 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoke: Evoking Critical Thinking Abilities in LLMs via Reviewer-Author Prompt Editing
Oct 20, 2023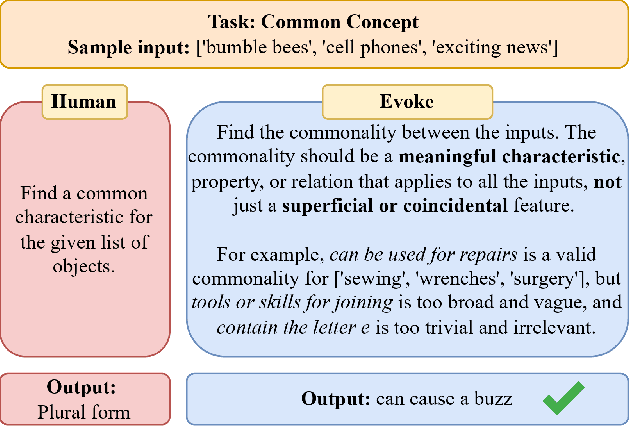
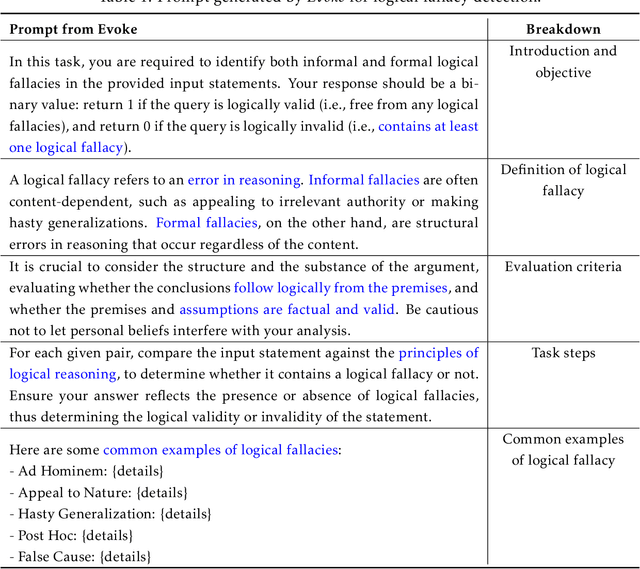
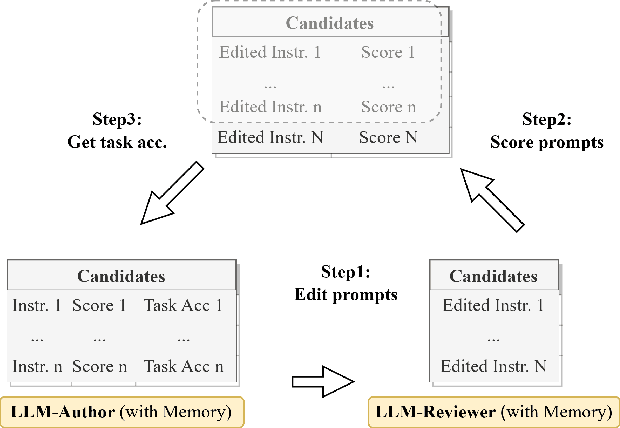
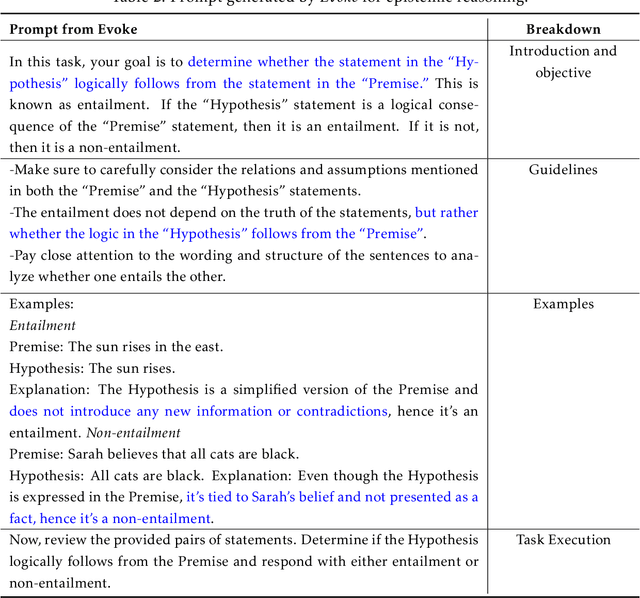
Large language models (LLMs) have made impressive progress in natural language processing. These models rely on proper human instructions (or prompts) to generate suitable responses. However, the potential of LLMs are not fully harnessed by commonly-used prompting methods: many human-in-the-loop algorithms employ ad-hoc procedures for prompt selection; while auto prompt generation approaches are essentially searching all possible prompts randomly and inefficiently. We propose Evoke, an automatic prompt refinement framework. In Evoke, there are two instances of a same LLM: one as a reviewer (LLM-Reviewer), it scores the current prompt; the other as an author (LLM-Author), it edits the prompt by considering the edit history and the reviewer's feedback. Such an author-reviewer feedback loop ensures that the prompt is refined in each iteration. We further aggregate a data selection approach to Evoke, where only the hard samples are exposed to the LLM. The hard samples are more important because the LLM can develop deeper understanding of the tasks out of them, while the model may already know how to solve the easier cases. Experimental results show that Evoke significantly outperforms existing methods. For instance, in the challenging task of logical fallacy detection, Evoke scores above 80, while all other baseline methods struggle to reach 20.
