 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpanning the Visual Analogy Space with a Weight Basis of LoRAs
Feb 17, 2026Visual analogy learning enables image manipulation through demonstration rather than textual description, allowing users to specify complex transformations difficult to articulate in words. Given a triplet $\{\mathbf{a}$, $\mathbf{a}'$, $\mathbf{b}\}$, the goal is to generate $\mathbf{b}'$ such that $\mathbf{a} : \mathbf{a}' :: \mathbf{b} : \mathbf{b}'$. Recent methods adapt text-to-image models to this task using a single Low-Rank Adaptation (LoRA) module, but they face a fundamental limitation: attempting to capture the diverse space of visual transformations within a fixed adaptation module constrains generalization capabilities. Inspired by recent work showing that LoRAs in constrained domains span meaningful, interpolatable semantic spaces, we propose LoRWeB, a novel approach that specializes the model for each analogy task at inference time through dynamic composition of learned transformation primitives, informally, choosing a point in a "space of LoRAs". We introduce two key components: (1) a learnable basis of LoRA modules, to span the space of different visual transformations, and (2) a lightweight encoder that dynamically selects and weighs these basis LoRAs based on the input analogy pair. Comprehensive evaluations demonstrate our approach achieves state-of-the-art performance and significantly improves generalization to unseen visual transformations. Our findings suggest that LoRA basis decompositions are a promising direction for flexible visual manipulation. Code and data are in https://research.nvidia.com/labs/par/lorweb
Turbo-DDCM: Fast and Flexible Zero-Shot Diffusion-Based Image Compression
Nov 09, 2025While zero-shot diffusion-based compression methods have seen significant progress in recent years, they remain notoriously slow and computationally demanding. This paper presents an efficient zero-shot diffusion-based compression method that runs substantially faster than existing methods, while maintaining performance that is on par with the state-of-the-art techniques. Our method builds upon the recently proposed Denoising Diffusion Codebook Models (DDCMs) compression scheme. Specifically, DDCM compresses an image by sequentially choosing the diffusion noise vectors from reproducible random codebooks, guiding the denoiser's output to reconstruct the target image. We modify this framework with Turbo-DDCM, which efficiently combines a large number of noise vectors at each denoising step, thereby significantly reducing the number of required denoising operations. This modification is also coupled with an improved encoding protocol. Furthermore, we introduce two flexible variants of Turbo-DDCM, a priority-aware variant that prioritizes user-specified regions and a distortion-controlled variant that compresses an image based on a target PSNR rather than a target BPP. Comprehensive experiments position Turbo-DDCM as a compelling, practical, and flexible image compression scheme.
When Diffusion Models Memorize: Inductive Biases in Probability Flow of Minimum-Norm Shallow Neural Nets
Jun 23, 2025While diffusion models generate high-quality images via probability flow, the theoretical understanding of this process remains incomplete. A key question is when probability flow converges to training samples or more general points on the data manifold. We analyze this by studying the probability flow of shallow ReLU neural network denoisers trained with minimal $\ell^2$ norm. For intuition, we introduce a simpler score flow and show that for orthogonal datasets, both flows follow similar trajectories, converging to a training point or a sum of training points. However, early stopping by the diffusion time scheduler allows probability flow to reach more general manifold points. This reflects the tendency of diffusion models to both memorize training samples and generate novel points that combine aspects of multiple samples, motivating our study of such behavior in simplified settings. We extend these results to obtuse simplex data and, through simulations in the orthogonal case, confirm that probability flow converges to a training point, a sum of training points, or a manifold point. Moreover, memorization decreases when the number of training samples grows, as fewer samples accumulate near training points.
Compressed Image Generation with Denoising Diffusion Codebook Models
Feb 04, 2025



We present a novel generative approach based on Denoising Diffusion Models (DDMs), which produces high-quality image samples along with their losslessly compressed bit-stream representations. This is obtained by replacing the standard Gaussian noise sampling in the reverse diffusion with a selection of noise samples from pre-defined codebooks of fixed iid Gaussian vectors. Surprisingly, we find that our method, termed Denoising Diffusion Codebook Model (DDCM), retains sample quality and diversity of standard DDMs, even for extremely small codebooks. We leverage DDCM and pick the noises from the codebooks that best match a given image, converting our generative model into a highly effective lossy image codec achieving state-of-the-art perceptual image compression results. More generally, by setting other noise selections rules, we extend our compression method to any conditional image generation task (e.g., image restoration), where the generated images are produced jointly with their condensed bit-stream representations. Our work is accompanied by a mathematical interpretation of the proposed compressed conditional generation schemes, establishing a connection with score-based approximations of posterior samplers for the tasks considered.
