 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiled Prompts: Overcoming Prompt Underspecification in Image and Video Super-Resolution
Feb 03, 2026Text-conditioned diffusion models have advanced image and video super-resolution by using prompts as semantic priors, but modern super-resolution pipelines typically rely on latent tiling to scale to high resolutions, where a single global caption causes prompt underspecification. A coarse global prompt often misses localized details (prompt sparsity) and provides locally irrelevant guidance (prompt misguidance) that can be amplified by classifier-free guidance. We propose Tiled Prompts, a unified framework for image and video super-resolution that generates a tile-specific prompt for each latent tile and performs super-resolution under locally text-conditioned posteriors, providing high-information guidance that resolves prompt underspecification with minimal overhead. Experiments on high resolution real-world images and videos show consistent gains in perceptual quality and text alignment, while reducing hallucinations and tile-level artifacts relative to global-prompt baselines.
Extreme Blind Image Restoration via Prompt-Conditioned Information Bottleneck
Oct 01, 2025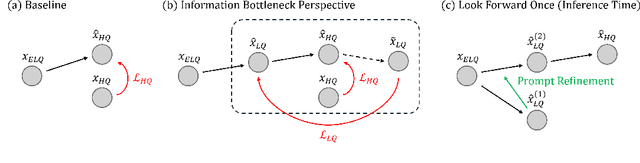
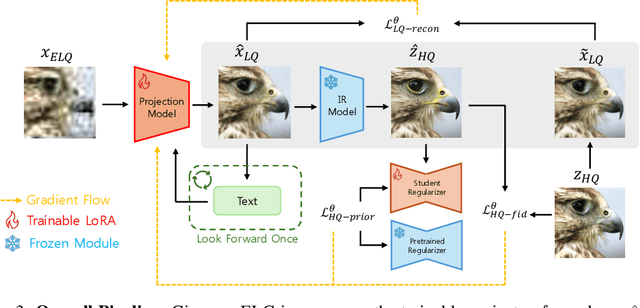


Blind Image Restoration (BIR) methods have achieved remarkable success but falter when faced with Extreme Blind Image Restoration (EBIR), where inputs suffer from severe, compounded degradations beyond their training scope. Directly learning a mapping from extremely low-quality (ELQ) to high-quality (HQ) images is challenging due to the massive domain gap, often leading to unnatural artifacts and loss of detail. To address this, we propose a novel framework that decomposes the intractable ELQ-to-HQ restoration process. We first learn a projector that maps an ELQ image onto an intermediate, less-degraded LQ manifold. This intermediate image is then restored to HQ using a frozen, off-the-shelf BIR model. Our approach is grounded in information theory; we provide a novel perspective of image restoration as an Information Bottleneck problem and derive a theoretically-driven objective to train our projector. This loss function effectively stabilizes training by balancing a low-quality reconstruction term with a high-quality prior-matching term. Our framework enables Look Forward Once (LFO) for inference-time prompt refinement, and supports plug-and-play strengthening of existing image restoration models without need for finetuning. Extensive experiments under severe degradation regimes provide a thorough analysis of the effectiveness of our work.
