 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Costs in Data Science: Foundations and the Quasi-Banach Spaces of Deep Neural Networks
Jun 16, 2026We develop a general framework for analyzing representation costs of parametric data-fitting methods through their parameter-space regularizers. From this abstract perspective, we define representation costs for arbitrary parametric models and reveal their induced (native) function spaces. This unifies recent function-space views of data-fitting methods. We also prove that many natural results hold in this abstract setting, including representer theorems for parametric methods on their native spaces. The framework also rigorously connects parametric methods with their equivalent nonparametric descriptions under sufficient overparameterization. Classical methods and their native spaces, such as kernel methods / reproducing kernel Hilbert spaces, wavelets / Besov spaces, and shallow neural networks / variation spaces emerge as special cases of our abstract framework. A byproduct of "axiomatizing" the study of representation costs is that we also immediately obtain new results for deep neural networks: For depth-$L$ feedforward ReLU networks, their induced native spaces are $p$-normable quasi-Banach spaces with $p = 2/L$. This reveals that the inductive bias of deep neural networks (as given by the representation cost) cannot be captured by norms for depths $L > 2$.
When Diffusion Models Memorize: Inductive Biases in Probability Flow of Minimum-Norm Shallow Neural Nets
Jun 23, 2025While diffusion models generate high-quality images via probability flow, the theoretical understanding of this process remains incomplete. A key question is when probability flow converges to training samples or more general points on the data manifold. We analyze this by studying the probability flow of shallow ReLU neural network denoisers trained with minimal $\ell^2$ norm. For intuition, we introduce a simpler score flow and show that for orthogonal datasets, both flows follow similar trajectories, converging to a training point or a sum of training points. However, early stopping by the diffusion time scheduler allows probability flow to reach more general manifold points. This reflects the tendency of diffusion models to both memorize training samples and generate novel points that combine aspects of multiple samples, motivating our study of such behavior in simplified settings. We extend these results to obtuse simplex data and, through simulations in the orthogonal case, confirm that probability flow converges to a training point, a sum of training points, or a manifold point. Moreover, memorization decreases when the number of training samples grows, as fewer samples accumulate near training points.
Depth Separation in Norm-Bounded Infinite-Width Neural Networks
Feb 13, 2024We study depth separation in infinite-width neural networks, where complexity is controlled by the overall squared $\ell_2$-norm of the weights (sum of squares of all weights in the network). Whereas previous depth separation results focused on separation in terms of width, such results do not give insight into whether depth determines if it is possible to learn a network that generalizes well even when the network width is unbounded. Here, we study separation in terms of the sample complexity required for learnability. Specifically, we show that there are functions that are learnable with sample complexity polynomial in the input dimension by norm-controlled depth-3 ReLU networks, yet are not learnable with sub-exponential sample complexity by norm-controlled depth-2 ReLU networks (with any value for the norm). We also show that a similar statement in the reverse direction is not possible: any function learnable with polynomial sample complexity by a norm-controlled depth-2 ReLU network with infinite width is also learnable with polynomial sample complexity by a norm-controlled depth-3 ReLU network.
How do Minimum-Norm Shallow Denoisers Look in Function Space?
Nov 12, 2023



Neural network (NN) denoisers are an essential building block in many common tasks, ranging from image reconstruction to image generation. However, the success of these models is not well understood from a theoretical perspective. In this paper, we aim to characterize the functions realized by shallow ReLU NN denoisers -- in the common theoretical setting of interpolation (i.e., zero training loss) with a minimal representation cost (i.e., minimal $\ell^2$ norm weights). First, for univariate data, we derive a closed form for the NN denoiser function, find it is contractive toward the clean data points, and prove it generalizes better than the empirical MMSE estimator at a low noise level. Next, for multivariate data, we find the NN denoiser functions in a closed form under various geometric assumptions on the training data: data contained in a low-dimensional subspace, data contained in a union of one-sided rays, or several types of simplexes. These functions decompose into a sum of simple rank-one piecewise linear interpolations aligned with edges and/or faces connecting training samples. We empirically verify this alignment phenomenon on synthetic data and real images.