AutoHint: Automatic Prompt Optimization with Hint Generation
Jul 13, 2023
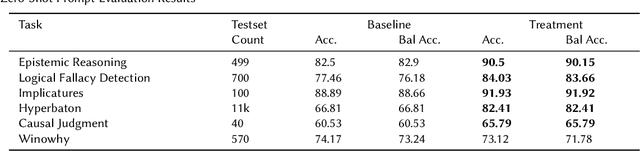
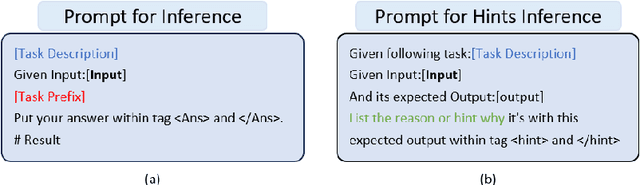
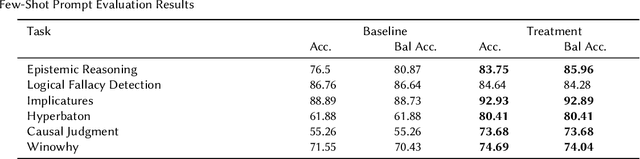
This paper presents AutoHint, a novel framework for automatic prompt engineering and optimization for Large Language Models (LLM). While LLMs have demonstrated remarkable ability in achieving high-quality annotation in various tasks, the key to applying this ability to specific tasks lies in developing high-quality prompts. Thus we propose a framework to inherit the merits of both in-context learning and zero-shot learning by incorporating enriched instructions derived from input-output demonstrations to optimize original prompt. We refer to the enrichment as the hint and propose a framework to automatically generate the hint from labeled data. More concretely, starting from an initial prompt, our method first instructs a LLM to deduce new hints for selected samples from incorrect predictions, and then summarizes from per-sample hints and adds the results back to the initial prompt to form a new, enriched instruction. The proposed method is evaluated on the BIG-Bench Instruction Induction dataset for both zero-shot and few-short prompts, where experiments demonstrate our method is able to significantly boost accuracy for multiple tasks.
