 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEditCrafter: Tuning-free High-Resolution Image Editing via Pretrained Diffusion Model
Apr 11, 2026We propose EditCrafter, a high-resolution image editing method that operates without tuning, leveraging pretrained text-to-image (T2I) diffusion models to process images at resolutions significantly exceeding those used during training. Leveraging the generative priors of large-scale T2I diffusion models enables the development of a wide array of novel generation and editing applications. Although numerous image editing methods have been proposed based on diffusion models and exhibit high-quality editing results, they are difficult to apply to images with arbitrary aspect ratios or higher resolutions since they only work at the training resolutions (512x512 or 1024x1024). Naively applying patch-wise editing fails with unrealistic object structures and repetition. To address these challenges, we introduce EditCrafter, a simple yet effective editing pipeline. EditCrafter operates by first performing tiled inversion, which preserves the original identity of the input high-resolution image. We further propose a noise-damped manifold-constrained classifier-free guidance (NDCFG++) that is tailored for high resolution image editing from the inverted latent. Our experiments show that the our EditCrafter can achieve impressive editing results across various resolutions without fine-tuning and optimization.
Video Parallel Scaling: Aggregating Diverse Frame Subsets for VideoLLMs
Sep 09, 2025



Video Large Language Models (VideoLLMs) face a critical bottleneck: increasing the number of input frames to capture fine-grained temporal detail leads to prohibitive computational costs and performance degradation from long context lengths. We introduce Video Parallel Scaling (VPS), an inference-time method that expands a model's perceptual bandwidth without increasing its context window. VPS operates by running multiple parallel inference streams, each processing a unique, disjoint subset of the video's frames. By aggregating the output probabilities from these complementary streams, VPS integrates a richer set of visual information than is possible with a single pass. We theoretically show that this approach effectively contracts the Chinchilla scaling law by leveraging uncorrelated visual evidence, thereby improving performance without additional training. Extensive experiments across various model architectures and scales (2B-32B) on benchmarks such as Video-MME and EventHallusion demonstrate that VPS consistently and significantly improves performance. It scales more favorably than other parallel alternatives (e.g. Self-consistency) and is complementary to other decoding strategies, offering a memory-efficient and robust framework for enhancing the temporal reasoning capabilities of VideoLLMs.
InvFussion: Bridging Supervised and Zero-shot Diffusion for Inverse Problems
Apr 02, 2025
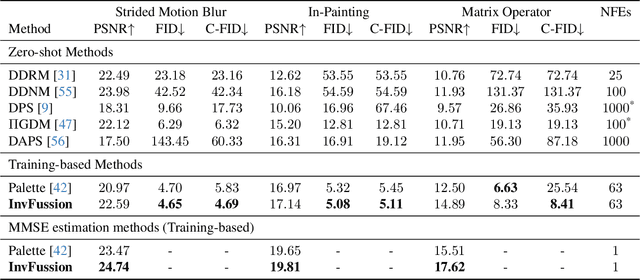

