 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSampling Theory for Super-Resolution with Implicit Neural Representations
Jun 11, 2025Implicit neural representations (INRs) have emerged as a powerful tool for solving inverse problems in computer vision and computational imaging. INRs represent images as continuous domain functions realized by a neural network taking spatial coordinates as inputs. However, unlike traditional pixel representations, little is known about the sample complexity of estimating images using INRs in the context of linear inverse problems. Towards this end, we study the sampling requirements for recovery of a continuous domain image from its low-pass Fourier samples by fitting a single hidden-layer INR with ReLU activation and a Fourier features layer using a generalized form of weight decay regularization. Our key insight is to relate minimizers of this non-convex parameter space optimization problem to minimizers of a convex penalty defined over an infinite-dimensional space of measures. We identify a sufficient number of Fourier samples for which an image realized by an INR is exactly recoverable by solving the INR training problem. To validate our theory, we empirically assess the probability of achieving exact recovery of images realized by low-width single hidden-layer INRs, and illustrate the performance of INRs on super-resolution recovery of continuous domain phantom images.
Accelerated Optimization of Implicit Neural Representations for CT Reconstruction
Apr 18, 2025Inspired by their success in solving challenging inverse problems in computer vision, implicit neural representations (INRs) have been recently proposed for reconstruction in low-dose/sparse-view X-ray computed tomography (CT). An INR represents a CT image as a small-scale neural network that takes spatial coordinates as inputs and outputs attenuation values. Fitting an INR to sinogram data is similar to classical model-based iterative reconstruction methods. However, training INRs with losses and gradient-based algorithms can be prohibitively slow, taking many thousands of iterations to converge. This paper investigates strategies to accelerate the optimization of INRs for CT reconstruction. In particular, we propose two approaches: (1) using a modified loss function with improved conditioning, and (2) an algorithm based on the alternating direction method of multipliers. We illustrate that both of these approaches significantly accelerate INR-based reconstruction of a synthetic breast CT phantom in a sparse-view setting.
Towards a Sampling Theory for Implicit Neural Representations
May 28, 2024Implicit neural representations (INRs) have emerged as a powerful tool for solving inverse problems in computer vision and computational imaging. INRs represent images as continuous domain functions realized by a neural network taking spatial coordinates as inputs. However, unlike traditional pixel representations, little is known about the sample complexity of estimating images using INRs in the context of linear inverse problems. Towards this end, we study the sampling requirements for recovery of a continuous domain image from its low-pass Fourier coefficients by fitting a single hidden-layer INR with ReLU activation and a Fourier features layer using a generalized form of weight decay regularization. Our key insight is to relate minimizers of this non-convex parameter space optimization problem to minimizers of a convex penalty defined over an infinite-dimensional space of measures. We identify a sufficient number of samples for which an image realized by a width-1 INR is exactly recoverable by solving the INR training problem, and give a conjecture for the general width-$W$ case. To validate our theory, we empirically assess the probability of achieving exact recovery of images realized by low-width single hidden-layer INRs, and illustrate the performance of INR on super-resolution recovery of more realistic continuous domain phantom images.
Enhancing signal detectability in learning-based CT reconstruction with a model observer inspired loss function
Feb 15, 2024Deep neural networks used for reconstructing sparse-view CT data are typically trained by minimizing a pixel-wise mean-squared error or similar loss function over a set of training images. However, networks trained with such pixel-wise losses are prone to wipe out small, low-contrast features that are critical for screening and diagnosis. To remedy this issue, we introduce a novel training loss inspired by the model observer framework to enhance the detectability of weak signals in the reconstructions. We evaluate our approach on the reconstruction of synthetic sparse-view breast CT data, and demonstrate an improvement in signal detectability with the proposed loss.
Deep Equilibrium Architectures for Inverse Problems in Imaging
Feb 16, 2021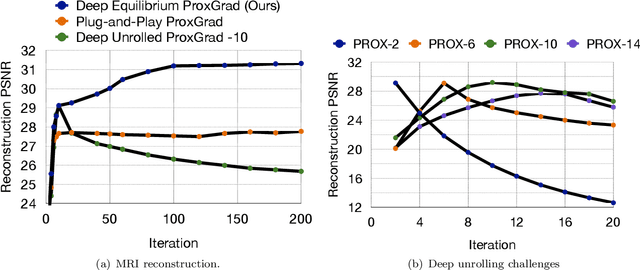
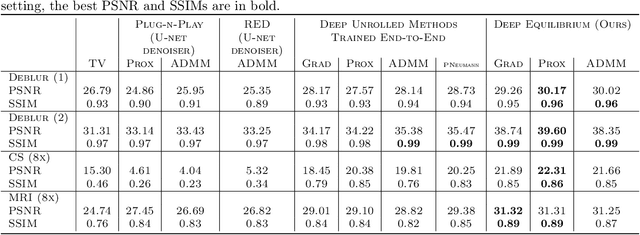
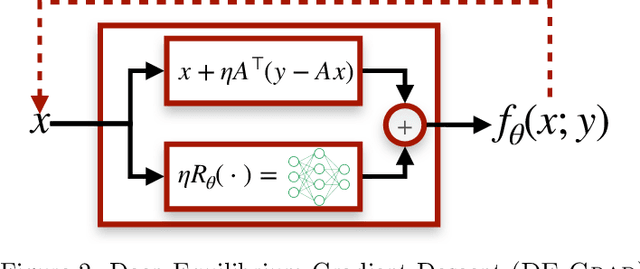
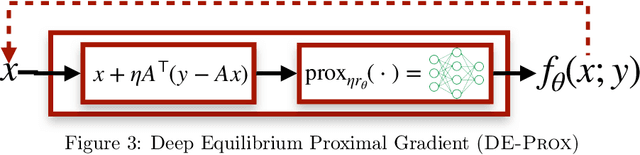
Recent efforts on solving inverse problems in imaging via deep neural networks use architectures inspired by a fixed number of iterations of an optimization method. The number of iterations is typically quite small due to difficulties in training networks corresponding to more iterations; the resulting solvers cannot be run for more iterations at test time without incurring significant errors. This paper describes an alternative approach corresponding to an {\em infinite} number of iterations, yielding up to a 4dB PSNR improvement in reconstruction accuracy above state-of-the-art alternatives and where the computational budget can be selected at test time to optimize context-dependent trade-offs between accuracy and computation. The proposed approach leverages ideas from Deep Equilibrium Models, where the fixed-point iteration is constructed to incorporate a known forward model and insights from classical optimization-based reconstruction methods.
Model Adaptation for Inverse Problems in Imaging
Nov 30, 2020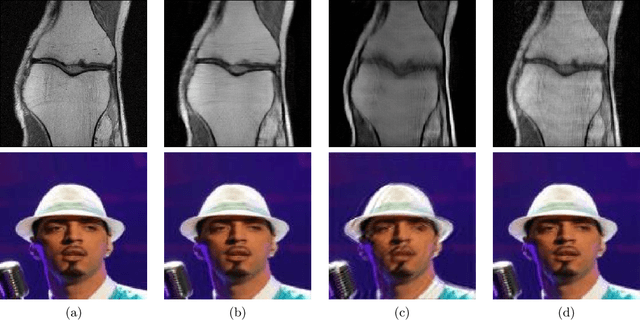