The Implicit Bias of Minima Stability in Multivariate Shallow ReLU Networks
Jun 30, 2023We study the type of solutions to which stochastic gradient descent converges when used to train a single hidden-layer multivariate ReLU network with the quadratic loss. Our results are based on a dynamical stability analysis. In the univariate case, it was shown that linearly stable minima correspond to network functions (predictors), whose second derivative has a bounded weighted $L^1$ norm. Notably, the bound gets smaller as the step size increases, implying that training with a large step size leads to `smoother' predictors. Here we generalize this result to the multivariate case, showing that a similar result applies to the Laplacian of the predictor. We demonstrate the tightness of our bound on the MNIST dataset, and show that it accurately captures the behavior of the solutions as a function of the step size. Additionally, we prove a depth separation result on the approximation power of ReLU networks corresponding to stable minima of the loss. Specifically, although shallow ReLU networks are universal approximators, we prove that stable shallow networks are not. Namely, there is a function that cannot be well-approximated by stable single hidden-layer ReLU networks trained with a non-vanishing step size. This is while the same function can be realized as a stable two hidden-layer ReLU network. Finally, we prove that if a function is sufficiently smooth (in a Sobolev sense) then it can be approximated arbitrarily well using shallow ReLU networks that correspond to stable solutions of gradient descent.
Linear Neural Network Layers Promote Learning Single- and Multiple-Index Models
May 24, 2023This paper explores the implicit bias of overparameterized neural networks of depth greater than two layers. Our framework considers a family of networks of varying depths that all have the same capacity but different implicitly defined representation costs. The representation cost of a function induced by a neural network architecture is the minimum sum of squared weights needed for the network to represent the function; it reflects the function space bias associated with the architecture. Our results show that adding linear layers to a ReLU network yields a representation cost that favors functions that can be approximated by a low-rank linear operator composed with a function with low representation cost using a two-layer network. Specifically, using a neural network to fit training data with minimum representation cost yields an interpolating function that is nearly constant in directions orthogonal to a low-dimensional subspace. This means that the learned network will approximately be a single- or multiple-index model. Our experiments show that when this active subspace structure exists in the data, adding linear layers can improve generalization and result in a network that is well-aligned with the true active subspace.
The Role of Linear Layers in Nonlinear Interpolating Networks
Feb 02, 2022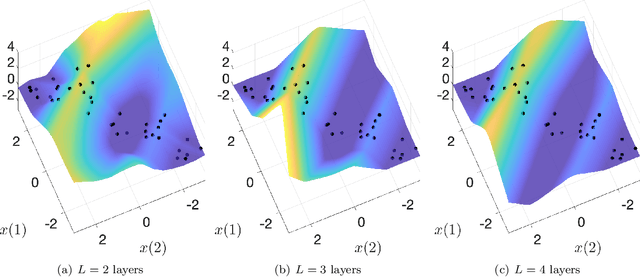
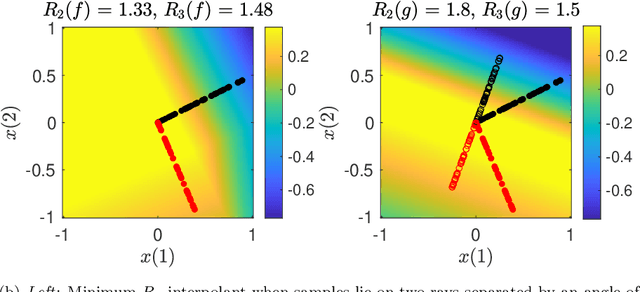
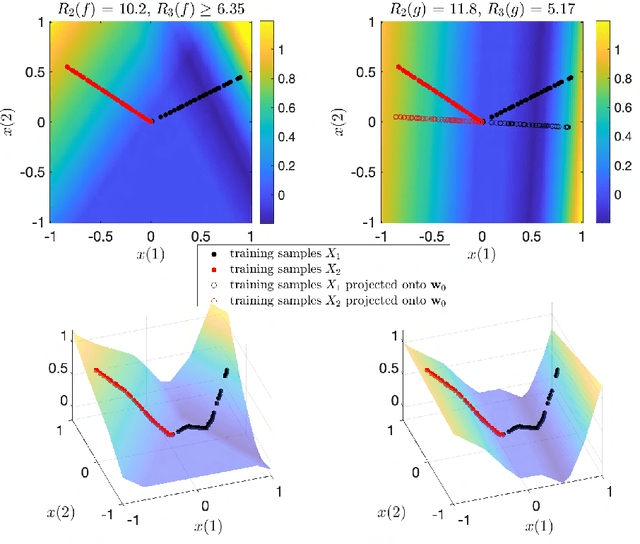
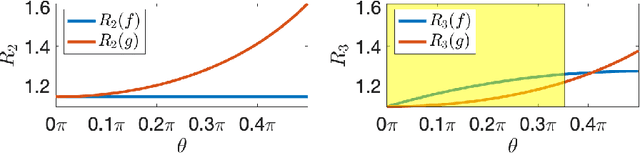
This paper explores the implicit bias of overparameterized neural networks of depth greater than two layers. Our framework considers a family of networks of varying depth that all have the same capacity but different implicitly defined representation costs. The representation cost of a function induced by a neural network architecture is the minimum sum of squared weights needed for the network to represent the function; it reflects the function space bias associated with the architecture. Our results show that adding linear layers to a ReLU network yields a representation cost that reflects a complex interplay between the alignment and sparsity of ReLU units. Specifically, using a neural network to fit training data with minimum representation cost yields an interpolating function that is constant in directions perpendicular to a low-dimensional subspace on which a parsimonious interpolant exists.
