 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked LARk: Masked Learning, Aggregation and Reporting worKflow
Oct 27, 2021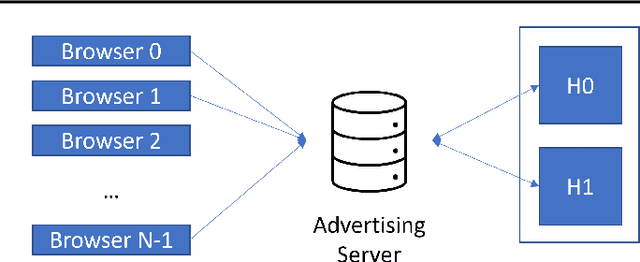
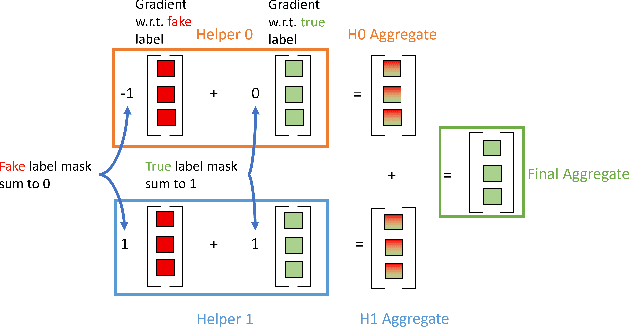
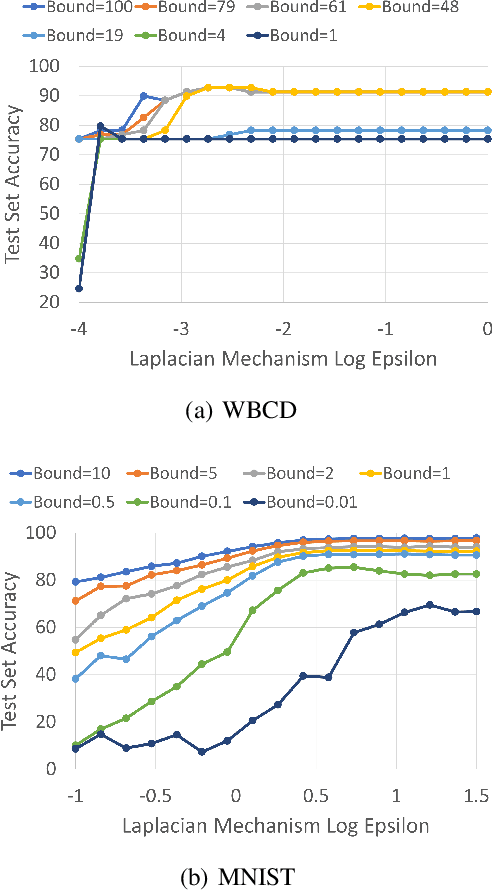
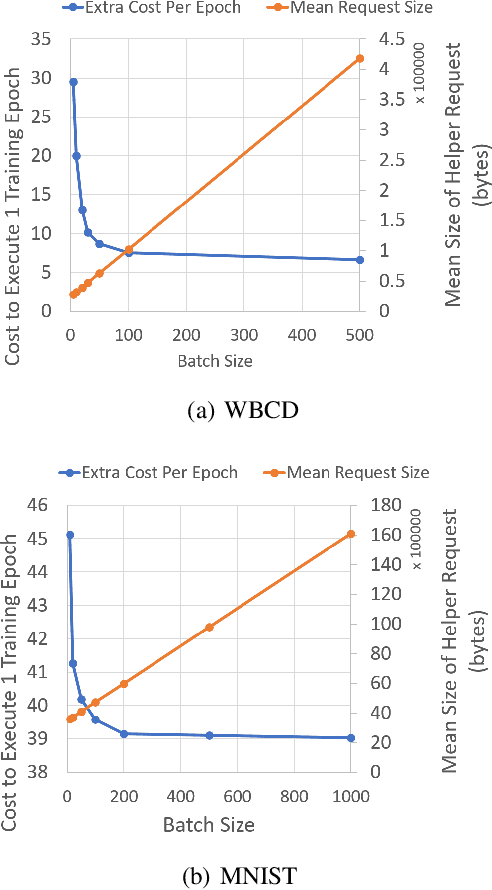
Today, many web advertising data flows involve passive cross-site tracking of users. Enabling such a mechanism through the usage of third party tracking cookies (3PC) exposes sensitive user data to a large number of parties, with little oversight on how that data can be used. Thus, most browsers are moving towards removal of 3PC in subsequent browser iterations. In order to substantially improve end-user privacy while allowing sites to continue to sustain their business through ad funding, new privacy-preserving primitives need to be introduced. In this paper, we discuss a new proposal, called Masked LARk, for aggregation of user engagement measurement and model training that prevents cross-site tracking, while remaining (a) flexible, for engineering development and maintenance, (b) secure, in the sense that cross-site tracking and tracing are blocked and (c) open for continued model development and training, allowing advertisers to serve relevant ads to interested users. We introduce a secure multi-party compute (MPC) protocol that utilizes "helper" parties to train models, so that once data leaves the browser, no downstream system can individually construct a complete picture of the user activity. For training, our key innovation is through the usage of masking, or the obfuscation of the true labels, while still allowing a gradient to be accurately computed in aggregate over a batch of data. Our protocol only utilizes light cryptography, at such a level that an interested yet inexperienced reader can understand the core algorithm. We develop helper endpoints that implement this system, and give example usage of training in PyTorch.
