 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViewSplat: View-Adaptive Dynamic Gaussian Splatting for Feed-Forward Synthesis
Mar 26, 2026We present ViewSplat, a view-adaptive 3D Gaussian splatting network for novel view synthesis from unposed images. While recent feed-forward 3D Gaussian splatting has significantly accelerated 3D scene reconstruction by bypassing per-scene optimization, a fundamental fidelity gap remains. We attribute this bottleneck to the limited capacity of single-step feed-forward networks to regress static Gaussian primitives that satisfy all viewpoints. To address this limitation, we shift the paradigm from static primitive regression to view-adaptive dynamic splatting. Instead of a rigid Gaussian representation, our pipeline learns a view-adaptable latent representation. Specifically, ViewSplat initially predicts base Gaussian primitives alongside the weights of dynamic MLPs. During rendering, these MLPs take target view coordinates as input and predict view-dependent residual updates for each Gaussian attribute (i.e., 3D position, scale, rotation, opacity, and color). This mechanism, which we term view-adaptive dynamic splatting, allows each primitive to rectify initial estimation errors, effectively capturing high-fidelity appearances. Extensive experiments demonstrate that ViewSplat achieves state-of-the-art fidelity while maintaining fast inference (17 FPS) and real-time rendering (154 FPS).
Single-Step Bidirectional Unpaired Image Translation Using Implicit Bridge Consistency Distillation
Mar 19, 2025



Unpaired image-to-image translation has seen significant progress since the introduction of CycleGAN. However, methods based on diffusion models or Schr\"odinger bridges have yet to be widely adopted in real-world applications due to their iterative sampling nature. To address this challenge, we propose a novel framework, Implicit Bridge Consistency Distillation (IBCD), which enables single-step bidirectional unpaired translation without using adversarial loss. IBCD extends consistency distillation by using a diffusion implicit bridge model that connects PF-ODE trajectories between distributions. Additionally, we introduce two key improvements: 1) distribution matching for consistency distillation and 2) adaptive weighting method based on distillation difficulty. Experimental results demonstrate that IBCD achieves state-of-the-art performance on benchmark datasets in a single generation step. Project page available at https://hyn2028.github.io/project_page/IBCD/index.html
Reangle-A-Video: 4D Video Generation as Video-to-Video Translation
Mar 12, 2025



We introduce Reangle-A-Video, a unified framework for generating synchronized multi-view videos from a single input video. Unlike mainstream approaches that train multi-view video diffusion models on large-scale 4D datasets, our method reframes the multi-view video generation task as video-to-videos translation, leveraging publicly available image and video diffusion priors. In essence, Reangle-A-Video operates in two stages. (1) Multi-View Motion Learning: An image-to-video diffusion transformer is synchronously fine-tuned in a self-supervised manner to distill view-invariant motion from a set of warped videos. (2) Multi-View Consistent Image-to-Images Translation: The first frame of the input video is warped and inpainted into various camera perspectives under an inference-time cross-view consistency guidance using DUSt3R, generating multi-view consistent starting images. Extensive experiments on static view transport and dynamic camera control show that Reangle-A-Video surpasses existing methods, establishing a new solution for multi-view video generation. We will publicly release our code and data. Project page: https://hyeonho99.github.io/reangle-a-video/
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
LLM Itself Can Read and Generate CXR Images
May 24, 2023Building on the recent remarkable development of large language models (LLMs), active attempts are being made to extend the utility of LLMs to multimodal tasks. There have been previous efforts to link language and visual information, and attempts to add visual capabilities to LLMs are ongoing as well. However, existing attempts use LLMs only as image decoders and no attempt has been made to generate images in the same line as the natural language. By adopting a VQ-GAN framework in which latent representations of images are treated as a kind of text tokens, we present a novel method to fine-tune a pre-trained LLM to read and generate images like text without any structural changes, extra training objectives, or the need for training an ad-hoc network while still preserving the of the instruction-following capability of the LLM. We apply this framework to chest X-ray (CXR) image and report generation tasks as it is a domain in which translation of complex information between visual and language domains is important. The code is available at https://github.com/hyn2028/llm-cxr.
Improving 3D Imaging with Pre-Trained Perpendicular 2D Diffusion Models
Mar 15, 2023


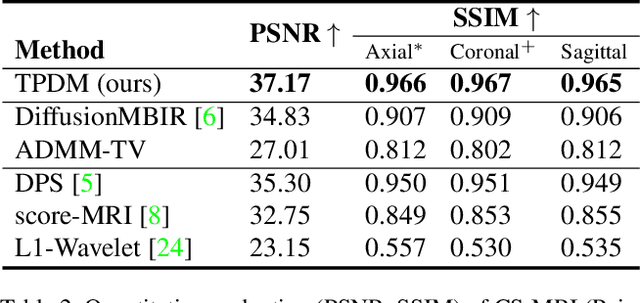
Diffusion models have become a popular approach for image generation and reconstruction due to their numerous advantages. However, most diffusion-based inverse problem-solving methods only deal with 2D images, and even recently published 3D methods do not fully exploit the 3D distribution prior. To address this, we propose a novel approach using two perpendicular pre-trained 2D diffusion models to solve the 3D inverse problem. By modeling the 3D data distribution as a product of 2D distributions sliced in different directions, our method effectively addresses the curse of dimensionality. Our experimental results demonstrate that our method is highly effective for 3D medical image reconstruction tasks, including MRI Z-axis super-resolution, compressed sensing MRI, and sparse-view CT. Our method can generate high-quality voxel volumes suitable for medical applications.
Fast Diffusion Sampler for Inverse Problems by Geometric Decomposition
Mar 10, 2023