A Function Space View of Bounded Norm Infinite Width ReLU Nets: The Multivariate Case
Oct 03, 2019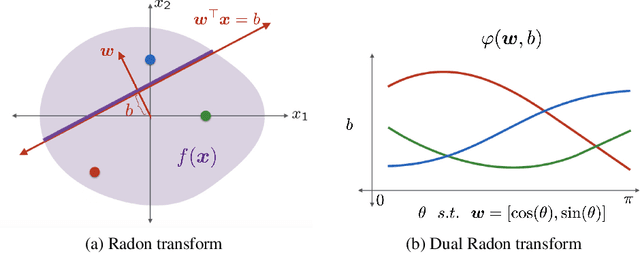
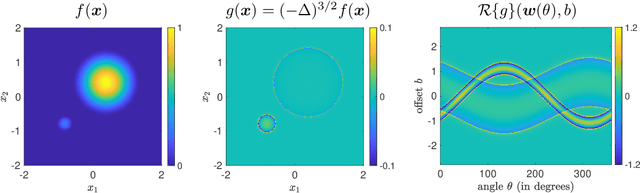
A key element of understanding the efficacy of overparameterized neural networks is characterizing how they represent functions as the number of weights in the network approaches infinity. In this paper, we characterize the norm required to realize a function $f:\mathbb{R}^d\rightarrow\mathbb{R}$ as a single hidden-layer ReLU network with an unbounded number of units (infinite width), but where the Euclidean norm of the weights is bounded, including precisely characterizing which functions can be realized with finite norm. This was settled for univariate univariate functions in Savarese et al. (2019), where it was shown that the required norm is determined by the L1-norm of the second derivative of the function. We extend the characterization to multivariate functions (i.e., networks with d input units), relating the required norm to the L1-norm of the Radon transform of a (d+1)/2-power Laplacian of the function. This characterization allows us to show that all functions in Sobolev spaces $W^{s,1}(\mathbb{R})$, $s\geq d+1$, can be represented with bounded norm, to calculate the required norm for several specific functions, and to obtain a depth separation result. These results have important implications for understanding generalization performance and the distinction between neural networks and more traditional kernel learning.
