 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Score Matching: Unifying Reward-based Fine-tuning for Flow and Diffusion Models
Apr 19, 2026Reward-based fine-tuning aims to steer a pretrained diffusion or flow-based generative model toward higher-reward samples while remaining close to the pretrained model. Although existing methods are motivated by different perspectives such as Soft RL, GFlowNets, etc., we show that many can be written under a common framework, which we call reward score matching (RSM). Under this view, alignment becomes score matching toward a reward-guided target, and the main differences across methods reduce to the construction of the value-guidance estimator and the effective optimization strength across timesteps. This unification clarifies the bias--variance--compute tradeoffs of existing designs and distinguishes core optimization components from auxiliary mechanisms that add complexity without clear benefit. Guided by this perspective, we develop simpler redesigns that improve alignment effectiveness and compute efficiency across representative settings with differentiable and black-box rewards. Overall, RSM turns a seemingly fragmented collection of reward-based fine-tuning methods into a smaller, more interpretable, and more actionable design space.
Generalizable Holographic Reconstruction via Amplitude-Only Diffusion Priors
Sep 16, 2025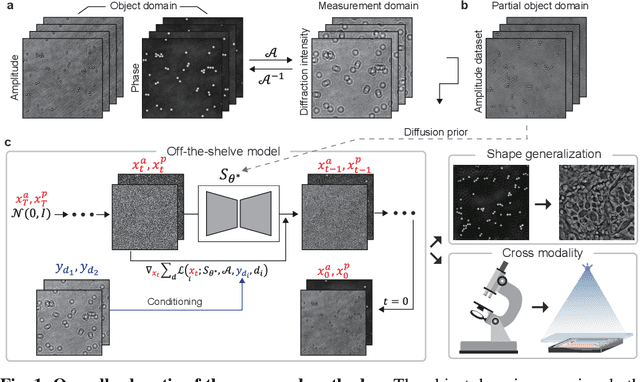
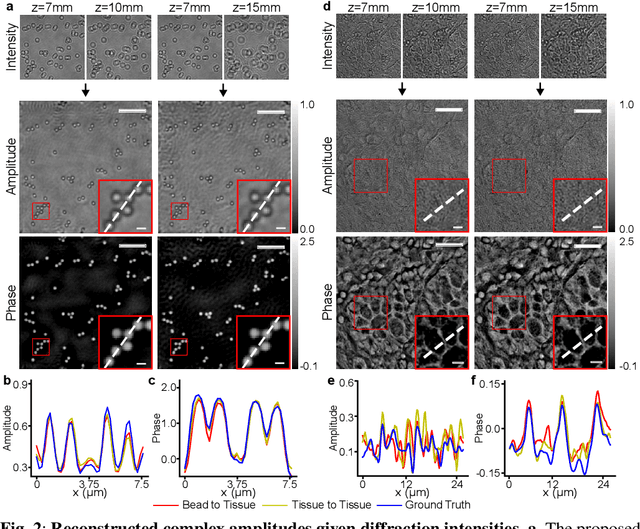
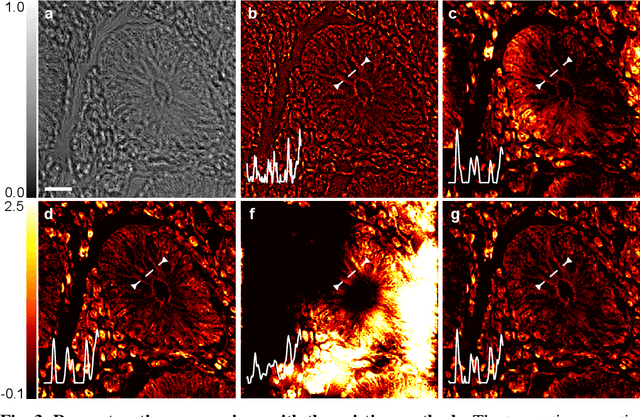
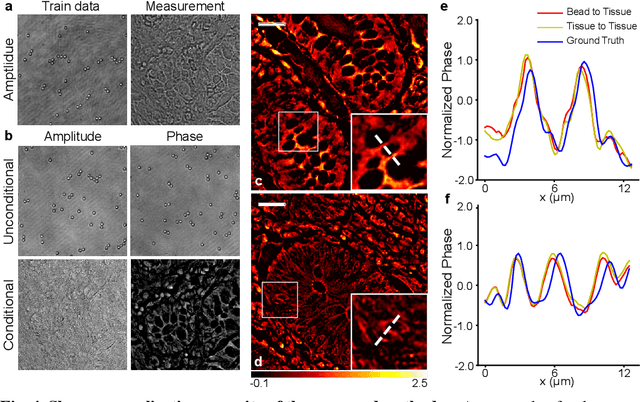
Phase retrieval in inline holography is a fundamental yet ill-posed inverse problem due to the nonlinear coupling between amplitude and phase in coherent imaging. We present a novel off-the-shelf solution that leverages a diffusion model trained solely on object amplitude to recover both amplitude and phase from diffraction intensities. Using a predictor-corrector sampling framework with separate likelihood gradients for amplitude and phase, our method enables complex field