 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn from Your Mistakes: Self-Correcting Masked Diffusion Models
Feb 12, 2026Masked diffusion models (MDMs) have emerged as a promising alternative to autoregressive models, enabling parallel token generation while achieving competitive performance. Despite these advantages, MDMs face a fundamental limitation: once tokens are unmasked, they remain fixed, leading to error accumulation and ultimately degrading sample quality. We address this by proposing a framework that trains a model to perform both unmasking and correction. By reusing outputs from the MDM denoising network as inputs for corrector training, we train a model to recover from potential mistakes. During generation we apply additional corrective refinement steps between unmasking ones in order to change decoded tokens and improve outputs. We name our training and sampling method Progressive Self-Correction (ProSeCo) for its unique ability to iteratively refine an entire sequence, including already generated tokens. We conduct extensive experimental validation across multiple conditional and unconditional tasks, demonstrating that ProSeCo yields better quality-efficiency trade-offs (up to ~2-3x faster sampling) and enables inference-time compute scaling to further increase sample quality beyond standard MDMs (up to ~1.3x improvement on benchmarks).
Analyzing and Guiding Zero-Shot Posterior Sampling in Diffusion Models
Feb 07, 2026Recovering a signal from its degraded measurements is a long standing challenge in science and engineering. Recently, zero-shot diffusion based methods have been proposed for such inverse problems, offering a posterior sampling based solution that leverages prior knowledge. Such algorithms incorporate the observations through inference, often leaning on manual tuning and heuristics. In this work we propose a rigorous analysis of such approximate posterior-samplers, relying on a Gaussianity assumption of the prior. Under this regime, we show that both the ideal posterior sampler and diffusion-based reconstruction algorithms can be expressed in closed-form, enabling their thorough analysis and comparisons in the spectral domain. Building on these representations, we also introduce a principled framework for parameter design, replacing heuristic selection strategies used to date. The proposed approach is method-agnostic and yields tailored parameter choices for each algorithm, jointly accounting for the characteristics of the prior, the degraded signal, and the diffusion dynamics. We show that our spectral recommendations differ structurally from standard heuristics and vary with the diffusion step size, resulting in a consistent balance between perceptual quality and signal fidelity.
Turbo-DDCM: Fast and Flexible Zero-Shot Diffusion-Based Image Compression
Nov 09, 2025While zero-shot diffusion-based compression methods have seen significant progress in recent years, they remain notoriously slow and computationally demanding. This paper presents an efficient zero-shot diffusion-based compression method that runs substantially faster than existing methods, while maintaining performance that is on par with the state-of-the-art techniques. Our method builds upon the recently proposed Denoising Diffusion Codebook Models (DDCMs) compression scheme. Specifically, DDCM compresses an image by sequentially choosing the diffusion noise vectors from reproducible random codebooks, guiding the denoiser's output to reconstruct the target image. We modify this framework with Turbo-DDCM, which efficiently combines a large number of noise vectors at each denoising step, thereby significantly reducing the number of required denoising operations. This modification is also coupled with an improved encoding protocol. Furthermore, we introduce two flexible variants of Turbo-DDCM, a priority-aware variant that prioritizes user-specified regions and a distortion-controlled variant that compresses an image based on a target PSNR rather than a target BPP. Comprehensive experiments position Turbo-DDCM as a compelling, practical, and flexible image compression scheme.
InvFussion: Bridging Supervised and Zero-shot Diffusion for Inverse Problems
Apr 02, 2025
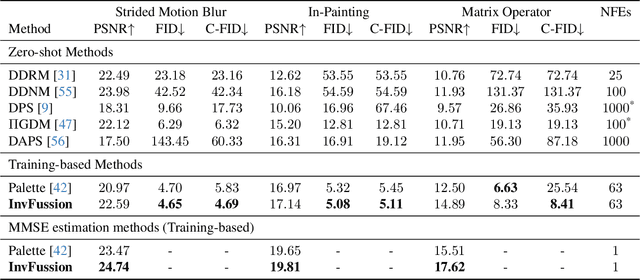