Zero-Shot Unsupervised and Text-Based Audio Editing Using DDPM Inversion
Feb 25, 2024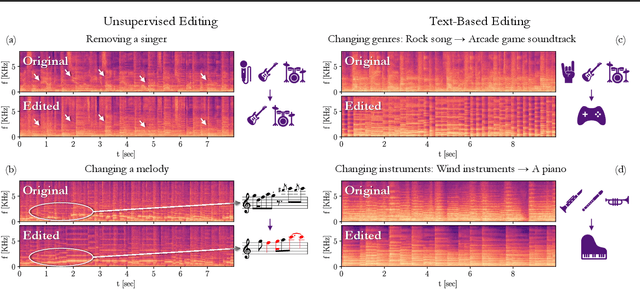
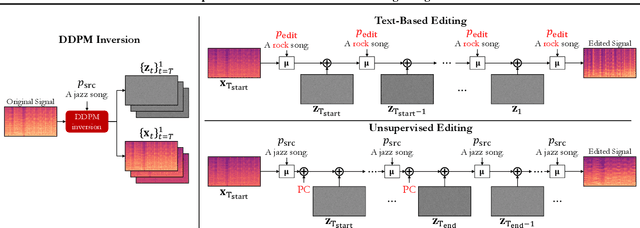
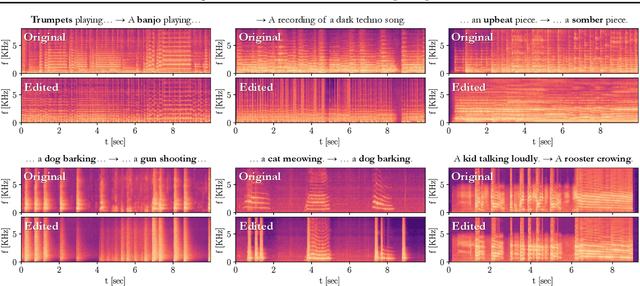
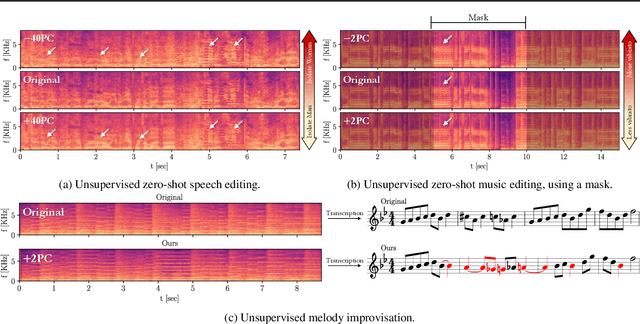
Editing signals using large pre-trained models, in a zero-shot manner, has recently seen rapid advancements in the image domain. However, this wave has yet to reach the audio domain. In this paper, we explore two zero-shot editing techniques for audio signals, which use DDPM inversion on pre-trained diffusion models. The first, adopted from the image domain, allows text-based editing. The second, is a novel approach for discovering semantically meaningful editing directions without supervision. When applied to music signals, this method exposes a range of musically interesting modifications, from controlling the participation of specific instruments to improvisations on the melody. Samples and code can be found on our examples page in https://hilamanor.github.io/AudioEditing/ .
