 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurbo-DDCM: Fast and Flexible Zero-Shot Diffusion-Based Image Compression
Nov 09, 2025While zero-shot diffusion-based compression methods have seen significant progress in recent years, they remain notoriously slow and computationally demanding. This paper presents an efficient zero-shot diffusion-based compression method that runs substantially faster than existing methods, while maintaining performance that is on par with the state-of-the-art techniques. Our method builds upon the recently proposed Denoising Diffusion Codebook Models (DDCMs) compression scheme. Specifically, DDCM compresses an image by sequentially choosing the diffusion noise vectors from reproducible random codebooks, guiding the denoiser's output to reconstruct the target image. We modify this framework with Turbo-DDCM, which efficiently combines a large number of noise vectors at each denoising step, thereby significantly reducing the number of required denoising operations. This modification is also coupled with an improved encoding protocol. Furthermore, we introduce two flexible variants of Turbo-DDCM, a priority-aware variant that prioritizes user-specified regions and a distortion-controlled variant that compresses an image based on a target PSNR rather than a target BPP. Comprehensive experiments position Turbo-DDCM as a compelling, practical, and flexible image compression scheme.
Compressed Image Generation with Denoising Diffusion Codebook Models
Feb 04, 2025



We present a novel generative approach based on Denoising Diffusion Models (DDMs), which produces high-quality image samples along with their losslessly compressed bit-stream representations. This is obtained by replacing the standard Gaussian noise sampling in the reverse diffusion with a selection of noise samples from pre-defined codebooks of fixed iid Gaussian vectors. Surprisingly, we find that our method, termed Denoising Diffusion Codebook Model (DDCM), retains sample quality and diversity of standard DDMs, even for extremely small codebooks. We leverage DDCM and pick the noises from the codebooks that best match a given image, converting our generative model into a highly effective lossy image codec achieving state-of-the-art perceptual image compression results. More generally, by setting other noise selections rules, we extend our compression method to any conditional image generation task (e.g., image restoration), where the generated images are produced jointly with their condensed bit-stream representations. Our work is accompanied by a mathematical interpretation of the proposed compressed conditional generation schemes, establishing a connection with score-based approximations of posterior samplers for the tasks considered.
Proxies for Distortion and Consistency with Applications for Real-World Image Restoration
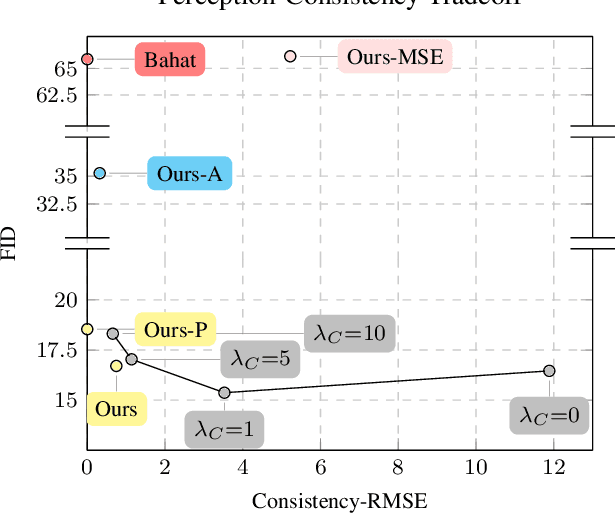
Jan 21, 2025Real-world image restoration deals with the recovery of images suffering from an unknown degradation. This task is typically addressed while being given only degraded images, without their corresponding ground-truth versions. In this hard setting, designing and evaluating restoration algorithms becomes highly challenging. This paper offers a suite of tools that can serve both the design and assessment of real-world image restoration algorithms. Our work starts by proposing a trained model that predicts the chain of degradations a given real-world measured input has gone through. We show how this estimator can be used to approximate the consistency -- the match between the measurements and any proposed recovered image. We also use this estimator as a guiding force for the design of a simple and highly-effective plug-and-play real-world image restoration algorithm, leveraging a pre-trained diffusion-based image prior. Furthermore, this work proposes no-reference proxy measures of MSE and LPIPS, which, without access to the ground-truth images, allow ranking of real-world image restoration algorithms according to their (approximate) MSE and LPIPS. The proposed suite provides a versatile, first of its kind framework for evaluating and comparing blind image restoration algorithms in real-world scenarios.