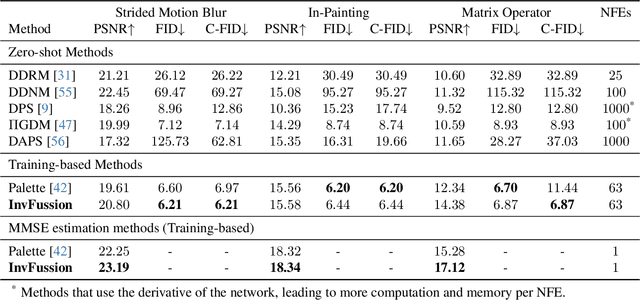
Diffusion Models have demonstrated remarkable capabilities in handling inverse problems, offering high-quality posterior-sampling-based solutions. Despite significant advances, a fundamental trade-off persists, regarding the way the conditioned synthesis is employed: Training-based methods achieve high quality results, while zero-shot approaches trade this with flexibility. This work introduces a framework that combines the best of both worlds -- the strong performance of supervised approaches and the flexibility of zero-shot methods. This is achieved through a novel architectural design that seamlessly integrates the degradation operator directly into the denoiser. In each block, our proposed architecture applies the degradation operator on the network activations and conditions the output using the attention mechanism, enabling adaptation to diverse degradation scenarios while maintaining high performance. Our work demonstrates the versatility of the proposed architecture, operating as a general MMSE estimator, a posterior sampler, or a Neural Posterior Principal Component estimator. This flexibility enables a wide range of downstream tasks, highlighting the broad applicability of our framework. The proposed modification of the denoiser network offers a versatile, accurate, and computationally efficient solution, demonstrating the advantages of dedicated network architectures for complex inverse problems. Experimental results on the FFHQ and ImageNet datasets demonstrate state-of-the-art posterior-sampling performance, surpassing both training-based and zero-shot alternatives.
Compressed Image Generation with Denoising Diffusion Codebook Models
Feb 04, 2025



We present a novel generative approach based on Denoising Diffusion Models (DDMs), which produces high-quality image samples along with their losslessly compressed bit-stream representations. This is obtained by replacing the standard Gaussian noise sampling in the reverse diffusion with a selection of noise samples from pre-defined codebooks of fixed iid Gaussian vectors. Surprisingly, we find that our method, termed Denoising Diffusion Codebook Model (DDCM), retains sample quality and diversity of standard DDMs, even for extremely small codebooks. We leverage DDCM and pick the noises from the codebooks that best match a given image, converting our generative model into a highly effective lossy image codec achieving state-of-the-art perceptual image compression results. More generally, by setting other noise selections rules, we extend our compression method to any conditional image generation task (e.g., image restoration), where the generated images are produced jointly with their condensed bit-stream representations. Our work is accompanied by a mathematical interpretation of the proposed compressed conditional generation schemes, establishing a connection with score-based approximations of posterior samplers for the tasks considered.
Proxies for Distortion and Consistency with Applications for Real-World Image Restoration
Jan 21, 2025Real-world image restoration deals with the recovery of images suffering from an unknown degradation. This task is typically addressed while being given only degraded images, without their corresponding ground-truth versions. In this hard setting, designing and evaluating restoration algorithms becomes highly challenging. This paper offers a suite of tools that can serve both the design and assessment of real-world image restoration algorithms. Our work starts by proposing a trained model that predicts the chain of degradations a given real-world measured input has gone through. We show how this estimator can be used to approximate the consistency -- the match between the measurements and any proposed recovered image. We also use this estimator as a guiding force for the design of a simple and highly-effective plug-and-play real-world image restoration algorithm, leveraging a pre-trained diffusion-based image prior. Furthermore, this work proposes no-reference proxy measures of MSE and LPIPS, which, without access to the ground-truth images, allow ranking of real-world image restoration algorithms according to their (approximate) MSE and LPIPS. The proposed suite provides a versatile, first of its kind framework for evaluating and comparing blind image restoration algorithms in real-world scenarios.
SILO: Solving Inverse Problems with Latent Operators
Jan 20, 2025



Consistent improvement of image priors over the years has led to the development of better inverse problem solvers. Diffusion models are the newcomers to this arena, posing the strongest known prior to date. Recently, such models operating in a latent space have become increasingly predominant due to their efficiency. In recent works, these models have been applied to solve inverse problems. Working in the latent space typically requires multiple applications of an Autoencoder during the restoration process, which leads to both computational and restoration quality challenges. In this work, we propose a new approach for handling inverse problems with latent diffusion models, where a learned degradation function operates within the latent space, emulating a known image space degradation. Usage of the learned operator reduces the dependency on the Autoencoder to only the initial and final steps of the restoration process, facilitating faster sampling and superior restoration quality. We demonstrate the effectiveness of our method on a variety of image restoration tasks and datasets, achieving significant improvements over prior art.
Posterior-Mean Rectified Flow: Towards Minimum MSE Photo-Realistic Image Restoration
Oct 01, 2024