Diffusion models have shown exceptional performance in solving inverse problems. However, one major limitation is the slow inference time. While faster diffusion samplers have been developed for unconditional sampling, there has been limited research on conditional sampling in the context of inverse problems. In this study, we propose a novel and efficient diffusion sampling strategy that employs the geometric decomposition of diffusion sampling. Specifically, we discover that the samples generated from diffusion models can be decomposed into two orthogonal components: a ``denoised" component obtained by projecting the sample onto the clean data manifold, and a ``noise" component that induces a transition to the next lower-level noisy manifold with the addition of stochastic noise. Furthermore, we prove that, under some conditions on the clean data manifold, the conjugate gradient update for imposing conditioning from the denoised signal belongs to the clean manifold, resulting in a much faster and more accurate diffusion sampling. Our method is applicable regardless of the parameterization and setting (i.e., VE, VP). Notably, we achieve state-of-the-art reconstruction quality on challenging real-world medical inverse imaging problems, including multi-coil MRI reconstruction and 3D CT reconstruction. Moreover, our proposed method achieves more than 80 times faster inference time than the previous state-of-the-art method.
SHUNIT: Style Harmonization for Unpaired Image-to-Image Translation
Jan 11, 2023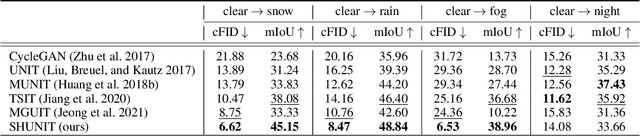
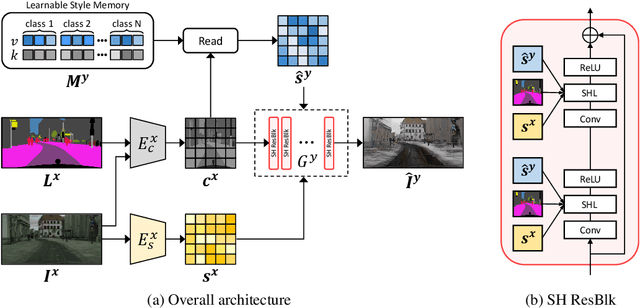
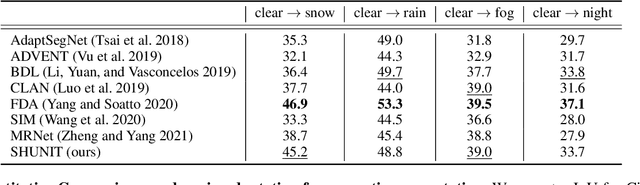
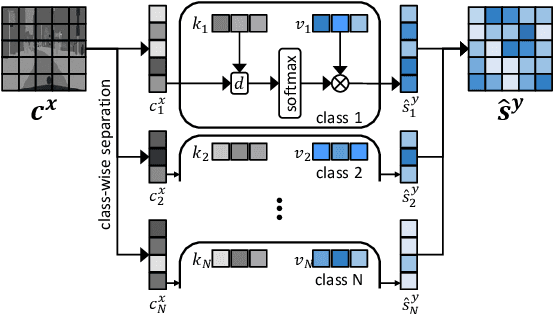
We propose a novel solution for unpaired image-to-image (I2I) translation. To translate complex images with a wide range of objects to a different domain, recent approaches often use the object annotations to perform per-class source-to-target style mapping. However, there remains a point for us to exploit in the I2I. An object in each class consists of multiple components, and all the sub-object components have different characteristics. For example, a car in CAR class consists of a car body, tires, windows and head and tail lamps, etc., and they should be handled separately for realistic I2I translation. The simplest solution to the problem will be to use more detailed annotations with sub-object component annotations than the simple object annotations, but it is not possible. The key idea of this paper is to bypass the sub-object component annotations by leveraging the original style of the input image because the original style will include the information about the characteristics of the sub-object components. Specifically, for each pixel, we use not only the per-class style gap between the source and target domains but also the pixel's original style to determine the target style of a pixel. To this end, we present Style Harmonization for unpaired I2I translation (SHUNIT). Our SHUNIT generates a new style by harmonizing the target domain style retrieved from a class memory and an original source image style. Instead of direct source-to-target style mapping, we aim for source and target styles harmonization. We validate our method with extensive experiments and achieve state-of-the-art performance on the latest benchmark sets. The source code is available online: https://github.com/bluejangbaljang/SHUNIT.
Domain Adaptive Video Semantic Segmentation via Cross-Domain Moving Object Mixing
Nov 04, 2022The network trained for domain adaptation is prone to bias toward the easy-to-transfer classes. Since the ground truth label on the target domain is unavailable during training, the bias problem leads to skewed predictions, forgetting to predict hard-to-transfer classes. To address this problem, we propose Cross-domain Moving Object Mixing (CMOM) that cuts several objects, including hard-to-transfer classes, in the source domain video clip and pastes them into the target domain video clip. Unlike image-level domain adaptation, the temporal context should be maintained to mix moving objects in two different videos. Therefore, we design CMOM to mix with consecutive video frames, so that unrealistic movements are not occurring. We additionally propose Feature Alignment with Temporal Context (FATC) to enhance target domain feature discriminability. FATC exploits the robust source domain features, which are trained with ground truth labels, to learn discriminative target domain features in an unsupervised manner by filtering unreliable predictions with temporal consensus. We demonstrate the effectiveness of the proposed approaches through extensive experiments. In particular, our model reaches mIoU of 53.81% on VIPER to Cityscapes-Seq benchmark and mIoU of 56.31% on SYNTHIA-Seq to Cityscapes-Seq benchmark, surpassing the state-of-the-art methods by large margins.
Correlation Verification for Image Retrieval
Apr 04, 2022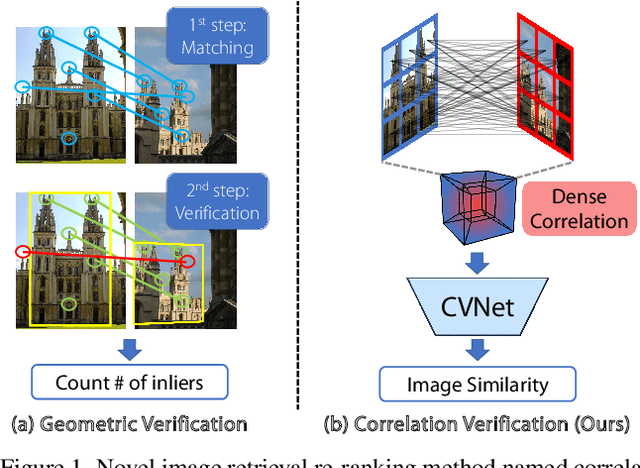
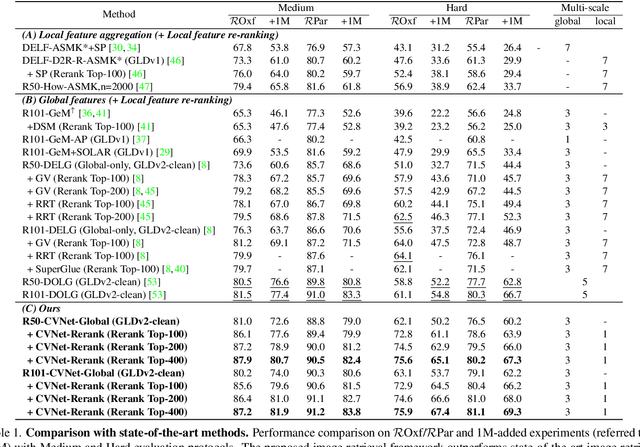