Data-driven Cloud Clustering via a Rotationally Invariant Autoencoder
Mar 08, 2021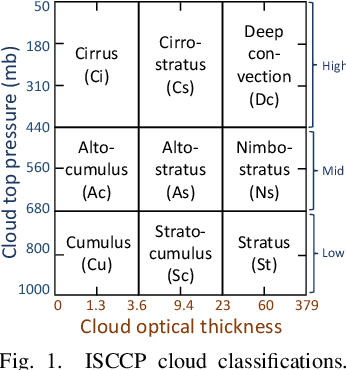


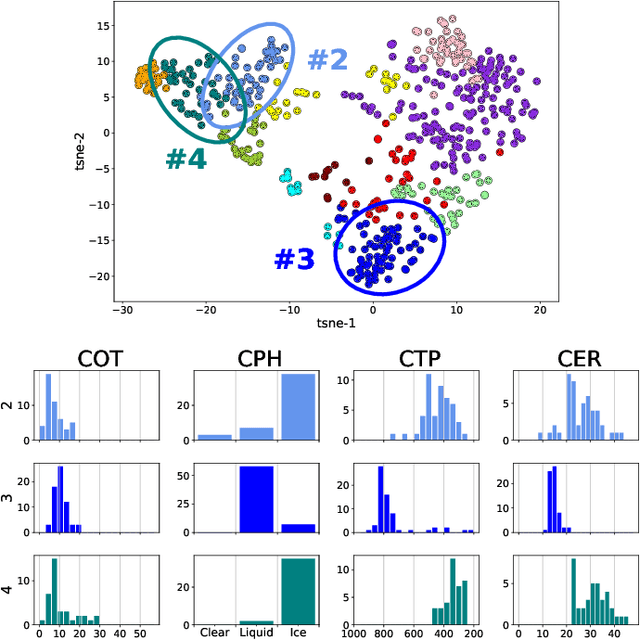
Advanced satellite-born remote sensing instruments produce high-resolution multi-spectral data for much of the globe at a daily cadence. These datasets open up the possibility of improved understanding of cloud dynamics and feedback, which remain the biggest source of uncertainty in global climate model projections. As a step towards answering these questions, we describe an automated rotation-invariant cloud clustering (RICC) method that leverages deep learning autoencoder technology to organize cloud imagery within large datasets in an unsupervised fashion, free from assumptions about predefined classes. We describe both the design and implementation of this method and its evaluation, which uses a sequence of testing protocols to determine whether the resulting clusters: (1) are physically reasonable, (i.e., embody scientifically relevant distinctions); (2) capture information on spatial distributions, such as textures; (3) are cohesive and separable in latent space; and (4) are rotationally invariant, (i.e., insensitive to the orientation of an image). Results obtained when these evaluation protocols are applied to RICC outputs suggest that the resultant novel cloud clusters capture meaningful aspects of cloud physics, are appropriately spatially coherent, and are invariant to orientations of input images. Our results support the possibility of using an unsupervised data-driven approach for automated clustering and pattern discovery in cloud imagery.