DeepTagger: Knowledge Enhanced Named Entity Recognition for Web-Based Ads Queries
Jun 30, 2023

Named entity recognition (NER) is a crucial task for online advertisement. State-of-the-art solutions leverage pre-trained language models for this task. However, three major challenges remain unresolved: web queries differ from natural language, on which pre-trained models are trained; web queries are short and lack contextual information; and labeled data for NER is scarce. We propose DeepTagger, a knowledge-enhanced NER model for web-based ads queries. The proposed knowledge enhancement framework leverages both model-free and model-based approaches. For model-free enhancement, we collect unlabeled web queries to augment domain knowledge; and we collect web search results to enrich the information of ads queries. We further leverage effective prompting methods to automatically generate labels using large language models such as ChatGPT. Additionally, we adopt a model-based knowledge enhancement method based on adversarial data augmentation. We employ a three-stage training framework to train DeepTagger models. Empirical results in various NER tasks demonstrate the effectiveness of the proposed framework.
Efficient Long Sequence Modeling via State Space Augmented Transformer
Dec 15, 2022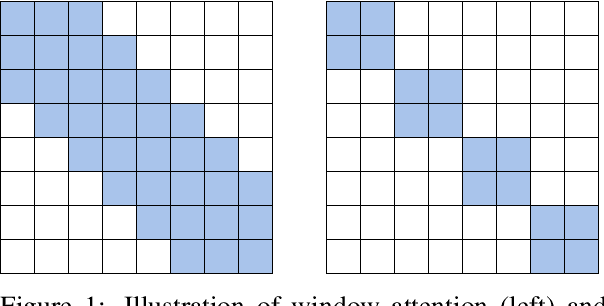
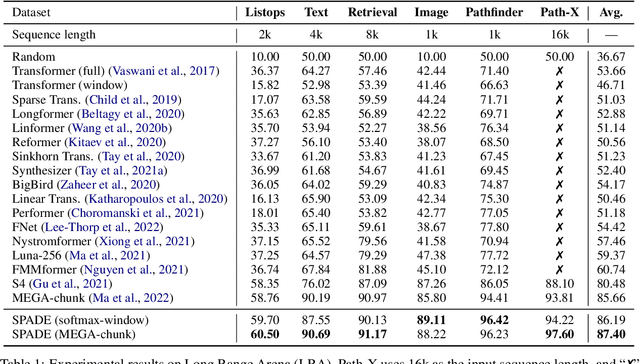
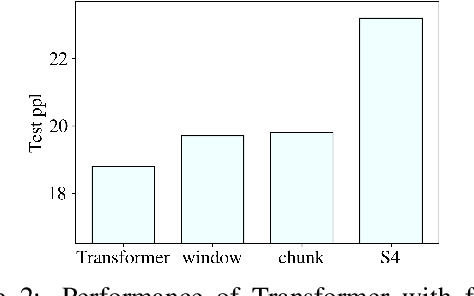
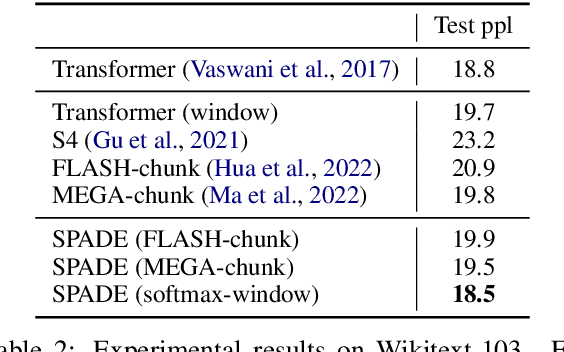
Transformer models have achieved superior performance in various natural language processing tasks. However, the quadratic computational cost of the attention mechanism limits its practicality for long sequences. There are existing attention variants that improve the computational efficiency, but they have limited ability to effectively compute global information. In parallel to Transformer models, state space models (SSMs) are tailored for long sequences, but they are not flexible enough to capture complicated local information. We propose SPADE, short for $\underline{\textbf{S}}$tate s$\underline{\textbf{P}}$ace $\underline{\textbf{A}}$ugmente$\underline{\textbf{D}}$ Transform$\underline{\textbf{E}}$r. Specifically, we augment a SSM into the bottom layer of SPADE, and we employ efficient local attention methods for the other layers. The SSM augments global information, which complements the lack of long-range dependency issue in local attention methods. Experimental results on the Long Range Arena benchmark and language modeling tasks demonstrate the effectiveness of the proposed method. To further demonstrate the scalability of SPADE, we pre-train large encoder-decoder models and present fine-tuning results on natural language understanding and natural language generation tasks.