reconstruction without requiring ground-truth phase data for training. We validate the proposed approach through extensive simulations and experiments, demonstrating robust generalization across diverse object shapes, imaging system configurations, and modalities, including lensless setups. Notably, a diffusion prior trained on simple amplitude data (e.g., polystyrene beads) successfully reconstructs complex biological tissue structures, highlighting the method's adaptability. This framework provides a cost-effective, generalizable solution for nonlinear inverse problems in computational imaging, and establishes a foundation for broader coherent imaging applications beyond holography.
FlowAlign: Trajectory-Regularized, Inversion-Free Flow-based Image Editing
May 29, 2025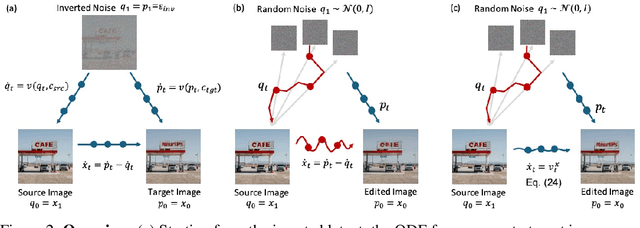

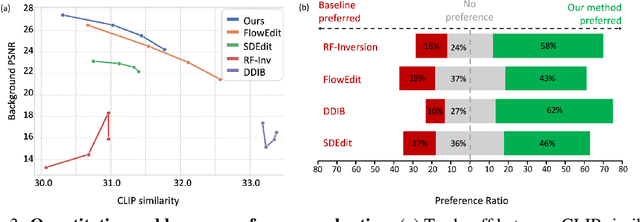

Recent inversion-free, flow-based image editing methods such as FlowEdit leverages a pre-trained noise-to-image flow model such as Stable Diffusion 3, enabling text-driven manipulation by solving an ordinary differential equation (ODE). While the lack of exact latent inversion is a core advantage of these methods, it often results in unstable editing trajectories and poor source consistency. To address this limitation, we propose FlowAlign, a novel inversion-free flow-based framework for consistent image editing with principled trajectory control. FlowAlign introduces a flow-matching loss as a regularization mechanism to promote smoother and more stable trajectories during the editing process. Notably, the flow-matching loss is shown to explicitly balance semantic alignment with the edit prompt and structural consistency with the source image along the trajectory. Furthermore, FlowAlign naturally supports reverse editing by simply reversing the ODE trajectory, highlighting the reversible and consistent nature of the transformation. Extensive experiments demonstrate that FlowAlign outperforms existing methods in both source preservation and editing controllability.