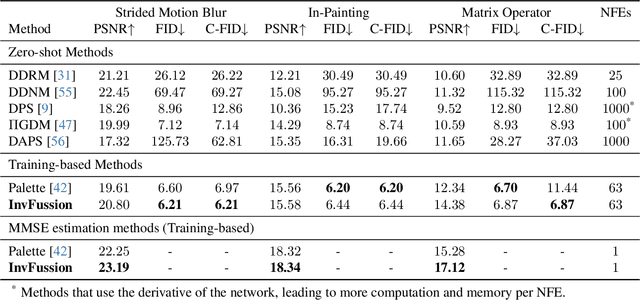
Diffusion Models have demonstrated remarkable capabilities in handling inverse problems, offering high-quality posterior-sampling-based solutions. Despite significant advances, a fundamental trade-off persists, regarding the way the conditioned synthesis is employed: Training-based methods achieve high quality results, while zero-shot approaches trade this with flexibility. This work introduces a framework that combines the best of both worlds -- the strong performance of supervised approaches and the flexibility of zero-shot methods. This is achieved through a novel architectural design that seamlessly integrates the degradation operator directly into the denoiser. In each block, our proposed architecture applies the degradation operator on the network activations and conditions the output using the attention mechanism, enabling adaptation to diverse degradation scenarios while maintaining high performance. Our work demonstrates the versatility of the proposed architecture, operating as a general MMSE estimator, a posterior sampler, or a Neural Posterior Principal Component estimator. This flexibility enables a wide range of downstream tasks, highlighting the broad applicability of our framework. The proposed modification of the denoiser network offers a versatile, accurate, and computationally efficient solution, demonstrating the advantages of dedicated network architectures for complex inverse problems. Experimental results on the FFHQ and ImageNet datasets demonstrate state-of-the-art posterior-sampling performance, surpassing both training-based and zero-shot alternatives.
VideoRFSplat: Direct Scene-Level Text-to-3D Gaussian Splatting Generation with Flexible Pose and Multi-View Joint Modeling
Mar 20, 2025We propose VideoRFSplat, a direct text-to-3D model leveraging a video generation model to generate realistic 3D Gaussian Splatting (3DGS) for unbounded real-world scenes. To generate diverse camera poses and unbounded spatial extent of real-world scenes, while ensuring generalization to arbitrary text prompts, previous methods fine-tune 2D generative models to jointly model camera poses and multi-view images. However, these methods suffer from instability when extending 2D generative models to joint modeling due to the modality gap, which necessitates additional models to stabilize training and inference. In this work, we propose an architecture and a sampling strategy to jointly model multi-view images and camera poses when fine-tuning a video generation model. Our core idea is a dual-stream architecture that attaches a dedicated pose generation model alongside a pre-trained video generation model via communication blocks, generating multi-view images and camera poses through separate streams. This design reduces interference between the pose and image modalities. Additionally, we propose an asynchronous sampling strategy that denoises camera poses faster than multi-view images, allowing rapidly denoised poses to condition multi-view generation, reducing mutual ambiguity and enhancing cross-modal consistency. Trained on multiple large-scale real-world datasets (RealEstate10K, MVImgNet, DL3DV-10K, ACID), VideoRFSplat outperforms existing text-to-3D direct generation methods that heavily depend on post-hoc refinement via score distillation sampling, achieving superior results without such refinement.
SteerX: Creating Any Camera-Free 3D and 4D Scenes with Geometric Steering
Mar 15, 2025



Recent progress in 3D/4D scene generation emphasizes the importance of physical alignment throughout video generation and scene reconstruction. However, existing methods improve the alignment separately at each stage, making it difficult to manage subtle misalignments arising from another stage. Here, we present SteerX, a zero-shot inference-time steering method that unifies scene reconstruction into the generation process, tilting data distributions toward better geometric alignment. To this end, we introduce two geometric reward functions for 3D/4D scene generation by using pose-free feed-forward scene reconstruction models. Through extensive experiments, we demonstrate the effectiveness of SteerX in improving 3D/4D scene generation.
A Foundational Brain Dynamics Model via Stochastic Optimal Control
Feb 07, 2025We introduce a foundational model for brain dynamics that utilizes stochastic optimal control (SOC) and amortized inference. Our method features a continuous-discrete state space model (SSM) that can robustly handle the intricate and noisy nature of fMRI signals. To address computational limitations, we implement an approximation strategy grounded in the SOC framework. Additionally, we present a simulation-free latent dynamics approach that employs locally linear approximations, facilitating efficient and scalable inference. For effective representation learning, we derive an Evidence Lower Bound (ELBO) from the SOC formulation, which integrates smoothly with recent advancements in self-supervised learning (SSL), thereby promoting robust and transferable representations. Pre-trained on extensive datasets such as the UKB, our model attains state-of-the-art results across a variety of downstream tasks, including demographic prediction, trait analysis, disease diagnosis, and prognosis. Moreover, evaluating on external datasets such as HCP-A, ABIDE, and ADHD200 further validates its superior abilities and resilience across different demographic and clinical distributions. Our foundational model provides a scalable and efficient approach for deciphering brain dynamics, opening up numerous applications in neuroscience.
ContextMRI: Enhancing Compressed Sensing MRI through Metadata Conditioning
Jan 08, 2025Compressed sensing MRI seeks to accelerate MRI acquisition processes by sampling fewer k-space measurements and then reconstructing the missing data algorithmically. The success of these approaches often relies on strong priors or learned statistical models. While recent diffusion model-based priors have shown great potential, previous methods typically ignore clinically available metadata (e.g. patient demographics, imaging parameters, slice-specific information). In practice, metadata contains meaningful cues about the anatomy and acquisition protocol, suggesting it could further constrain the reconstruction problem. In this work, we propose ContextMRI, a text-conditioned diffusion model for MRI that integrates granular metadata into the reconstruction process. We train a pixel-space diffusion model directly on minimally processed, complex-valued MRI images. During inference, metadata is converted into a structured text prompt and fed to the model via CLIP text embeddings. By conditioning the prior on metadata, we unlock more accurate reconstructions and show consistent gains across multiple datasets, acceleration factors, and undersampling patterns. Our experiments demonstrate that increasing the fidelity of metadata, ranging from slice location and contrast to patient age, sex, and pathology, systematically boosts reconstruction performance. This work highlights the untapped potential of leveraging clinical context for inverse problems and opens a new direction for metadata-driven MRI reconstruction.
Contrastive CFG: Improving CFG in Diffusion Models by Contrasting Positive and Negative Concepts
Nov 26, 2024As Classifier-Free Guidance (CFG) has proven effective in conditional diffusion model sampling for improved condition alignment, many applications use a negated CFG term to filter out unwanted features from samples. However, simply negating CFG guidance creates an inverted probability distribution, often distorting samples away from the marginal distribution. Inspired by recent advances in conditional diffusion models for inverse problems, here we present a novel method to enhance negative CFG guidance using contrastive loss. Specifically, our guidance term aligns or repels the denoising direction based on the given condition through contrastive loss, achieving a nearly identical guiding direction to traditional CFG for positive guidance while overcoming the limitations of existing negative guidance methods. Experimental results demonstrate that our approach effectively removes undesirable concepts while maintaining sample quality across diverse scenarios, from simple class conditions to complex and overlapping text prompts.
Derivative-Free Diffusion Manifold-Constrained Gradient for Unified XAI
Nov 22, 2024

