 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuro-RIT: Neuron-Guided Instruction Tuning for Robust Retrieval-Augmented Language Model
Apr 02, 2026Retrieval-Augmented Language Models (RALMs) have demonstrated significant potential in knowledge-intensive tasks; however, they remain vulnerable to performance degradation when presented with irrelevant or noisy retrieved contexts. Existing approaches to enhance robustness typically operate via coarse-grained parameter updates at the layer or module level, often overlooking the inherent neuron-level sparsity of Large Language Models (LLMs). To address this limitation, we propose Neuro-RIT (Neuron-guided Robust Instruction Tuning), a novel framework that shifts the paradigm from dense adaptation to precision-driven neuron alignment. Our method explicitly disentangles neurons that are responsible for processing relevant versus irrelevant contexts using attribution-based neuron mining. Subsequently, we introduce a two-stage instruction tuning strategy that enforces a dual capability for noise robustness: achieving direct noise suppression by functionally deactivating neurons exclusive to irrelevant contexts, while simultaneously optimizing targeted layers for evidence distillation. Extensive experiments across diverse QA benchmarks demonstrate that Neuro-RIT consistently outperforms strong baselines and robustness-enhancing methods.
CLaD: Planning with Grounded Foresight via Cross-Modal Latent Dynamics
Mar 31, 2026Robotic manipulation involves kinematic and semantic transitions that are inherently coupled via underlying actions. However, existing approaches plan within either semantic or latent space without explicitly aligning these cross-modal transitions. To address this, we propose CLaD, a framework that models how proprioceptive and semantic states jointly evolve under actions through asymmetric cross-attention that allows kinematic transitions to query semantic ones. CLaD predicts grounded latent foresights via self-supervised objectives with EMA target encoders and auxiliary reconstruction losses, preventing representation collapse while anchoring predictions to observable states. Predicted foresights are modulated with observations to condition a diffusion policy for action generation. On LIBERO-LONG benchmark, CLaD achieves 94.7\% success rate, competitive with large VLAs with significantly fewer parameters.
Adaptive Guidance for Retrieval-Augmented Masked Diffusion Models
Mar 18, 2026Retrieval-Augmented Generation (RAG) improves factual grounding by incorporating external knowledge into language model generation. However, when retrieved context is noisy, unreliable, or inconsistent with the model's parametric knowledge, it introduces retrieval-prior conflicts that can degrade generation quality. While this problem has been studied in autoregressive language models, it remains largely unexplored in diffusion-based language models, where the iterative denoising process introduces unique challenges for integrating retrieved context. In this work, we propose Adaptive Retrieval-Augmented Masked Diffusion (ARAM), a training-free adaptive guidance framework for Masked Diffusion Models (MDMs) in RAG settings. ARAM dynamically calibrates the guidance scale during denoising according to the Signal-to-Noise Ratio (SNR) of the distributional shift induced by retrieved context. Intuitively, the model strengthens guidance when the retrieved context provides reliable corrective evidence and suppresses it when the contextual signal is noisy or non-supportive. Extensive experiments on multiple knowledge-intensive QA benchmarks show that ARAM improves overall QA performance over competitive RAG baselines.
DMD-augmented Unpaired Neural Schrödinger Bridge for Ultra-Low Field MRI Enhancement
Mar 05, 2026Ultra Low Field (64 mT) brain MRI improves accessibility but suffers from reduced image quality compared to 3 T. As paired 64 mT - 3 T scans are scarce, we propose an unpaired 64 mT $\rightarrow$ 3 T translation framework that enhances realism while preserving anatomy. Our method builds upon the Unpaired Neural Schrödinge Bridge (UNSB) with multi-step refinement. To strengthen target distribution alignment, we augment the adversarial objective with DMD2-style diffusion-guided distribution matching using a frozen 3T diffusion teacher. To explicitly constrain global structure beyond patch-level correspondence, we combine PatchNCE with an Anatomical Structure Preservation (ASP) regularizer that enforces soft foreground background consistency and boundary aware constraints. Evaluated on two disjoint cohorts, the proposed framework achieves an improved realism structure trade-off, enhancing distribution level realism on unpaired benchmarks while increasing structural fidelity on the paired cohort compared to unpaired baselines.