Posterior-Mean Rectified Flow: Towards Minimum MSE Photo-Realistic Image Restoration
Oct 01, 2024



Photo-realistic image restoration algorithms are typically evaluated by distortion measures (e.g., PSNR, SSIM) and by perceptual quality measures (e.g., FID, NIQE), where the desire is to attain the lowest possible distortion without compromising on perceptual quality. To achieve this goal, current methods typically attempt to sample from the posterior distribution, or to optimize a weighted sum of a distortion loss (e.g., MSE) and a perceptual quality loss (e.g., GAN). Unlike previous works, this paper is concerned specifically with the optimal estimator that minimizes the MSE under a constraint of perfect perceptual index, namely where the distribution of the reconstructed images is equal to that of the ground-truth ones. A recent theoretical result shows that such an estimator can be constructed by optimally transporting the posterior mean prediction (MMSE estimate) to the distribution of the ground-truth images. Inspired by this result, we introduce Posterior-Mean Rectified Flow (PMRF), a simple yet highly effective algorithm that approximates this optimal estimator. In particular, PMRF first predicts the posterior mean, and then transports the result to a high-quality image using a rectified flow model that approximates the desired optimal transport map. We investigate the theoretical utility of PMRF and demonstrate that it consistently outperforms previous methods on a variety of image restoration tasks.
Perceptual Fairness in Image Restoration
May 22, 2024Fairness in image restoration tasks is the desire to treat different sub-groups of images equally well. Existing definitions of fairness in image restoration are highly restrictive. They consider a reconstruction to be a correct outcome for a group (e.g., women) only if it falls within the group's set of ground truth images (e.g., natural images of women); otherwise, it is considered entirely incorrect. Consequently, such definitions are prone to controversy, as errors in image restoration can manifest in various ways. In this work we offer an alternative approach towards fairness in image restoration, by considering the Group Perceptual Index (GPI), which we define as the statistical distance between the distribution of the group's ground truth images and the distribution of their reconstructions. We assess the fairness of an algorithm by comparing the GPI of different groups, and say that it achieves perfect Perceptual Fairness (PF) if the GPIs of all groups are identical. We motivate and theoretically study our new notion of fairness, draw its connection to previous ones, and demonstrate its utility on state-of-the-art face image super-resolution algorithms.
The Perception-Robustness Tradeoff in Deterministic Image Restoration
Nov 14, 2023



We study the behavior of deterministic methods for solving inverse problems in imaging. These methods are commonly designed to achieve two goals: (1) attaining high perceptual quality, and (2) generating reconstructions that are consistent with the measurements. We provide a rigorous proof that the better a predictor satisfies these two requirements, the larger its Lipschitz constant must be, regardless of the nature of the degradation involved. In particular, to approach perfect perceptual quality and perfect consistency, the Lipschitz constant of the model must grow to infinity. This implies that such methods are necessarily more susceptible to adversarial attacks. We demonstrate our theory on single image super-resolution algorithms, addressing both noisy and noiseless settings. We also show how this undesired behavior can be leveraged to explore the posterior distribution, thereby allowing the deterministic model to imitate stochastic methods.