Chain-of-Zoom: Extreme Super-Resolution via Scale Autoregression and Preference Alignment
May 24, 2025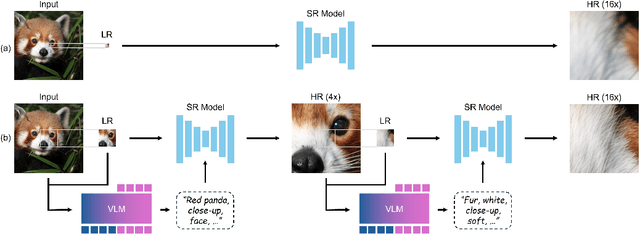
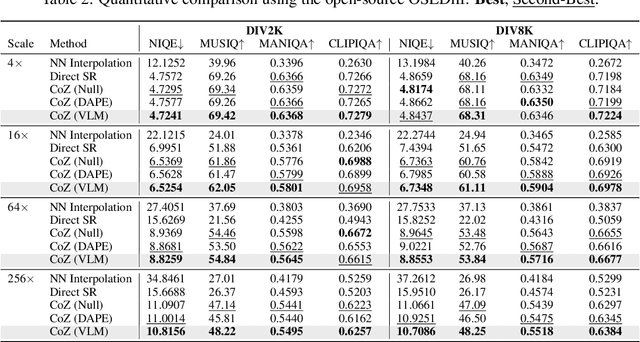
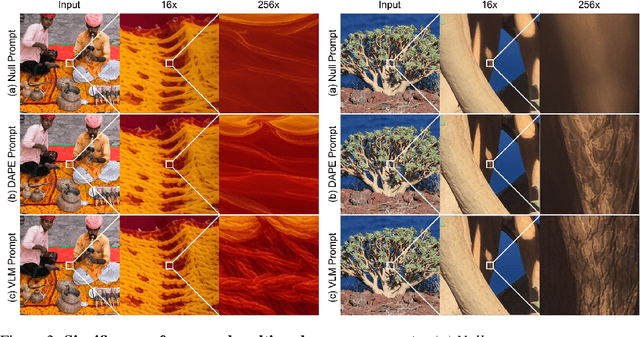
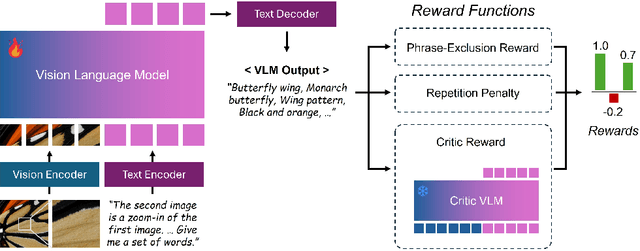
Modern single-image super-resolution (SISR) models deliver photo-realistic results at the scale factors on which they are trained, but collapse when asked to magnify far beyond that regime. We address this scalability bottleneck with Chain-of-Zoom (CoZ), a model-agnostic framework that factorizes SISR into an autoregressive chain of intermediate scale-states with multi-scale-aware prompts. CoZ repeatedly re-uses a backbone SR model, decomposing the conditional probability into tractable sub-problems to achieve extreme resolutions without additional training. Because visual cues diminish at high magnifications, we augment each zoom step with multi-scale-aware text prompts generated by a vision-language model (VLM). The prompt extractor itself is fine-tuned using Generalized Reward Policy Optimization (GRPO) with a critic VLM, aligning text guidance towards human preference. Experiments show that a standard 4x diffusion SR model wrapped in CoZ attains beyond 256x enlargement with high perceptual quality and fidelity.
