 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDerivative-Free Diffusion Manifold-Constrained Gradient for Unified XAI
Nov 22, 2024

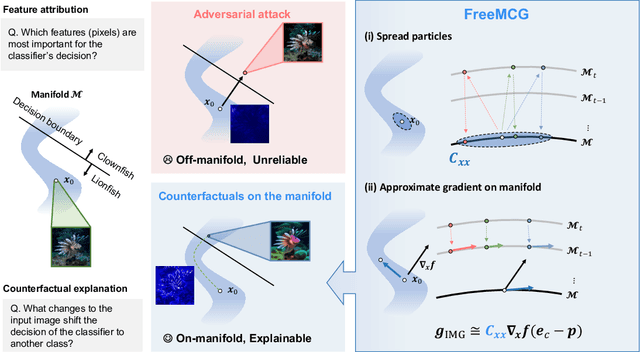
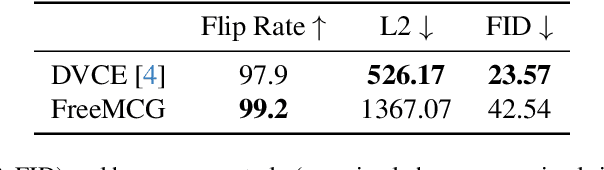
Gradient-based methods are a prototypical family of explainability techniques, especially for image-based models. Nonetheless, they have several shortcomings in that they (1) require white-box access to models, (2) are vulnerable to adversarial attacks, and (3) produce attributions that lie off the image manifold, leading to explanations that are not actually faithful to the model and do not align well with human perception. To overcome these challenges, we introduce Derivative-Free Diffusion Manifold-Constrainted Gradients (FreeMCG), a novel method that serves as an improved basis for explainability of a given neural network than the traditional gradient. Specifically, by leveraging ensemble Kalman filters and diffusion models, we derive a derivative-free approximation of the model's gradient projected onto the data manifold, requiring access only to the model's outputs. We demonstrate the effectiveness of FreeMCG by applying it to both counterfactual generation and feature attribution, which have traditionally been treated as distinct tasks. Through comprehensive evaluation on both tasks, counterfactual explanation and feature attribution, we show that our method yields state-of-the-art results while preserving the essential properties expected of XAI tools.
LLM Itself Can Read and Generate CXR Images
May 24, 2023Building on the recent remarkable development of large language models (LLMs), active attempts are being made to extend the utility of LLMs to multimodal tasks. There have been previous efforts to link language and visual information, and attempts to add visual capabilities to LLMs are ongoing as well. However, existing attempts use LLMs only as image decoders and no attempt has been made to generate images in the same line as the natural language. By adopting a VQ-GAN framework in which latent representations of images are treated as a kind of text tokens, we present a novel method to fine-tune a pre-trained LLM to read and generate images like text without any structural changes, extra training objectives, or the need for training an ad-hoc network while still preserving the of the instruction-following capability of the LLM. We apply this framework to chest X-ray (CXR) image and report generation tasks as it is a domain in which translation of complex information between visual and language domains is important. The code is available at https://github.com/hyn2028/llm-cxr.