Deep Optimal Transport: A Practical Algorithm for Photo-realistic Image Restoration
Jun 04, 2023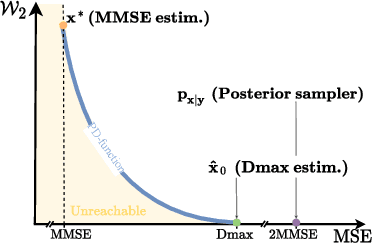
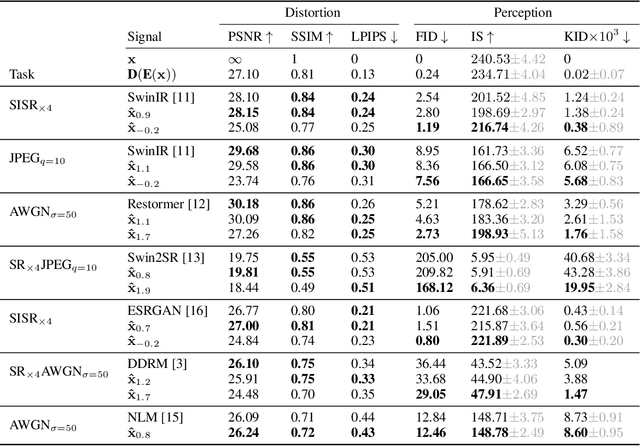

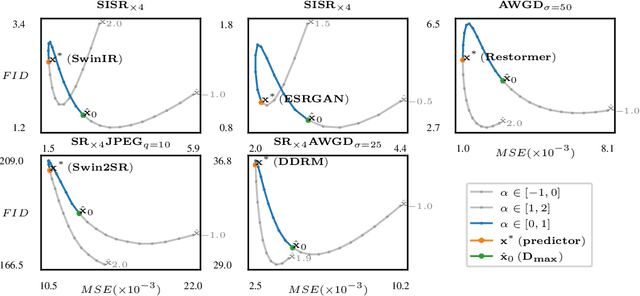
We propose an image restoration algorithm that can control the perceptual quality and/or the mean square error (MSE) of any pre-trained model, trading one over the other at test time. Our algorithm is few-shot: Given about a dozen images restored by the model, it can significantly improve the perceptual quality and/or the MSE of the model for newly restored images without further training. Our approach is motivated by a recent theoretical result that links between the minimum MSE (MMSE) predictor and the predictor that minimizes the MSE under a perfect perceptual quality constraint. Specifically, it has been shown that the latter can be obtained by optimally transporting the output of the former, such that its distribution matches the source data. Thus, to improve the perceptual quality of a predictor that was originally trained to minimize MSE, we approximate the optimal transport by a linear transformation in the latent space of a variational auto-encoder, which we compute in closed-form using empirical means and covariances. Going beyond the theory, we find that applying the same procedure on models that were initially trained to achieve high perceptual quality, typically improves their perceptual quality even further. And by interpolating the results with the original output of the model, we can improve their MSE on the expense of perceptual quality. We illustrate our method on a variety of degradations applied to general content images of arbitrary dimensions.
High-Perceptual Quality JPEG Decoding via Posterior Sampling
Nov 21, 2022
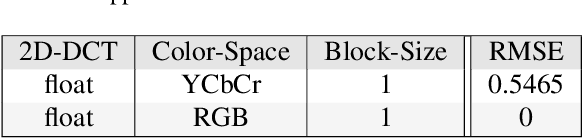
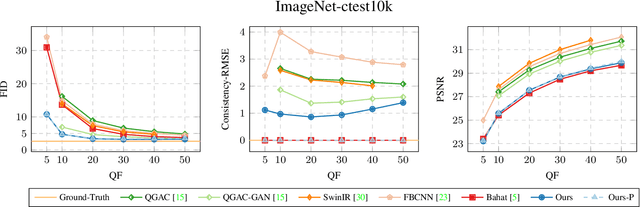
JPEG is arguably the most popular image coding format, achieving high compression ratios via lossy quantization that may create visual artifacts degradation. Numerous attempts to remove these artifacts were conceived over the years, and common to most of these is the use of deterministic post-processing algorithms that optimize some distortion measure (e.g., PSNR, SSIM). In this paper we propose a different paradigm for JPEG artifact correction: Our method is stochastic, and the objective we target is high perceptual quality -- striving to obtain sharp, detailed and visually pleasing reconstructed images, while being consistent with the compressed input. These goals are achieved by training a stochastic conditional generator (conditioned on the compressed input), accompanied by a theoretically well-founded loss term, resulting in a sampler from the posterior distribution. Our solution offers a diverse set of plausible and fast reconstructions for a given input with perfect consistency. We demonstrate our scheme's unique properties and its superiority to a variety of alternative methods on the FFHQ and ImageNet datasets.