TEDL: A Two-stage Evidential Deep Learning Method for Classification Uncertainty Quantification
Sep 12, 2022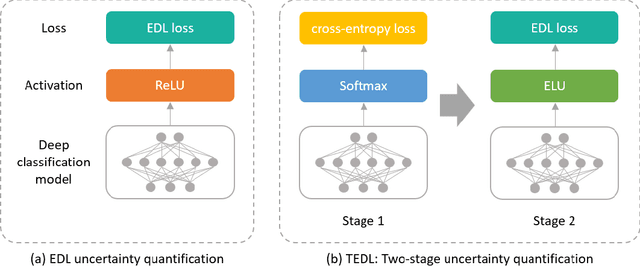
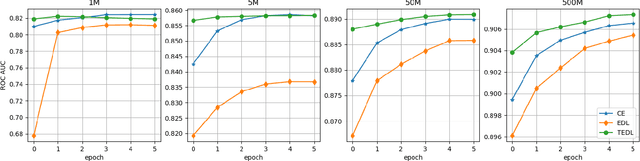
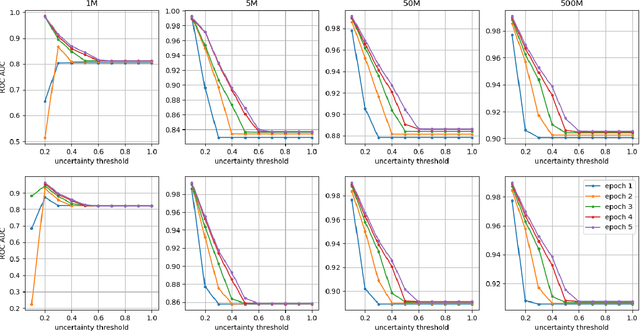
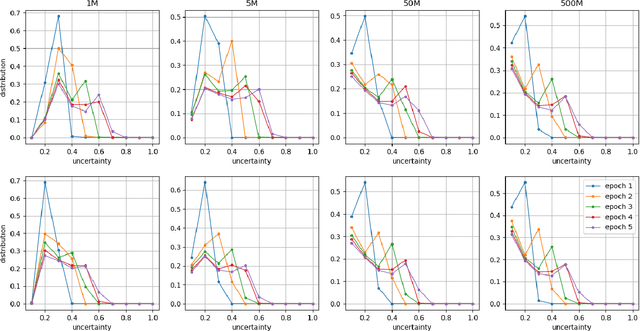
In this paper, we propose TEDL, a two-stage learning approach to quantify uncertainty for deep learning models in classification tasks, inspired by our findings in experimenting with Evidential Deep Learning (EDL) method, a recently proposed uncertainty quantification approach based on the Dempster-Shafer theory. More specifically, we observe that EDL tends to yield inferior AUC compared with models learnt by cross-entropy loss and is highly sensitive in training. Such sensitivity is likely to cause unreliable uncertainty estimation, making it risky for practical applications. To mitigate both limitations, we propose a simple yet effective two-stage learning approach based on our analysis on the likely reasons causing such sensitivity, with the first stage learning from cross-entropy loss, followed by a second stage learning from EDL loss. We also re-formulate the EDL loss by replacing ReLU with ELU to avoid the Dying ReLU issue. Extensive experiments are carried out on varied sized training corpus collected from a large-scale commercial search engine, demonstrating that the proposed two-stage learning framework can increase AUC significantly and greatly improve training robustness.