From Posterior Sampling to Meaningful Diversity in Image Restoration
Oct 24, 2023
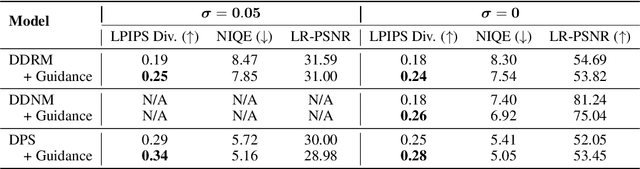
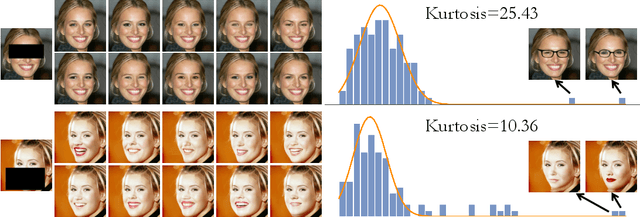
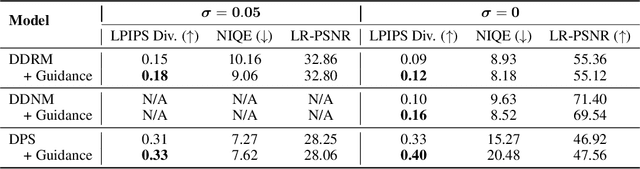
Image restoration problems are typically ill-posed in the sense that each degraded image can be restored in infinitely many valid ways. To accommodate this, many works generate a diverse set of outputs by attempting to randomly sample from the posterior distribution of natural images given the degraded input. Here we argue that this strategy is commonly of limited practical value because of the heavy tail of the posterior distribution. Consider for example inpainting a missing region of the sky in an image. Since there is a high probability that the missing region contains no object but clouds, any set of samples from the posterior would be entirely dominated by (practically identical) completions of sky. However, arguably, presenting users with only one clear sky completion, along with several alternative solutions such as airships, birds, and balloons, would better outline the set of possibilities. In this paper, we initiate the study of meaningfully diverse image restoration. We explore several post-processing approaches that can be combined with any diverse image restoration method to yield semantically meaningful diversity. Moreover, we propose a practical approach for allowing diffusion based image restoration methods to generate meaningfully diverse outputs, while incurring only negligent computational overhead. We conduct extensive user studies to analyze the proposed techniques, and find the strategy of reducing similarity between outputs to be significantly favorable over posterior sampling. Code and examples are available in https://noa-cohen.github.io/MeaningfulDiversityInIR
On the Posterior Distribution in Denoising: Application to Uncertainty Quantification
Sep 24, 2023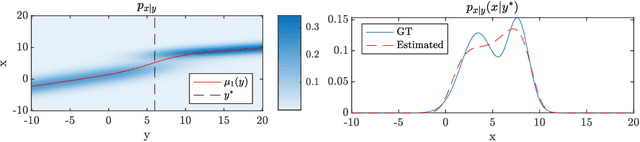
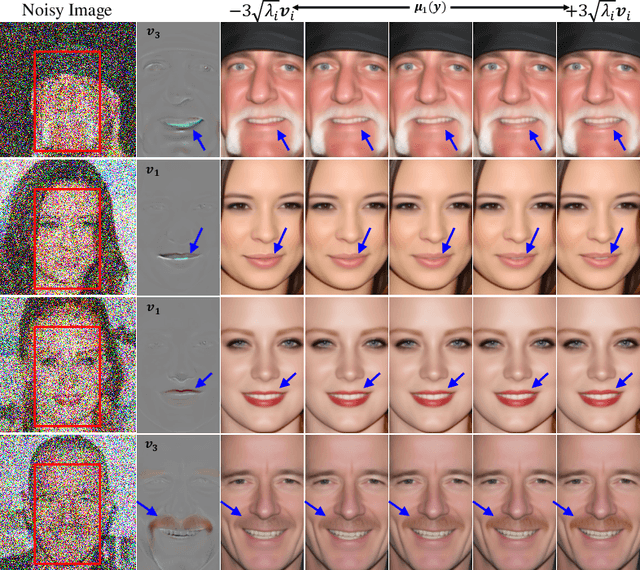
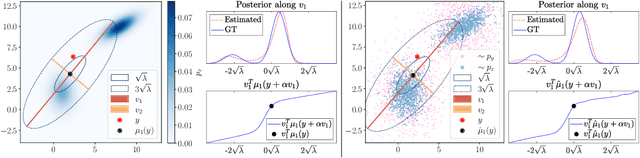
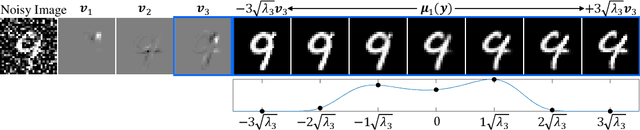
Denoisers play a central role in many applications, from noise suppression in low-grade imaging sensors, to empowering score-based generative models. The latter category of methods makes use of Tweedie's formula, which links the posterior mean in Gaussian denoising (i.e., the minimum MSE denoiser) with the score of the data distribution. Here, we derive a fundamental relation between the higher-order central moments of the posterior distribution, and the higher-order derivatives of the posterior mean. We harness this result for uncertainty quantification of pre-trained denoisers. Particularly, we show how to efficiently compute the principal components of the posterior distribution for any desired region of an image, as well as to approximate the full marginal distribution along those (or any other) one-dimensional directions. Our method is fast and memory efficient, as it does not explicitly compute or store the high-order moment tensors and it requires no training or fine tuning of the denoiser. Code and examples are available on the project's webpage in https://hilamanor.github.io/GaussianDenoisingPosterior/