Neumann Networks for Inverse Problems in Imaging
Jan 13, 2019
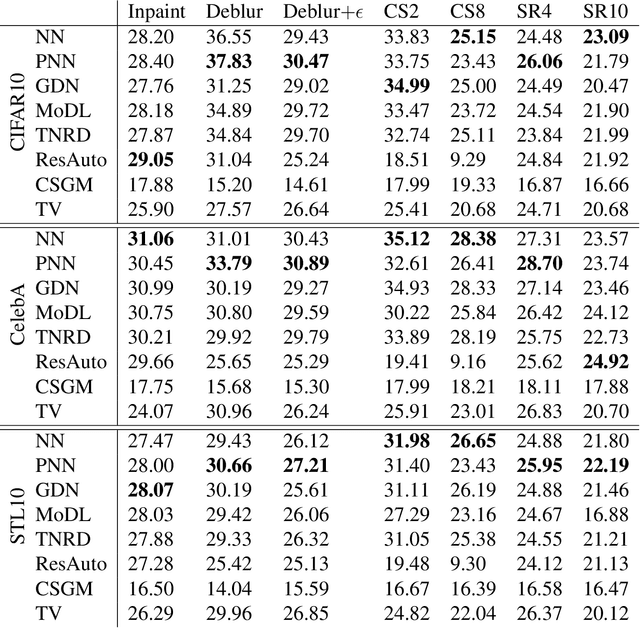
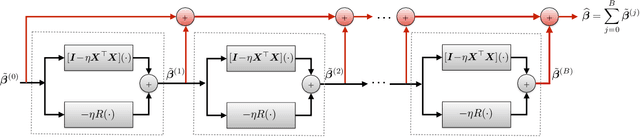

Many challenging image processing tasks can be described by an ill-posed linear inverse problem: deblurring, deconvolution, inpainting, compressed sensing, and superresolution all lie in this framework. Traditional inverse problem solvers minimize a cost function consisting of a data-fit term, which measures how well an image matches the observations, and a regularizer, which reflects prior knowledge and promotes images with desirable properties like smoothness. Recent advances in machine learning and image processing have illustrated that it is often possible to learn a regularizer from training data that can outperform more traditional regularizers. We present an end-to-end, data-driven method of solving inverse problems inspired by the Neumann series, which we call a Neumann network. Rather than unroll an iterative optimization algorithm, we truncate a Neumann series which directly solves the linear inverse problem with a data-driven nonlinear regularizer. The Neumann network architecture outperforms traditional inverse problem solution methods, model-free deep learning approaches, and state-of-the-art unrolled iterative methods on standard datasets. Finally, when the images belong to a union of subspaces and under appropriate assumptions on the forward model, we prove there exists a Neumann network configuration that well-approximates the optimal oracle estimator for the inverse problem and demonstrate empirically that the trained Neumann network has the form predicted by theory.
Tensor Methods for Nonlinear Matrix Completion
Apr 26, 2018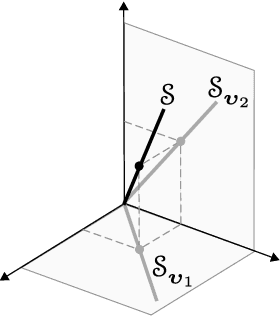


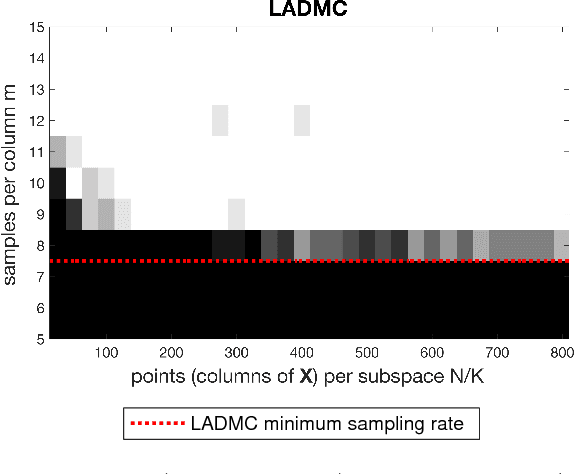
In the low rank matrix completion (LRMC) problem, the low rank assumption means that the columns (or rows) of the matrix to be completed are points on a low-dimensional linear algebraic variety. This paper extends this thinking to cases where the columns are points on a low-dimensional nonlinear algebraic variety, a problem we call Low Algebraic Dimension Matrix Completion (LADMC). Matrices whose columns belong to a union of subspaces (UoS) are an important special case. We propose a LADMC algorithm that leverages existing LRMC methods on a tensorized representation of the data. For example, a second-order tensorization representation is formed by taking the outer product of each column with itself, and we consider higher order tensorizations as well. This approach will succeed in many cases where traditional LRMC is guaranteed to fail because the data are low-rank in the tensorized representation but not in the original representation. We also provide a formal mathematical justification for the success of our method. In particular, we show bounds of the rank of these data in the tensorized representation, and we prove sampling requirements to guarantee uniqueness of the solution. Interestingly, the sampling requirements of our LADMC algorithm nearly match the information theoretic lower bounds for matrix completion under a UoS model. We also provide experimental results showing that the new approach significantly outperforms existing state-of-the-art methods for matrix completion in many situations.