Masked LARk: Masked Learning, Aggregation and Reporting worKflow
Oct 27, 2021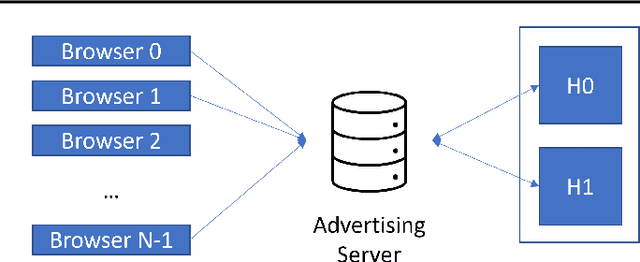
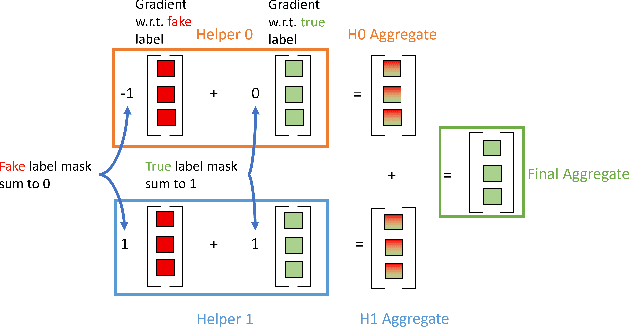
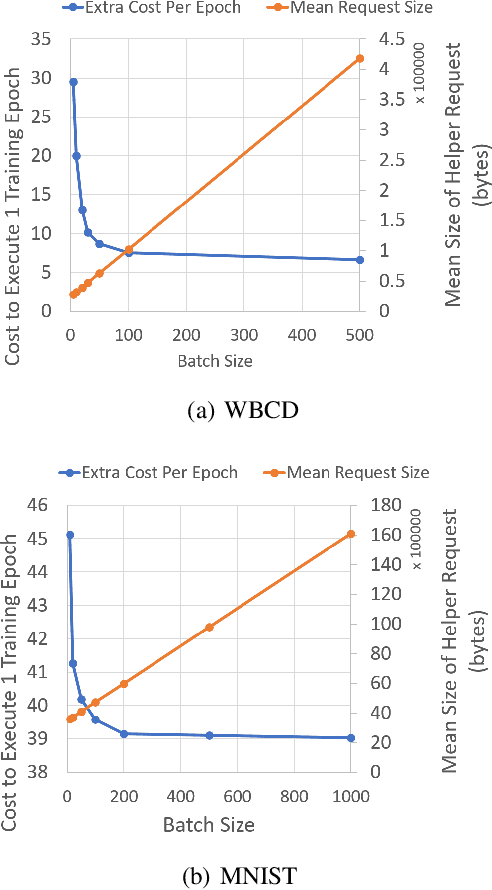
Today, many web advertising data flows involve passive cross-site tracking of users. Enabling such a mechanism through the usage of third party tracking cookies (3PC) exposes sensitive user data to a large number of parties, with little oversight on how that data can be used. Thus, most browsers are moving towards removal of 3PC in subsequent browser iterations. In order to substantially improve end-user privacy while allowing sites to continue to sustain their business through ad funding, new privacy-preserving primitives need to be introduced. In this paper, we discuss a new proposal, called Masked LARk, for aggregation of user engagement measurement and model training that prevents cross-site tracking, while remaining (a) flexible, for engineering development and maintenance, (b) secure, in the sense that cross-site tracking and tracing are blocked and (c) open for continued model development and training, allowing advertisers to serve relevant ads to interested users. We introduce a secure multi-party compute (MPC) protocol that utilizes "helper" parties to train models, so that once data leaves the browser, no downstream system can individually construct a complete picture of the user activity. For training, our key innovation is through the usage of masking, or the obfuscation of the true labels, while still allowing a gradient to be accurately computed in aggregate over a batch of data. Our protocol only utilizes light cryptography, at such a level that an interested yet inexperienced reader can understand the core algorithm. We develop helper endpoints that implement this system, and give example usage of training in PyTorch.
