 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvFussion: Bridging Supervised and Zero-shot Diffusion for Inverse Problems
Apr 02, 2025
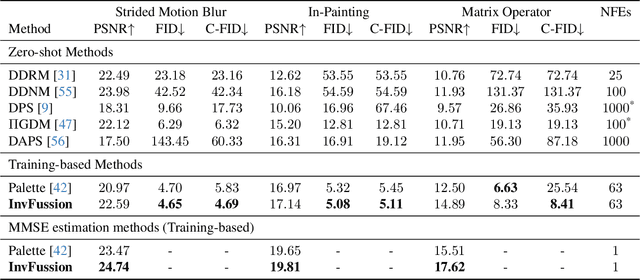

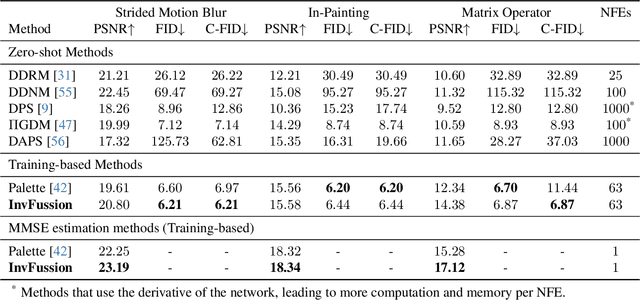
Diffusion Models have demonstrated remarkable capabilities in handling inverse problems, offering high-quality posterior-sampling-based solutions. Despite significant advances, a fundamental trade-off persists, regarding the way the conditioned synthesis is employed: Training-based methods achieve high quality results, while zero-shot approaches trade this with flexibility. This work introduces a framework that combines the best of both worlds -- the strong performance of supervised approaches and the flexibility of zero-shot methods. This is achieved through a novel architectural design that seamlessly integrates the degradation operator directly into the denoiser. In each block, our proposed architecture applies the degradation operator on the network activations and conditions the output using the attention mechanism, enabling adaptation to diverse degradation scenarios while maintaining high performance. Our work demonstrates the versatility of the proposed architecture, operating as a general MMSE estimator, a posterior sampler, or a Neural Posterior Principal Component estimator. This flexibility enables a wide range of downstream tasks, highlighting the broad applicability of our framework. The proposed modification of the denoiser network offers a versatile, accurate, and computationally efficient solution, demonstrating the advantages of dedicated network architectures for complex inverse problems. Experimental results on the FFHQ and ImageNet datasets demonstrate state-of-the-art posterior-sampling performance, surpassing both training-based and zero-shot alternatives.
Novel View Synthesis with Pixel-Space Diffusion Models
Nov 12, 2024Synthesizing a novel view from a single input image is a challenging task. Traditionally, this task was approached by estimating scene depth, warping, and inpainting, with machine learning models enabling parts of the pipeline. More recently, generative models are being increasingly employed in novel view synthesis (NVS), often encompassing the entire end-to-end system. In this work, we adapt a modern diffusion model architecture for end-to-end NVS in the pixel space, substantially outperforming previous state-of-the-art (SOTA) techniques. We explore different ways to encode geometric information into the network. Our experiments show that while these methods may enhance performance, their impact is minor compared to utilizing improved generative models. Moreover, we introduce a novel NVS training scheme that utilizes single-view datasets, capitalizing on their relative abundance compared to their multi-view counterparts. This leads to improved generalization capabilities to scenes with out-of-domain content.
Zero-Shot Image Compression with Diffusion-Based Posterior Sampling
Jul 13, 2024
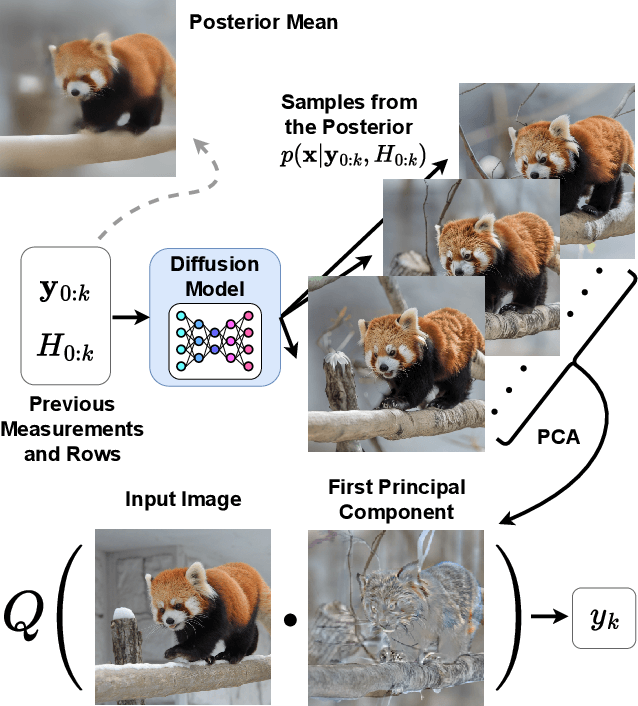
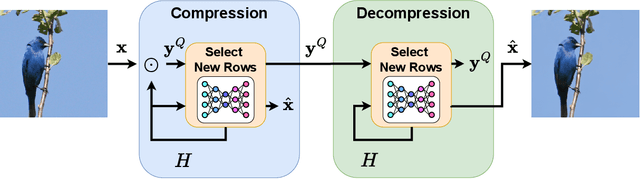