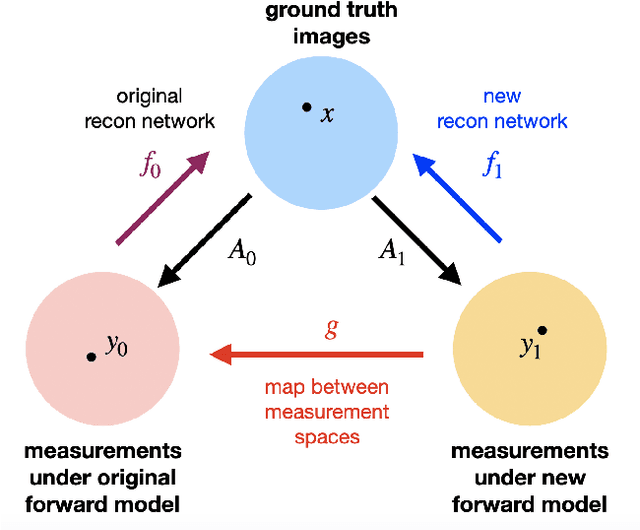

Deep neural networks have been applied successfully to a wide variety of inverse problems arising in computational imaging. These networks are typically trained using a forward model that describes the measurement process to be inverted, which is often incorporated directly into the network itself. However, these approaches lack robustness to drift of the forward model: if at test time the forward model varies (even slightly) from the one the network was trained for, the reconstruction performance can degrade substantially. Given a network trained to solve an initial inverse problem with a known forward model, we propose two novel procedures that adapt the network to a perturbed forward model, even without full knowledge of the perturbation. Our approaches do not require access to more labeled data (i.e., ground truth images), but only a small set of calibration measurements. We show these simple model adaptation procedures empirically achieve robustness to changes in the forward model in a variety of settings, including deblurring, super-resolution, and undersampled image reconstruction in magnetic resonance imaging.
Deep Learning Techniques for Inverse Problems in Imaging
May 12, 2020


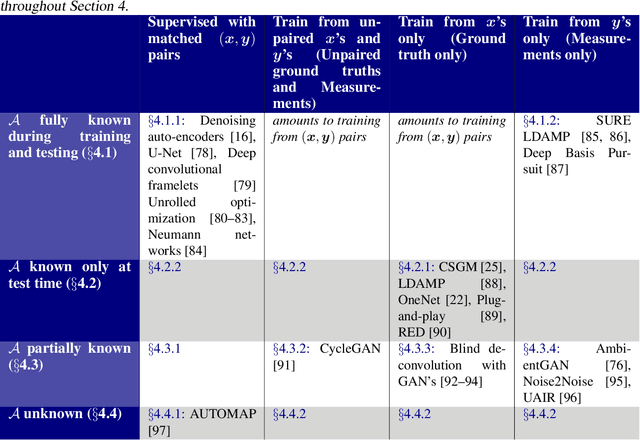
Recent work in machine learning shows that deep neural networks can be used to solve a wide variety of inverse problems arising in computational imaging. We explore the central prevailing themes of this emerging area and present a taxonomy that can be used to categorize different problems and reconstruction methods. Our taxonomy is organized along two central axes: (1) whether or not a forward model is known and to what extent it is used in training and testing, and (2) whether or not the learning is supervised or unsupervised, i.e., whether or not the training relies on access to matched ground truth image and measurement pairs. We also discuss the trade-offs associated with these different reconstruction approaches, caveats and common failure modes, plus open problems and avenues for future work.