Chain-of-Zoom: Extreme Super-Resolution via Scale Autoregression and Preference Alignment
May 24, 2025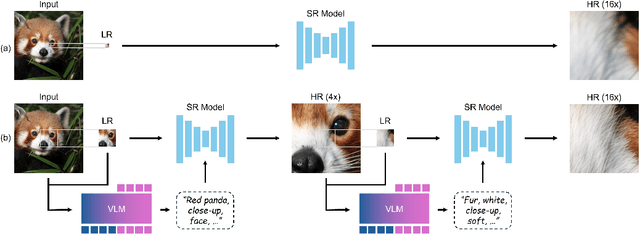
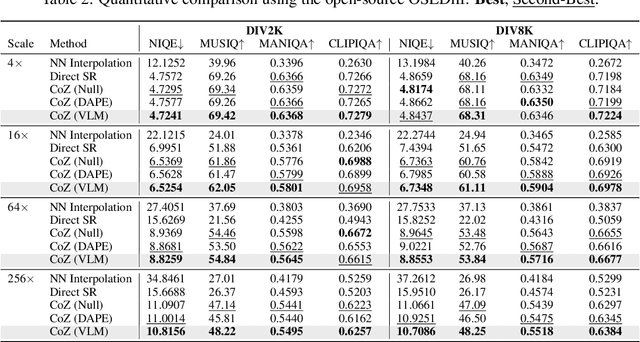
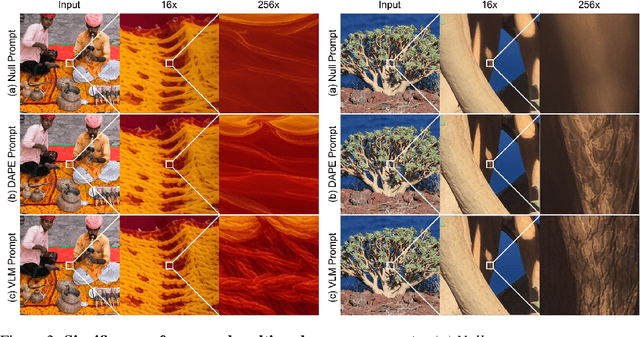
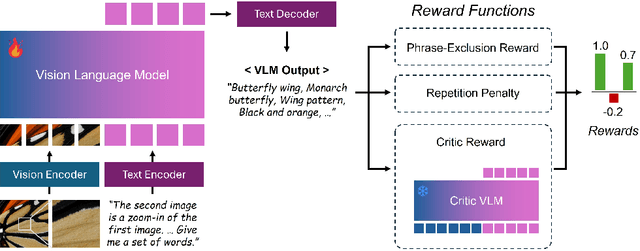
Modern single-image super-resolution (SISR) models deliver photo-realistic results at the scale factors on which they are trained, but collapse when asked to magnify far beyond that regime. We address this scalability bottleneck with Chain-of-Zoom (CoZ), a model-agnostic framework that factorizes SISR into an autoregressive chain of intermediate scale-states with multi-scale-aware prompts. CoZ repeatedly re-uses a backbone SR model, decomposing the conditional probability into tractable sub-problems to achieve extreme resolutions without additional training. Because visual cues diminish at high magnifications, we augment each zoom step with multi-scale-aware text prompts generated by a vision-language model (VLM). The prompt extractor itself is fine-tuned using Generalized Reward Policy Optimization (GRPO) with a critic VLM, aligning text guidance towards human preference. Experiments show that a standard 4x diffusion SR model wrapped in CoZ attains beyond 256x enlargement with high perceptual quality and fidelity.
FlowDPS: Flow-Driven Posterior Sampling for Inverse Problems
Mar 11, 2025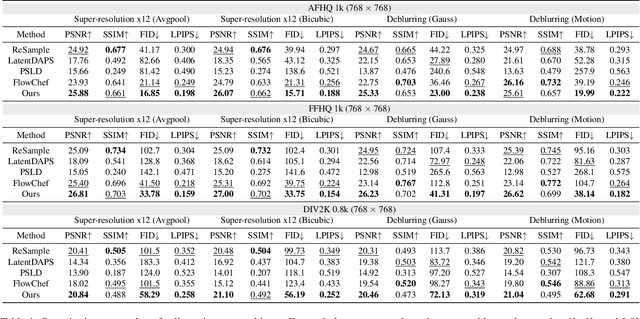
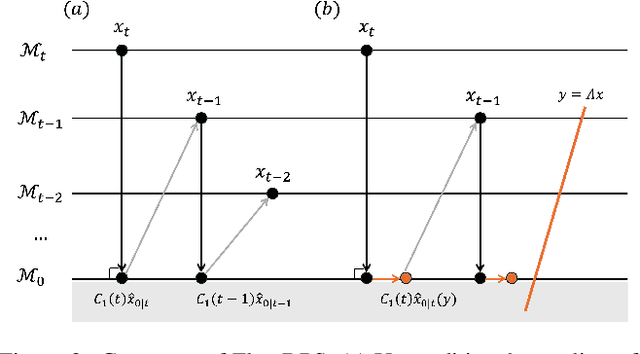
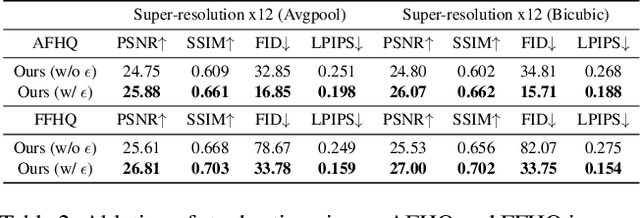

Flow matching is a recent state-of-the-art framework for generative modeling based on ordinary differential equations (ODEs). While closely related to diffusion models, it provides a more general perspective on generative modeling. Although inverse problem solving has been extensively explored using diffusion models, it has not been rigorously examined within the broader context of flow models. Therefore, here we extend the diffusion inverse solvers (DIS) - which perform posterior sampling by combining a denoising diffusion prior with an likelihood gradient - into the flow framework. Specifically, by driving the flow-version of Tweedie's formula, we decompose the flow ODE into two components: one for clean image estimation and the other for noise estimation. By integrating the likelihood gradient and stochastic noise into each component, respectively, we demonstrate that posterior sampling for inverse problem solving can be effectively achieved using flows. Our proposed solver, Flow-Driven Posterior Sampling (FlowDPS), can also be seamlessly integrated into a latent flow model with a transformer architecture. Across four linear inverse problems, we confirm that FlowDPS outperforms state-of-the-art alternatives, all without requiring additional training.