Diffusion models dominate the field of image generation, however they have yet to make major breakthroughs in the field of image compression. Indeed, while pre-trained diffusion models have been successfully adapted to a wide variety of downstream tasks, existing work in diffusion-based image compression require task specific model training, which can be both cumbersome and limiting. This work addresses this gap by harnessing the image prior learned by existing pre-trained diffusion models for solving the task of lossy image compression. This enables the use of the wide variety of publicly-available models, and avoids the need for training or fine-tuning. Our method, PSC (Posterior Sampling-based Compression), utilizes zero-shot diffusion-based posterior samplers. It does so through a novel sequential process inspired by the active acquisition technique "Adasense" to accumulate informative measurements of the image. This strategy minimizes uncertainty in the reconstructed image and allows for construction of an image-adaptive transform coordinated between both the encoder and decoder. PSC offers a progressive compression scheme that is both practical and simple to implement. Despite minimal tuning, and a simple quantization and entropy coding, PSC achieves competitive results compared to established methods, paving the way for further exploration of pre-trained diffusion models and posterior samplers for image compression.
Adaptive Compressed Sensing with Diffusion-Based Posterior Sampling
Jul 11, 2024



Compressed Sensing (CS) facilitates rapid image acquisition by selecting a small subset of measurements sufficient for high-fidelity reconstruction. Adaptive CS seeks to further enhance this process by dynamically choosing future measurements based on information gleaned from data that is already acquired. However, many existing frameworks are often tailored to specific tasks and require intricate training procedures. We propose AdaSense, a novel Adaptive CS approach that leverages zero-shot posterior sampling with pre-trained diffusion models. By sequentially sampling from the posterior distribution, we can quantify the uncertainty of each possible future linear measurement throughout the acquisition process. AdaSense eliminates the need for additional training and boasts seamless adaptation to diverse domains with minimal tuning requirements. Our experiments demonstrate the effectiveness of AdaSense in reconstructing facial images from a small number of measurements. Furthermore, we apply AdaSense for active acquisition of medical images in the domains of magnetic resonance imaging (MRI) and computed tomography (CT), highlighting its potential for tangible real-world acceleration.
Classification Diffusion Models
Feb 15, 2024



A prominent family of methods for learning data distributions relies on density ratio estimation (DRE), where a model is trained to $\textit{classify}$ between data samples and samples from some reference distribution. These techniques are successful in simple low-dimensional settings but fail to achieve good results on complex high-dimensional data, like images. A different family of methods for learning distributions is that of denoising diffusion models (DDMs), in which a model is trained to $\textit{denoise}$ data samples. These approaches achieve state-of-the-art results in image, video, and audio generation. In this work, we present $\textit{Classification Diffusion Models}$ (CDMs), a generative technique that adopts the denoising-based formalism of DDMs while making use of a classifier that predicts the amount of noise added to a clean signal, similarly to DRE methods. Our approach is based on the observation that an MSE-optimal denoiser for white Gaussian noise can be expressed in terms of the gradient of a cross-entropy-optimal classifier for predicting the noise level. As we illustrate, CDM achieves better denoising results compared to DDM, and leads to at least comparable FID in image generation. CDM is also capable of highly efficient one-step exact likelihood estimation, achieving state-of-the-art results among methods that use a single step. Code is available on the project's webpage in https://shaharYadin.github.io/CDM/ .
Nested Diffusion Processes for Anytime Image Generation
May 30, 2023Diffusion models are the current state-of-the-art in image generation, synthesizing high-quality images by breaking down the generation process into many fine-grained denoising steps. Despite their good performance, diffusion models are computationally expensive, requiring many neural function evaluations (NFEs). In this work, we propose an anytime diffusion-based method that can generate viable images when stopped at arbitrary times before completion. Using existing pretrained diffusion models, we show that the generation scheme can be recomposed as two nested diffusion processes, enabling fast iterative refinement of a generated image. We use this Nested Diffusion approach to peek into the generation process and enable flexible scheduling based on the instantaneous preference of the user. In experiments on ImageNet and Stable Diffusion-based text-to-image generation, we show, both qualitatively and quantitatively, that our method's intermediate generation quality greatly exceeds that of the original diffusion model, while the final slow generation result remains comparable.
GSURE-Based Diffusion Model Training with Corrupted Data
May 22, 2023Diffusion models have demonstrated impressive results in both data generation and downstream tasks such as inverse problems, text-based editing, classification, and more. However, training such models usually requires large amounts of clean signals which are often difficult or impossible to obtain. In this work, we propose a novel training technique for generative diffusion models based only on corrupted data. We introduce a loss function based on the Generalized Stein's Unbiased Risk Estimator (GSURE), and prove that under some conditions, it is equivalent to the training objective used in fully supervised diffusion models. We demonstrate our technique on face images as well as Magnetic Resonance Imaging (MRI), where the use of undersampled data significantly alleviates data collection costs. Our approach achieves generative performance comparable to its fully supervised counterpart without training on any clean signals. In addition, we deploy the resulting diffusion model in various downstream tasks beyond the degradation present in the training set, showcasing promising results.