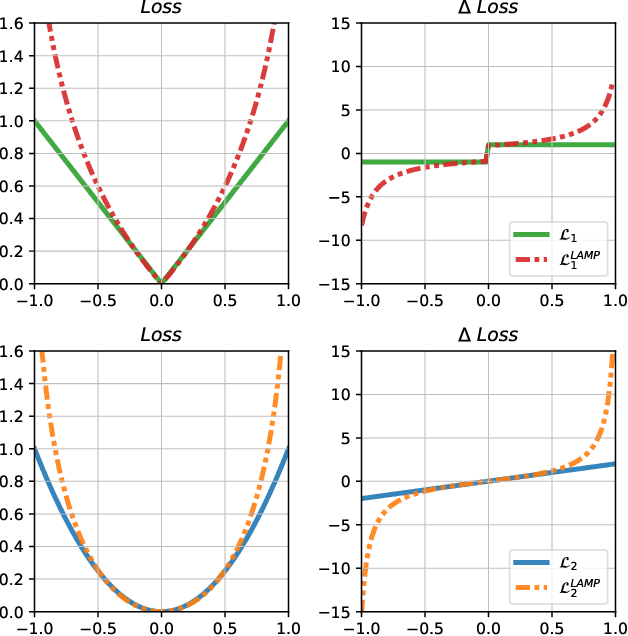
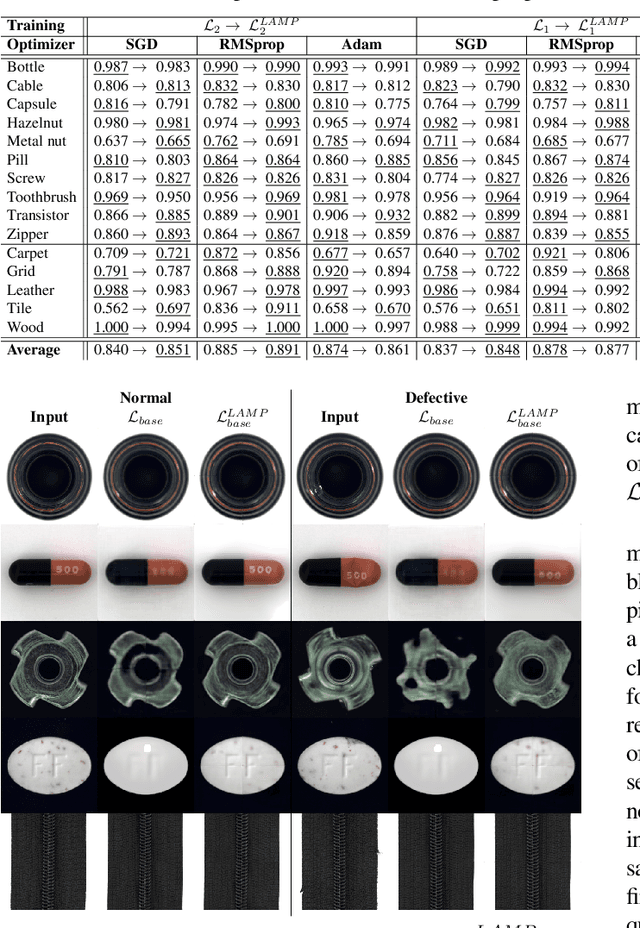
Unsupervised anomaly detection (UAD) is a widely adopted approach in industry due to rare anomaly occurrences and data imbalance. A desirable characteristic of an UAD model is contained generalization ability which excels in the reconstruction of seen normal patterns but struggles with unseen anomalies. Recent studies have pursued to contain the generalization capability of their UAD models in reconstruction from different perspectives, such as design of neural network (NN) structure and training strategy. In contrast, we note that containing of generalization ability in reconstruction can also be obtained simply from steep-shaped loss landscape. Motivated by this, we propose a loss landscape sharpening method by amplifying the reconstruction loss, dubbed Loss AMPlification (LAMP). LAMP deforms the loss landscape into a steep shape so the reconstruction error on unseen anomalies becomes greater. Accordingly, the anomaly detection performance is improved without any change of the NN architecture. Our findings suggest that LAMP can be easily applied to any reconstruction error metrics in UAD settings where the reconstruction model is trained with anomaly-free samples only.
Edge Storage Management Recipe with Zero-Shot Data Compression for Road Anomaly Detection
Jul 10, 2023Recent studies show edge computing-based road anomaly detection systems which may also conduct data collection simultaneously. However, the edge computers will have small data storage but we need to store the collected audio samples for a long time in order to update existing models or develop a novel method. Therefore, we should consider an approach for efficient storage management methods while preserving high-fidelity audio. A hardware-perspective approach, such as using a low-resolution microphone, is an intuitive way to reduce file size but is not recommended because it fundamentally cuts off high-frequency components. On the other hand, a computational file compression approach that encodes collected high-resolution audio into a compact code should be recommended because it also provides a corresponding decoding method. Motivated by this, we propose a way of simple yet effective pre-trained autoencoder-based data compression method. The pre-trained autoencoder is trained for the purpose of audio super-resolution so it can be utilized to encode or decode any arbitrary sampling rate. Moreover, it will reduce the communication cost for data transmission from the edge to the central server. Via the comparative experiments, we confirm that the zero-shot audio compression and decompression highly preserve anomaly detection performance while enhancing storage and transmission efficiency.
Concise Logarithmic Loss Function for Robust Training of Anomaly Detection Model
Jan 15, 2022Recently, deep learning-based algorithms are widely adopted due to the advantage of being able to establish anomaly detection models without or with minimal domain knowledge of the task. Instead, to train the artificial neural network more stable, it should be better to define the appropriate neural network structure or the loss function. For the training anomaly detection model, the mean squared error (MSE) function is adopted widely. On the other hand, the novel loss function, logarithmic mean squared error (LMSE), is proposed in this paper to train the neural network more stable. This study covers a variety of comparisons from mathematical comparisons, visualization in the differential domain for backpropagation, loss convergence in the training process, and anomaly detection performance. In an overall view, LMSE is superior to the existing MSE function in terms of strongness of loss convergence, anomaly detection performance. The LMSE function is expected to be applicable for training not only the anomaly detection model but also the general generative neural network.
Latent Vector Expansion using Autoencoder for Anomaly Detection
Jan 05, 2022



Deep learning methods can classify various unstructured data such as images, language, and voice as input data. As the task of classifying anomalies becomes more important in the real world, various methods exist for classifying using deep learning with data collected in the real world. As the task of classifying anomalies becomes more important in the real world, there are various methods for classifying using deep learning with data collected in the real world. Among the various methods, the representative approach is a method of extracting and learning the main features based on a transition model from pre-trained models, and a method of learning an autoencoderbased structure only with normal data and classifying it as abnormal through a threshold value. However, if the dataset is imbalanced, even the state-of-the-arts models do not achieve good performance. This can be addressed by augmenting normal and abnormal features in imbalanced data as features with strong distinction. We use the features of the autoencoder to train latent vectors from low to high dimensionality. We train normal and abnormal data as a feature that has a strong distinction among the features of imbalanced data. We propose a latent vector expansion autoencoder model that improves classification performance at imbalanced data. The proposed method shows performance improvement compared to the basic autoencoder using imbalanced anomaly dataset.