Deep Equilibrium Architectures for Inverse Problems in Imaging
Feb 16, 2021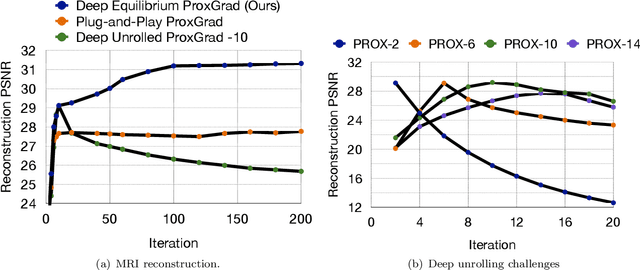
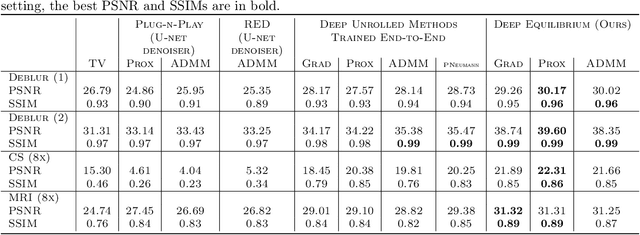
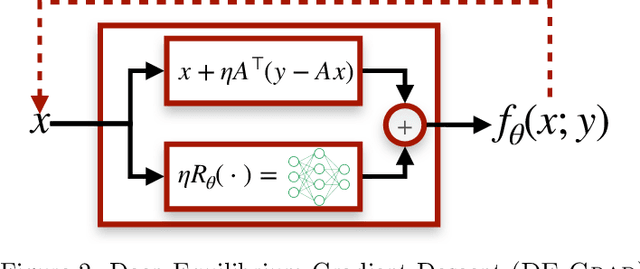
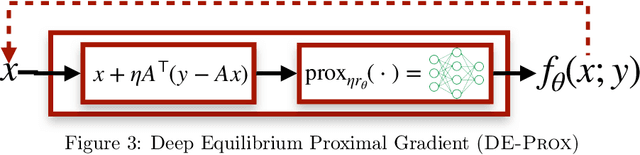
Recent efforts on solving inverse problems in imaging via deep neural networks use architectures inspired by a fixed number of iterations of an optimization method. The number of iterations is typically quite small due to difficulties in training networks corresponding to more iterations; the resulting solvers cannot be run for more iterations at test time without incurring significant errors. This paper describes an alternative approach corresponding to an {\em infinite} number of iterations, yielding up to a 4dB PSNR improvement in reconstruction accuracy above state-of-the-art alternatives and where the computational budget can be selected at test time to optimize context-dependent trade-offs between accuracy and computation. The proposed approach leverages ideas from Deep Equilibrium Models, where the fixed-point iteration is constructed to incorporate a known forward model and insights from classical optimization-based reconstruction methods.
Model Adaptation for Inverse Problems in Imaging
Nov 30, 2020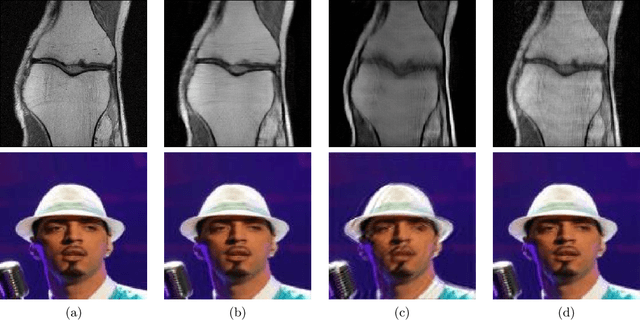

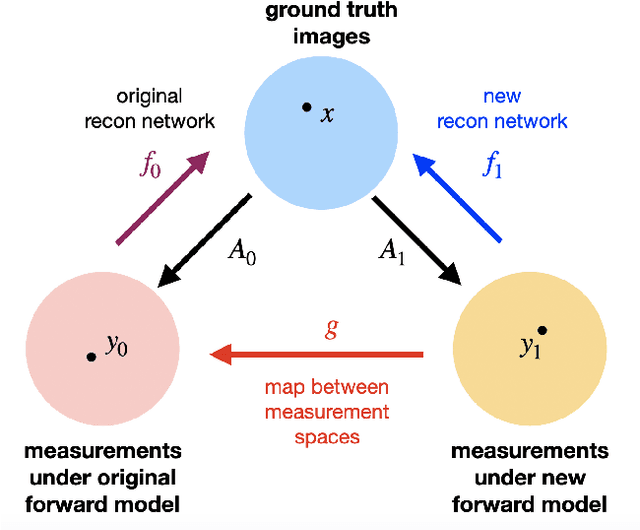

Deep neural networks have been applied successfully to a wide variety of inverse problems arising in computational imaging. These networks are typically trained using a forward model that describes the measurement process to be inverted, which is often incorporated directly into the network itself. However, these approaches lack robustness to drift of the forward model: if at test time the forward model varies (even slightly) from the one the network was trained for, the reconstruction performance can degrade substantially. Given a network trained to solve an initial inverse problem with a known forward model, we propose two novel procedures that adapt the network to a perturbed forward model, even without full knowledge of the perturbation. Our approaches do not require access to more labeled data (i.e., ground truth images), but only a small set of calibration measurements. We show these simple model adaptation procedures empirically achieve robustness to changes in the forward model in a variety of settings, including deblurring, super-resolution, and undersampled image reconstruction in magnetic resonance imaging.