Causal Transfer Random Forest: Combining Logged Data and Randomized Experiments for Robust Prediction
Oct 17, 2020
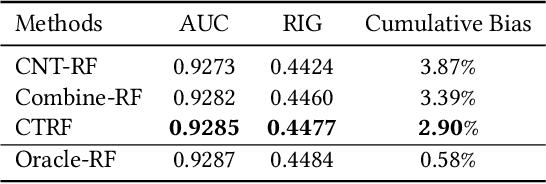
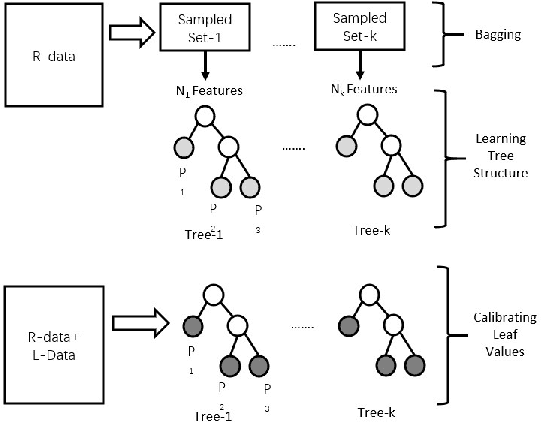
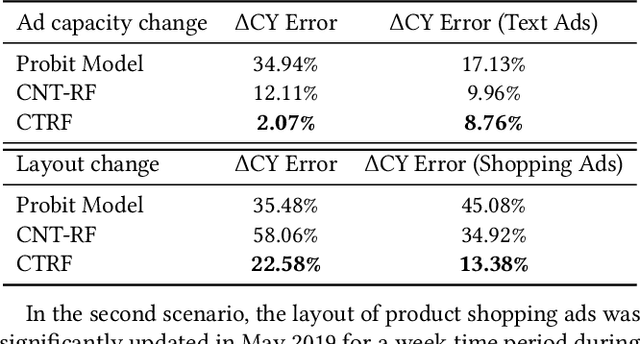
It is often critical for prediction models to be robust to distributional shifts between training and testing data. Viewed from a causal perspective, the challenge is to distinguish the stable causal relationships from the unstable spurious correlations across shifts. We describe a causal transfer random forest (CTRF) that combines existing training data with a small amount of data from a randomized experiment to train a model which is robust to the feature shifts and therefore transfers to a new targeting distribution. Theoretically, we justify the robustness of the approach against feature shifts with the knowledge from causal learning. Empirically, we evaluate the CTRF using both synthetic data experiments and real-world experiments in the Bing Ads platform, including a click prediction task and in the context of an end-to-end counterfactual optimization system. The proposed CTRF produces robust predictions and outperforms most baseline methods compared in the presence of feature shifts.
Causal Inference in the Presence of Interference in Sponsored Search Advertising
Oct 15, 2020


In classical causal inference, inferring cause-effect relations from data relies on the assumption that units are independent and identically distributed. This assumption is violated in settings where units are related through a network of dependencies. An example of such a setting is ad placement in sponsored search advertising, where the clickability of a particular ad is potentially influenced by where it is placed and where other ads are placed on the search result page. In such scenarios, confounding arises due to not only the individual ad-level covariates but also the placements and covariates of other ads in the system. In this paper, we leverage the language of causal inference in the presence of interference to model interactions among the ads. Quantification of such interactions allows us to better understand the click behavior of users, which in turn impacts the revenue of the host search engine and enhances user satisfaction. We illustrate the utility of our formalization through experiments carried out on the ad placement system of the Bing search engine.