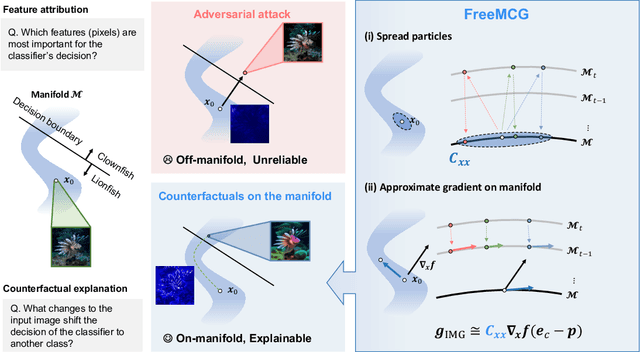
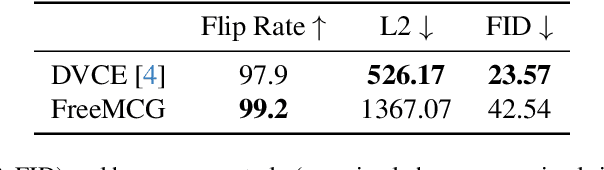
Gradient-based methods are a prototypical family of explainability techniques, especially for image-based models. Nonetheless, they have several shortcomings in that they (1) require white-box access to models, (2) are vulnerable to adversarial attacks, and (3) produce attributions that lie off the image manifold, leading to explanations that are not actually faithful to the model and do not align well with human perception. To overcome these challenges, we introduce Derivative-Free Diffusion Manifold-Constrainted Gradients (FreeMCG), a novel method that serves as an improved basis for explainability of a given neural network than the traditional gradient. Specifically, by leveraging ensemble Kalman filters and diffusion models, we derive a derivative-free approximation of the model's gradient projected onto the data manifold, requiring access only to the model's outputs. We demonstrate the effectiveness of FreeMCG by applying it to both counterfactual generation and feature attribution, which have traditionally been treated as distinct tasks. Through comprehensive evaluation on both tasks, counterfactual explanation and feature attribution, we show that our method yields state-of-the-art results while preserving the essential properties expected of XAI tools.
CapeLLM: Support-Free Category-Agnostic Pose Estimation with Multimodal Large Language Models
Nov 11, 2024



Category-agnostic pose estimation (CAPE) has traditionally relied on support images with annotated keypoints, a process that is often cumbersome and may fail to fully capture the necessary correspondences across diverse object categories. Recent efforts have begun exploring the use of text-based queries, where the need for support keypoints is eliminated. However, the optimal use of textual descriptions for keypoints remains an underexplored area. In this work, we introduce CapeLLM, a novel approach that leverages a text-based multimodal large language model (MLLM) for CAPE. Our method only employs query image and detailed text descriptions as an input to estimate category-agnostic keypoints. We conduct extensive experiments to systematically explore the design space of LLM-based CAPE, investigating factors such as choosing the optimal description for keypoints, neural network architectures, and training strategies. Thanks to the advanced reasoning capabilities of the pre-trained MLLM, CapeLLM demonstrates superior generalization and robust performance. Our approach sets a new state-of-the-art on the MP-100 benchmark in the challenging 1-shot setting, marking a significant advancement in the field of category-agnostic pose estimation.