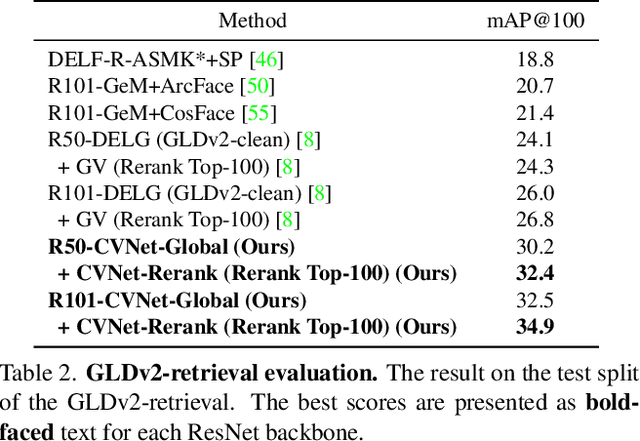
Geometric verification is considered a de facto solution for the re-ranking task in image retrieval. In this study, we propose a novel image retrieval re-ranking network named Correlation Verification Networks (CVNet). Our proposed network, comprising deeply stacked 4D convolutional layers, gradually compresses dense feature correlation into image similarity while learning diverse geometric matching patterns from various image pairs. To enable cross-scale matching, it builds feature pyramids and constructs cross-scale feature correlations within a single inference, replacing costly multi-scale inferences. In addition, we use curriculum learning with the hard negative mining and Hide-and-Seek strategy to handle hard samples without losing generality. Our proposed re-ranking network shows state-of-the-art performance on several retrieval benchmarks with a significant margin (+12.6% in mAP on ROxford-Hard+1M set) over state-of-the-art methods. The source code and models are available online: https://github.com/sungonce/CVNet.