 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDINO-SAE: DINO Spherical Autoencoder for High-Fidelity Image Reconstruction and Generation
Jan 30, 2026Recent studies have explored using pretrained Vision Foundation Models (VFMs) such as DINO for generative autoencoders, showing strong generative performance. Unfortunately, existing approaches often suffer from limited reconstruction fidelity due to the loss of high-frequency details. In this work, we present the DINO Spherical Autoencoder (DINO-SAE), a framework that bridges semantic representation and pixel-level reconstruction. Our key insight is that semantic information in contrastive representations is primarily encoded in the direction of feature vectors, while forcing strict magnitude matching can hinder the encoder from preserving fine-grained details. To address this, we introduce Hierarchical Convolutional Patch Embedding module that enhances local structure and texture preservation, and Cosine Similarity Alignment objective that enforces semantic consistency while allowing flexible feature magnitudes for detail retention. Furthermore, leveraging the observation that SSL-based foundation model representations intrinsically lie on a hypersphere, we employ Riemannian Flow Matching to train a Diffusion Transformer (DiT) directly on this spherical latent manifold. Experiments on ImageNet-1K demonstrate that our approach achieves state-of-the-art reconstruction quality, reaching 0.37 rFID and 26.2 dB PSNR, while maintaining strong semantic alignment to the pretrained VFM. Notably, our Riemannian Flow Matching-based DiT exhibits efficient convergence, achieving a gFID of 3.47 at 80 epochs.
Align Your Tangent: Training Better Consistency Models via Manifold-Aligned Tangents
Oct 01, 2025With diffusion and flow matching models achieving state-of-the-art generating performance, the interest of the community now turned to reducing the inference time without sacrificing sample quality. Consistency Models (CMs), which are trained to be consistent on diffusion or probability flow ordinary differential equation (PF-ODE) trajectories, enable one or two-step flow or diffusion sampling. However, CMs typically require prolonged training with large batch sizes to obtain competitive sample quality. In this paper, we examine the training dynamics of CMs near convergence and discover that CM tangents -- CM output update directions -- are quite oscillatory, in the sense that they move parallel to the data manifold, not towards the manifold. To mitigate oscillatory tangents, we propose a new loss function, called the manifold feature distance (MFD), which provides manifold-aligned tangents that point toward the data manifold. Consequently, our method -- dubbed Align Your Tangent (AYT) -- can accelerate CM training by orders of magnitude and even out-perform the learned perceptual image patch similarity metric (LPIPS). Furthermore, we find that our loss enables training with extremely small batch sizes without compromising sample quality. Code: https://github.com/1202kbs/AYT
Aligning Text to Image in Diffusion Models is Easier Than You Think
Mar 11, 2025
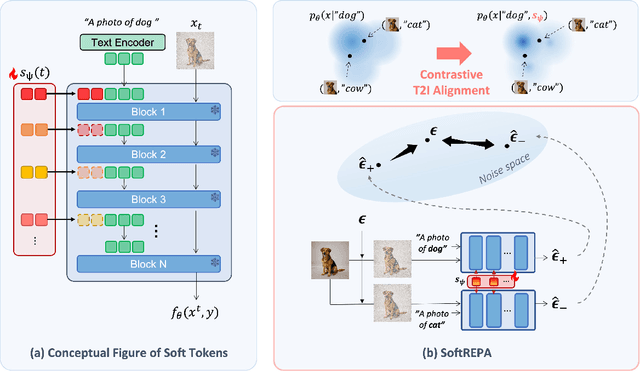


While recent advancements in generative modeling have significantly improved text-image alignment, some residual misalignment between text and image representations still remains. Although many approaches have attempted to address this issue by fine-tuning models using various reward models, etc., we revisit the challenge from the perspective of representation alignment-an approach that has gained popularity with the success of REPresentation Alignment (REPA). We first argue that conventional text-to-image (T2I) diffusion models, typically trained on paired image and text data (i.e., positive pairs) by minimizing score matching or flow matching losses, is suboptimal from the standpoint of representation alignment. Instead, a better alignment can be achieved through contrastive learning that leverages both positive and negative pairs. To achieve this efficiently even with pretrained models, we introduce a lightweight contrastive fine tuning strategy called SoftREPA that uses soft text tokens. This approach improves alignment with minimal computational overhead by adding fewer than 1M trainable parameters to the pretrained model. Our theoretical analysis demonstrates that our method explicitly increases the mutual information between text and image representations, leading to enhanced semantic consistency. Experimental results across text-to-image generation and text-guided image editing tasks validate the effectiveness of our approach in improving the semantic consistency of T2I generative models.