Reasons for the Superiority of Stochastic Estimators over Deterministic Ones: Robustness, Consistency and Perceptual Quality
Nov 17, 2022



Stochastic restoration algorithms allow to explore the space of solutions that correspond to the degraded input. In this paper we reveal additional fundamental advantages of stochastic methods over deterministic ones, which further motivate their use. First, we prove that any restoration algorithm that attains perfect perceptual quality and whose outputs are consistent with the input must be a posterior sampler, and is thus required to be stochastic. Second, we illustrate that while deterministic restoration algorithms may attain high perceptual quality, this can be achieved only by filling up the space of all possible source images using an extremely sensitive mapping, which makes them highly vulnerable to adversarial attacks. Indeed, we show that enforcing deterministic models to be robust to such attacks profoundly hinders their perceptual quality, while robustifying stochastic models hardly influences their perceptual quality, and improves their output variability. These findings provide a motivation to foster progress in stochastic restoration methods, paving the way to better recovery algorithms.
High Perceptual Quality Image Denoising with a Posterior Sampling CGAN
Mar 17, 2021
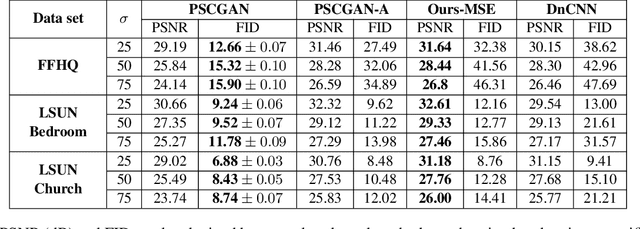

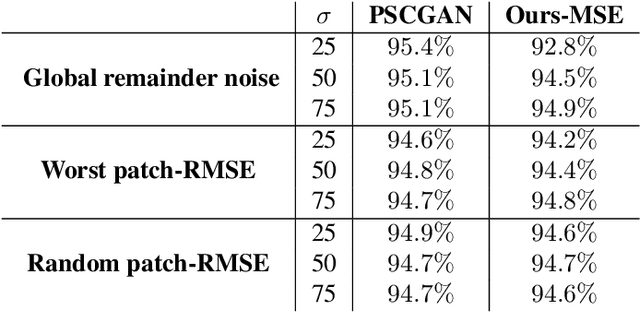
The vast work in Deep Learning (DL) has led to a leap in image denoising research. Most DL solutions for this task have chosen to put their efforts on the denoiser's architecture while maximizing distortion performance. However, distortion driven solutions lead to blurry results with sub-optimal perceptual quality, especially in immoderate noise levels. In this paper we propose a different perspective, aiming to produce sharp and visually pleasing denoised images that are still faithful to their clean sources. Formally, our goal is to achieve high perceptual quality with acceptable distortion. This is attained by a stochastic denoiser that samples from the posterior distribution, trained as a generator in the framework of conditional generative adversarial networks (CGAN). Contrary to distortion-based regularization terms that conflict with perceptual quality, we introduce to the CGAN objective a theoretically founded penalty term that does not force a distortion requirement on individual samples, but rather on their mean. We showcase our proposed method with a novel denoiser architecture that achieves the reformed denoising goal and produces vivid and diverse outcomes in immoderate noise levels.