FlowDPS: Flow-Driven Posterior Sampling for Inverse Problems
Mar 11, 2025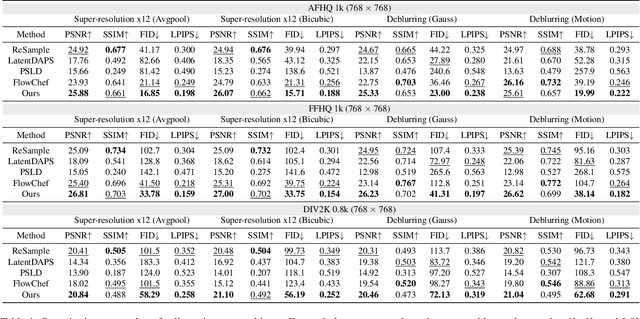
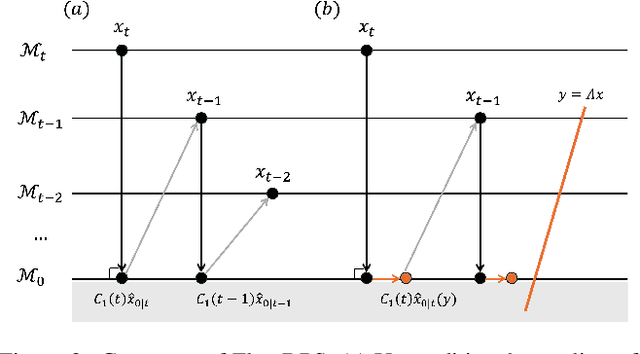

Flow matching is a recent state-of-the-art framework for generative modeling based on ordinary differential equations (ODEs). While closely related to diffusion models, it provides a more general perspective on generative modeling. Although inverse problem solving has been extensively explored using diffusion models, it has not been rigorously examined within the broader context of flow models. Therefore, here we extend the diffusion inverse solvers (DIS) - which perform posterior sampling by combining a denoising diffusion prior with an likelihood gradient - into the flow framework. Specifically, by driving the flow-version of Tweedie's formula, we decompose the flow ODE into two components: one for clean image estimation and the other for noise estimation. By integrating the likelihood gradient and stochastic noise into each component, respectively, we demonstrate that posterior sampling for inverse problem solving can be effectively achieved using flows. Our proposed solver, Flow-Driven Posterior Sampling (FlowDPS), can also be seamlessly integrated into a latent flow model with a transformer architecture. Across four linear inverse problems, we confirm that FlowDPS outperforms state-of-the-art alternatives, all without requiring additional training.
Aligning Text to Image in Diffusion Models is Easier Than You Think
Mar 11, 2025
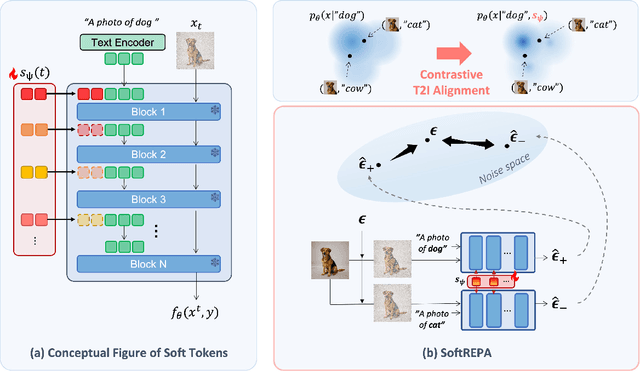


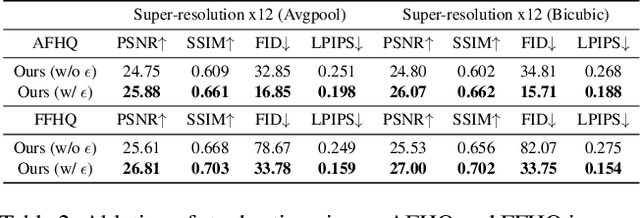
While recent advancements in generative modeling have significantly improved text-image alignment, some residual misalignment between text and image representations still remains. Although many approaches have attempted to address this issue by fine-tuning models using various reward models, etc., we revisit the challenge from the perspective of representation alignment-an approach that has gained popularity with the success of REPresentation Alignment (REPA). We first argue that conventional text-to-image (T2I) diffusion models, typically trained on paired image and text data (i.e., positive pairs) by minimizing score matching or flow matching losses, is suboptimal from the standpoint of representation alignment. Instead, a better alignment can be achieved through contrastive learning that leverages both positive and negative pairs. To achieve this efficiently even with pretrained models, we introduce a lightweight contrastive fine tuning strategy called SoftREPA that uses soft text tokens. This approach improves alignment with minimal computational overhead by adding fewer than 1M trainable parameters to the pretrained model. Our theoretical analysis demonstrates that our method explicitly increases the mutual information between text and image representations, leading to enhanced semantic consistency. Experimental results across text-to-image generation and text-guided image editing tasks validate the effectiveness of our approach in improving the semantic consistency of T2I generative models.