Dementia-R1: Reinforced Pretraining and Reasoning from Unstructured Clinical Notes for Real-World Dementia Prognosis
Jan 06, 2026While Large Language Models (LLMs) have shown strong performance on clinical text understanding, they struggle with longitudinal prediction tasks such as dementia prognosis, which require reasoning over complex, non-monotonic symptom trajectories across multiple visits. Standard supervised training lacks explicit annotations for symptom evolution, while direct Reinforcement Learning (RL) is hindered by sparse binary rewards. To address this challenge, we introduce Dementia-R1, an RL-based framework for longitudinal dementia prognosis from unstructured clinical notes. Our approach adopts a Cold-Start RL strategy that pre-trains the model to predict verifiable clinical indices extracted from patient histories, enhancing the capability to reason about disease progression before determining the final clinical status. Extensive experiments demonstrate that Dementia-R1 achieves an F1 score of 77.03% on real-world unstructured clinical datasets. Notably, on the ADNI benchmark, our 7B model rivals GPT-4o, effectively capturing fluctuating cognitive trajectories. Code is available at https://anonymous.4open.science/r/dementiar1-CDB5
Universal Reasoner: A Single, Composable Plug-and-Play Reasoner for Frozen LLMs
May 25, 2025

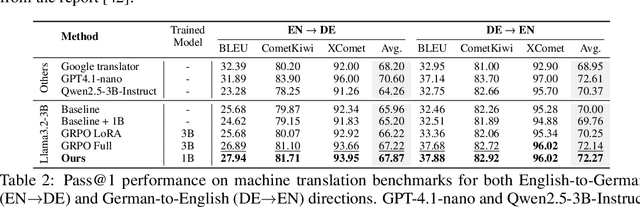

Large Language Models (LLMs) have demonstrated remarkable general capabilities, but enhancing skills such as reasoning often demands substantial computational resources and may compromise their generalization. While Parameter-Efficient Fine-Tuning (PEFT) methods offer a more resource-conscious alternative, they typically requires retraining for each LLM backbone due to architectural dependencies. To address these challenges, here we propose Universal Reasoner (UniR) - a single, lightweight, composable, and plug-and-play reasoning module that can be used with any frozen LLM to endow it with specialized reasoning capabilities. Specifically, UniR decomposes the reward into a standalone reasoning module that is trained independently using predefined rewards, effectively translating trajectory-level signals into token-level guidance. Once trained, UniR can be combined with any frozen LLM at inference time by simply adding its output logits to those of the LLM backbone. This additive structure naturally enables modular composition: multiple UniR modules trained for different tasks can be jointly applied by summing their logits, enabling complex reasoning via composition. Experimental results on mathematical reasoning and machine translation tasks show that UniR significantly outperforms \add{existing baseline fine-tuning methods using the Llama3.2 model}. Furthermore, UniR demonstrates strong weak-to-strong generalization: reasoning modules trained on smaller models effectively guide much larger LLMs. This makes UniR a cost-efficient, adaptable, and robust solution for enhancing reasoning in LLMs without compromising their core capabilities. Code is open-sourced at https://github.com/hangeol/UniR
Free$^2$Guide: Gradient-Free Path Integral Control for Enhancing Text-to-Video Generation with Large Vision-Language Models
Nov 26, 2024
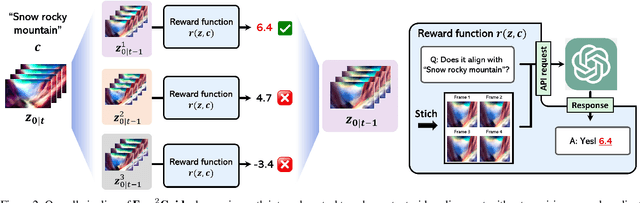
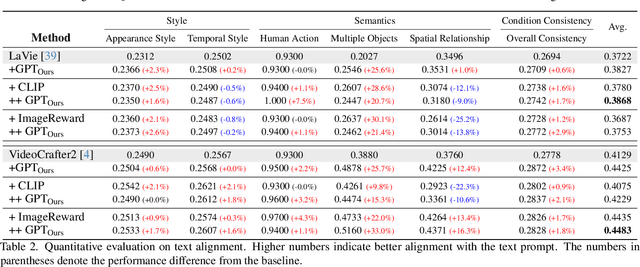

Diffusion models have achieved impressive results in generative tasks like text-to-image (T2I) and text-to-video (T2V) synthesis. However, achieving accurate text alignment in T2V generation remains challenging due to the complex temporal dependency across frames. Existing reinforcement learning (RL)-based approaches to enhance text alignment often require differentiable reward functions or are constrained to limited prompts, hindering their scalability and applicability. In this paper, we propose Free$^2$Guide, a novel gradient-free framework for aligning generated videos with text prompts without requiring additional model training. Leveraging principles from path integral control, Free$^2$Guide approximates guidance for diffusion models using non-differentiable reward functions, thereby enabling the integration of powerful black-box Large Vision-Language Models (LVLMs) as reward model. Additionally, our framework supports the flexible ensembling of multiple reward models, including large-scale image-based models, to synergistically enhance alignment without incurring substantial computational overhead. We demonstrate that Free$^2$Guide significantly improves text alignment across various dimensions and enhances the overall quality of generated videos.