Detection and Description of Change in Visual Streams
Apr 09, 2020
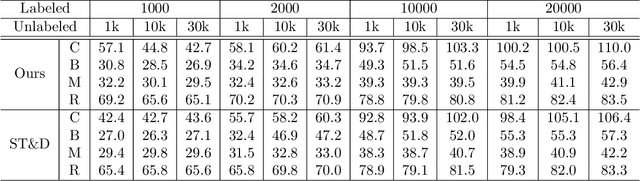

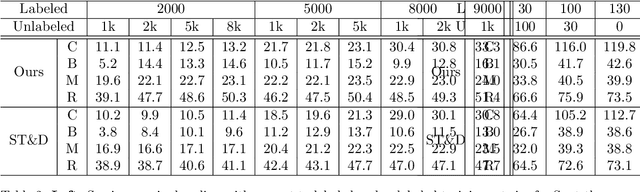
This paper presents a framework for the analysis of changes in visual streams: ordered sequences of images, possibly separated by significant time gaps. We propose a new approach to incorporating unlabeled data into training to generate natural language descriptions of change. We also develop a framework for estimating the time of change in visual stream. We use learned representations for change evidence and consistency of perceived change, and combine these in a regularized graph cut based change detector. Experimental evaluation on visual stream datasets, which we release as part of our contribution, shows that representation learning driven by natural language descriptions significantly improves change detection accuracy, compared to methods that do not rely on language.
Neumann Networks for Inverse Problems in Imaging
Jan 13, 2019
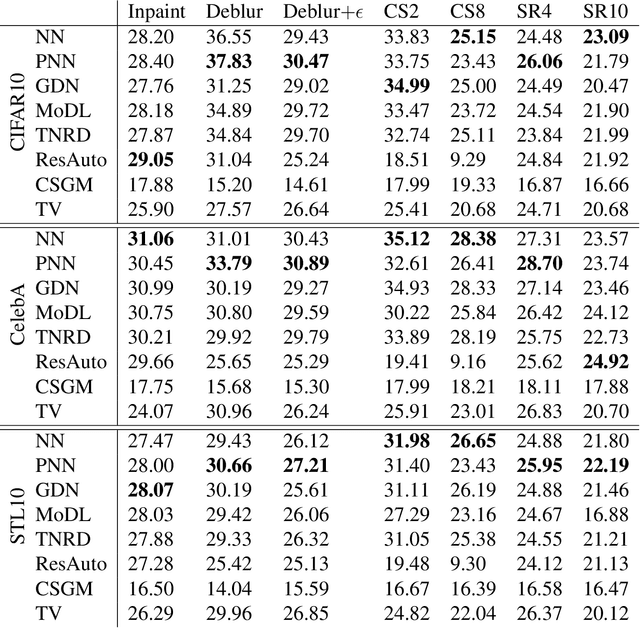
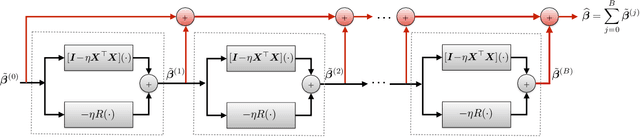

Many challenging image processing tasks can be described by an ill-posed linear inverse problem: deblurring, deconvolution, inpainting, compressed sensing, and superresolution all lie in this framework. Traditional inverse problem solvers minimize a cost function consisting of a data-fit term, which measures how well an image matches the observations, and a regularizer, which reflects prior knowledge and promotes images with desirable properties like smoothness. Recent advances in machine learning and image processing have illustrated that it is often possible to learn a regularizer from training data that can outperform more traditional regularizers. We present an end-to-end, data-driven method of solving inverse problems inspired by the Neumann series, which we call a Neumann network. Rather than unroll an iterative optimization algorithm, we truncate a Neumann series which directly solves the linear inverse problem with a data-driven nonlinear regularizer. The Neumann network architecture outperforms traditional inverse problem solution methods, model-free deep learning approaches, and state-of-the-art unrolled iterative methods on standard datasets. Finally, when the images belong to a union of subspaces and under appropriate assumptions on the forward model, we prove there exists a Neumann network configuration that well-approximates the optimal oracle estimator for the inverse problem and demonstrate empirically that the trained Neumann network has the form predicted by theory.