Latent Schrodinger Bridge: Prompting Latent Diffusion for Fast Unpaired Image-to-Image Translation
Nov 22, 2024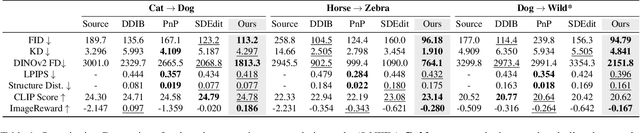
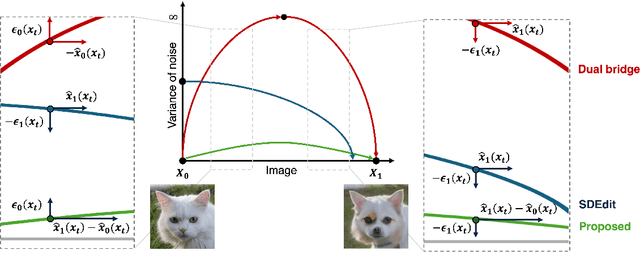

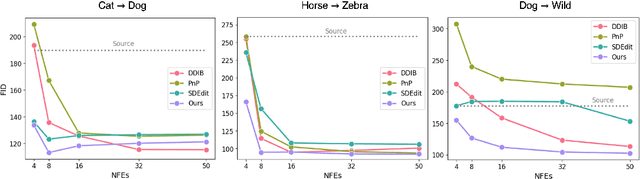
Diffusion models (DMs), which enable both image generation from noise and inversion from data, have inspired powerful unpaired image-to-image (I2I) translation algorithms. However, they often require a larger number of neural function evaluations (NFEs), limiting their practical applicability. In this paper, we tackle this problem with Schrodinger Bridges (SBs), which are stochastic differential equations (SDEs) between distributions with minimal transport cost. We analyze the probability flow ordinary differential equation (ODE) formulation of SBs, and observe that we can decompose its vector field into a linear combination of source predictor, target predictor, and noise predictor. Inspired by this observation, we propose Latent Schrodinger Bridges (LSBs) that approximate the SB ODE via pre-trained Stable Diffusion, and develop appropriate prompt optimization and change of variables formula to match the training and inference between distributions. We demonstrate that our algorithm successfully conduct competitive I2I translation in unsupervised setting with only a fraction of computation cost required by previous DM-based I2I methods.
CFG++: Manifold-constrained Classifier Free Guidance for Diffusion Models
Jun 12, 2024


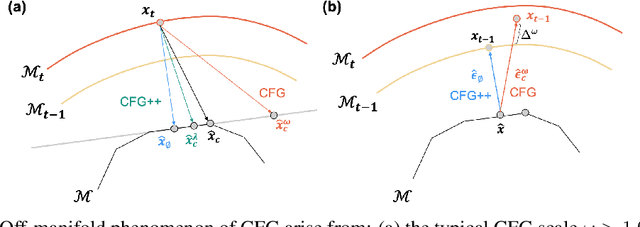
Classifier-free guidance (CFG) is a fundamental tool in modern diffusion models for text-guided generation. Although effective, CFG has notable drawbacks. For instance, DDIM with CFG lacks invertibility, complicating image editing; furthermore, high guidance scales, essential for high-quality outputs, frequently result in issues like mode collapse. Contrary to the widespread belief that these are inherent limitations of diffusion models, this paper reveals that the problems actually stem from the off-manifold phenomenon associated with CFG, rather than the diffusion models themselves. More specifically, inspired by the recent advancements of diffusion model-based inverse problem solvers (DIS), we reformulate text-guidance as an inverse problem with a text-conditioned score matching loss, and develop CFG++, a novel approach that tackles the off-manifold challenges inherent in traditional CFG. CFG++ features a surprisingly simple fix to CFG, yet it offers significant improvements, including better sample quality for text-to-image generation, invertibility, smaller guidance scales, reduced mode collapse, etc. Furthermore, CFG++ enables seamless interpolation between unconditional and conditional sampling at lower guidance scales, consistently outperforming traditional CFG at all scales. Experimental results confirm that our method significantly enhances performance in text-to-image generation, DDIM inversion, editing, and solving inverse problems, suggesting a wide-ranging impact and potential applications in various fields that utilize text guidance. Project Page: https://cfgpp-diffusion.github.io/.