Photo-realistic image restoration algorithms are typically evaluated by distortion measures (e.g., PSNR, SSIM) and by perceptual quality measures (e.g., FID, NIQE), where the desire is to attain the lowest possible distortion without compromising on perceptual quality. To achieve this goal, current methods typically attempt to sample from the posterior distribution, or to optimize a weighted sum of a distortion loss (e.g., MSE) and a perceptual quality loss (e.g., GAN). Unlike previous works, this paper is concerned specifically with the optimal estimator that minimizes the MSE under a constraint of perfect perceptual index, namely where the distribution of the reconstructed images is equal to that of the ground-truth ones. A recent theoretical result shows that such an estimator can be constructed by optimally transporting the posterior mean prediction (MMSE estimate) to the distribution of the ground-truth images. Inspired by this result, we introduce Posterior-Mean Rectified Flow (PMRF), a simple yet highly effective algorithm that approximates this optimal estimator. In particular, PMRF first predicts the posterior mean, and then transports the result to a high-quality image using a rectified flow model that approximates the desired optimal transport map. We investigate the theoretical utility of PMRF and demonstrate that it consistently outperforms previous methods on a variety of image restoration tasks.
Text-to-Image Generation Via Energy-Based CLIP
Aug 30, 2024



Joint Energy Models (JEMs), while drawing significant research attention, have not been successfully scaled to real-world, high-resolution datasets. We present EB-CLIP, a novel approach extending JEMs to the multimodal vision-language domain using CLIP, integrating both generative and discriminative objectives. For the generative objective, we introduce an image-text joint-energy function based on Cosine similarity in the CLIP space, training CLIP to assign low energy to real image-caption pairs and high energy otherwise. For the discriminative objective, we employ contrastive adversarial loss, extending the adversarial training objective to the multimodal domain. EB-CLIP not only generates realistic images from text but also achieves competitive results on the compositionality benchmark, outperforming leading methods with fewer parameters. Additionally, we demonstrate the superior guidance capability of EB-CLIP by enhancing CLIP-based generative frameworks and converting unconditional diffusion models to text-based ones. Lastly, we show that EB-CLIP can serve as a more robust evaluation metric for text-to-image generative tasks than CLIP.
Anchored Diffusion for Video Face Reenactment
Jul 21, 2024
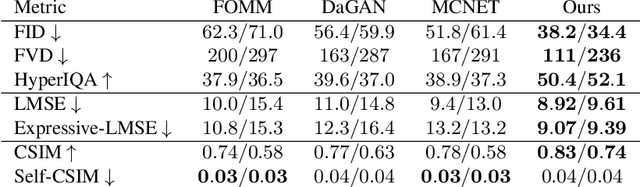
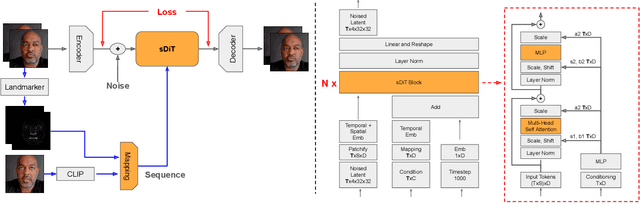

Video generation has drawn significant interest recently, pushing the development of large-scale models capable of producing realistic videos with coherent motion. Due to memory constraints, these models typically generate short video segments that are then combined into long videos. The merging process poses a significant challenge, as it requires ensuring smooth transitions and overall consistency. In this paper, we introduce Anchored Diffusion, a novel method for synthesizing relatively long and seamless videos. We extend Diffusion Transformers (DiTs) to incorporate temporal information, creating our sequence-DiT (sDiT) model for generating short video segments. Unlike previous works, we train our model on video sequences with random non-uniform temporal spacing and incorporate temporal information via external guidance, increasing flexibility and allowing it to capture both short and long-term relationships. Furthermore, during inference, we leverage the transformer architecture to modify the diffusion process, generating a batch of non-uniform sequences anchored to a common frame, ensuring consistency regardless of temporal distance. To demonstrate our method, we focus on face reenactment, the task of creating a video from a source image that replicates the facial expressions and movements from a driving video. Through comprehensive experiments, we show our approach outperforms current techniques in producing longer consistent high-quality videos while offering editing capabilities.