Optical-Flow Guided Prompt Optimization for Coherent Video Generation
Nov 23, 2024While text-to-video diffusion models have made significant strides, many still face challenges in generating videos with temporal consistency. Within diffusion frameworks, guidance techniques have proven effective in enhancing output quality during inference; however, applying these methods to video diffusion models introduces additional complexity of handling computations across entire sequences. To address this, we propose a novel framework called MotionPrompt that guides the video generation process via optical flow. Specifically, we train a discriminator to distinguish optical flow between random pairs of frames from real videos and generated ones. Given that prompts can influence the entire video, we optimize learnable token embeddings during reverse sampling steps by using gradients from a trained discriminator applied to random frame pairs. This approach allows our method to generate visually coherent video sequences that closely reflect natural motion dynamics, without compromising the fidelity of the generated content. We demonstrate the effectiveness of our approach across various models.
Derivative-Free Diffusion Manifold-Constrained Gradient for Unified XAI
Nov 22, 2024

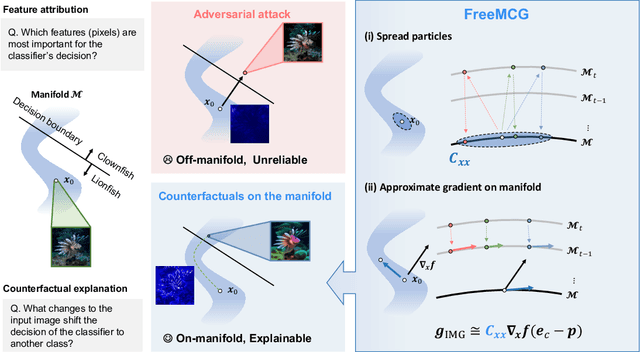
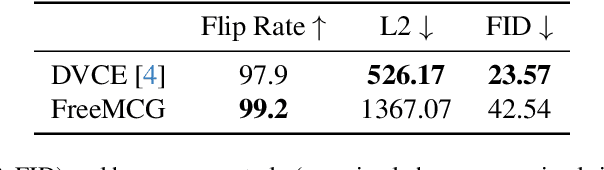
Gradient-based methods are a prototypical family of explainability techniques, especially for image-based models. Nonetheless, they have several shortcomings in that they (1) require white-box access to models, (2) are vulnerable to adversarial attacks, and (3) produce attributions that lie off the image manifold, leading to explanations that are not actually faithful to the model and do not align well with human perception. To overcome these challenges, we introduce Derivative-Free Diffusion Manifold-Constrainted Gradients (FreeMCG), a novel method that serves as an improved basis for explainability of a given neural network than the traditional gradient. Specifically, by leveraging ensemble Kalman filters and diffusion models, we derive a derivative-free approximation of the model's gradient projected onto the data manifold, requiring access only to the model's outputs. We demonstrate the effectiveness of FreeMCG by applying it to both counterfactual generation and feature attribution, which have traditionally been treated as distinct tasks. Through comprehensive evaluation on both tasks, counterfactual explanation and feature attribution, we show that our method yields state-of-the-art results while preserving the essential properties expected of XAI tools.
SentiCSE: A Sentiment-aware Contrastive Sentence Embedding Framework with Sentiment-guided Textual Similarity
Apr 01, 2024Recently, sentiment-aware pre-trained language models (PLMs) demonstrate impressive results in downstream sentiment analysis tasks. However, they neglect to evaluate the quality of their constructed sentiment representations; they just focus on improving the fine-tuning performance, which overshadows the representation quality. We argue that without guaranteeing the representation quality, their downstream performance can be highly dependent on the supervision of the fine-tuning data rather than representation quality. This problem would make them difficult to foray into other sentiment-related domains, especially where labeled data is scarce. We first propose Sentiment-guided Textual Similarity (SgTS), a novel metric for evaluating the quality of sentiment representations, which is designed based on the degree of equivalence in sentiment polarity between two sentences. We then propose SentiCSE, a novel Sentiment-aware Contrastive Sentence Embedding framework for constructing sentiment representations via combined word-level and sentence-level objectives, whose quality is guaranteed by SgTS. Qualitative and quantitative comparison with the previous sentiment-aware PLMs shows the superiority of our work. Our code is available at: https://github.com/nayohan/SentiCSE
* 14 pages, 8 figures