Generalized Consistency Trajectory Models for Image Manipulation
Mar 19, 2024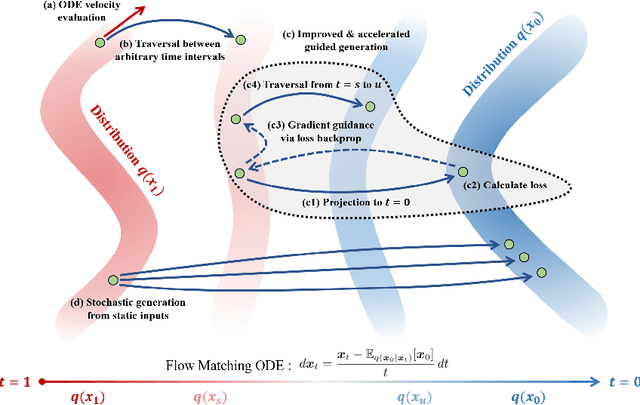

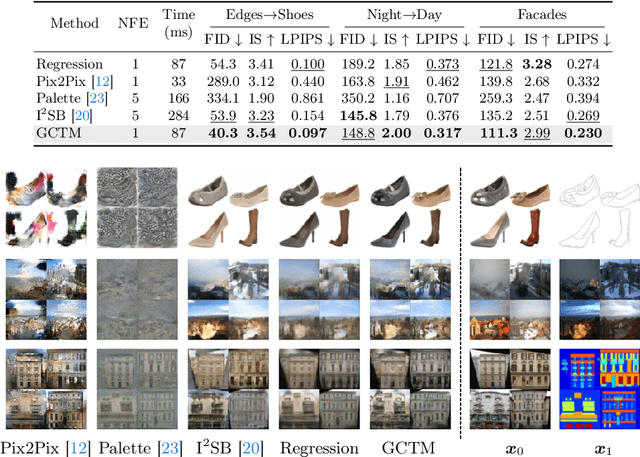
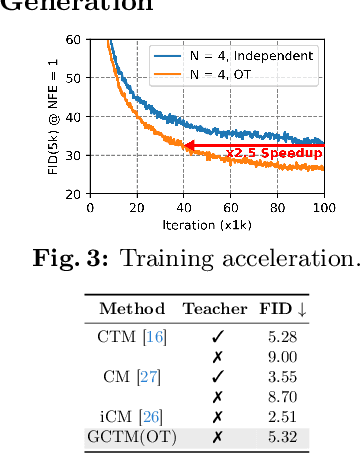
Diffusion-based generative models excel in unconditional generation, as well as on applied tasks such as image editing and restoration. The success of diffusion models lies in the iterative nature of diffusion: diffusion breaks down the complex process of mapping noise to data into a sequence of simple denoising tasks. Moreover, we are able to exert fine-grained control over the generation process by injecting guidance terms into each denoising step. However, the iterative process is also computationally intensive, often taking from tens up to thousands of function evaluations. Although consistency trajectory models (CTMs) enable traversal between any time points along the probability flow ODE (PFODE) and score inference with a single function evaluation, CTMs only allow translation from Gaussian noise to data. Thus, this work aims to unlock the full potential of CTMs by proposing generalized CTMs (GCTMs), which translate between arbitrary distributions via ODEs. We discuss the design space of GCTMs and demonstrate their efficacy in various image manipulation tasks such as image-to-image translation, restoration, and editing. Code: \url{https://github.com/1202kbs/GCTM}
DreamSampler: Unifying Diffusion Sampling and Score Distillation for Image Manipulation
Mar 18, 2024Reverse sampling and score-distillation have emerged as main workhorses in recent years for image manipulation using latent diffusion models (LDMs). While reverse diffusion sampling often requires adjustments of LDM architecture or feature engineering, score distillation offers a simple yet powerful model-agnostic approach, but it is often prone to mode-collapsing. To address these limitations and leverage the strengths of both approaches, here we introduce a novel framework called {\em DreamSampler}, which seamlessly integrates these two distinct approaches through the lens of regularized latent optimization. Similar to score-distillation, DreamSampler is a model-agnostic approach applicable to any LDM architecture, but it allows both distillation and reverse sampling with additional guidance for image editing and reconstruction. Through experiments involving image editing, SVG reconstruction and etc, we demonstrate the competitive performance of DreamSampler compared to existing approaches, while providing new applications.