Self-Supervised Contextual Bandits in Computer Vision
Mar 18, 2020
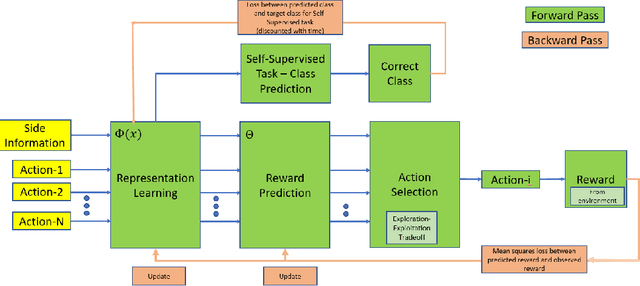
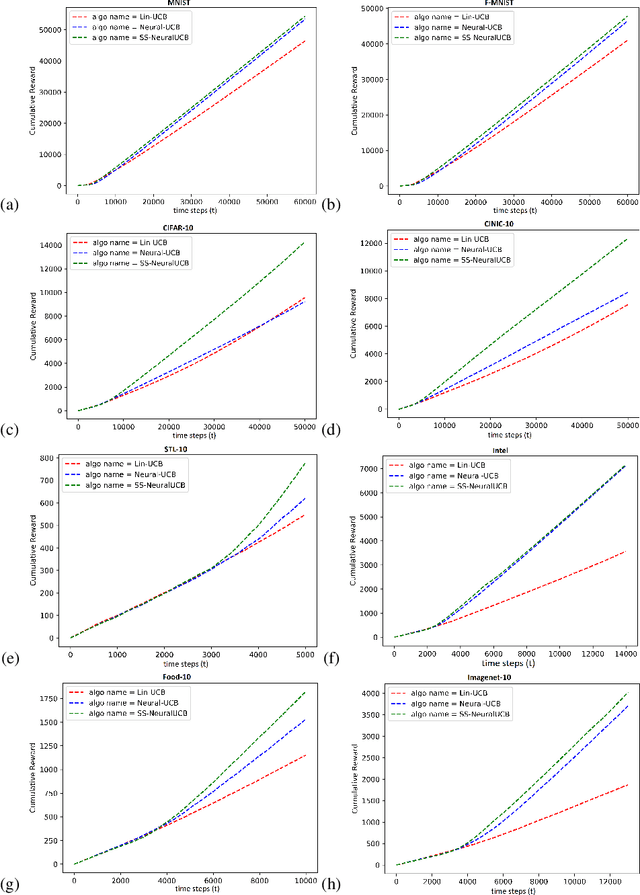
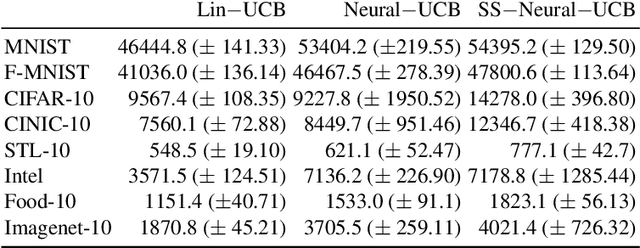
Contextual bandits are a common problem faced by machine learning practitioners in domains as diverse as hypothesis testing to product recommendations. There have been a lot of approaches in exploiting rich data representations for contextual bandit problems with varying degree of success. Self-supervised learning is a promising approach to find rich data representations without explicit labels. In a typical self-supervised learning scheme, the primary task is defined by the problem objective (e.g. clustering, classification, embedding generation etc.) and the secondary task is defined by the self-supervision objective (e.g. rotation prediction, words in neighborhood, colorization, etc.). In the usual self-supervision, we learn implicit labels from the training data for a secondary task. However, in the contextual bandit setting, we don't have the advantage of getting implicit labels due to lack of data in the initial phase of learning. We provide a novel approach to tackle this issue by combining a contextual bandit objective with a self supervision objective. By augmenting contextual bandit learning with self-supervision we get a better cumulative reward. Our results on eight popular computer vision datasets show substantial gains in cumulative reward. We provide cases where the proposed scheme doesn't perform optimally and give alternative methods for better learning in these cases.
Data Transformation Insights in Self-supervision with Clustering Tasks
Feb 18, 2020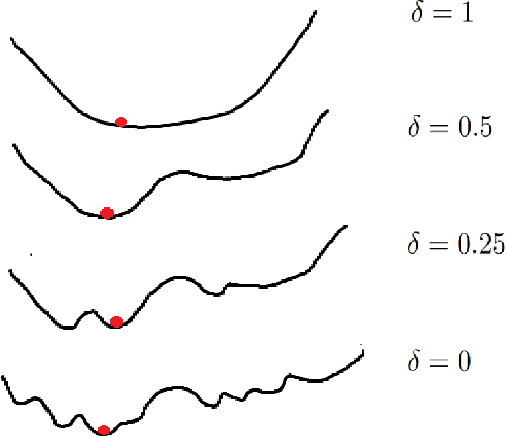

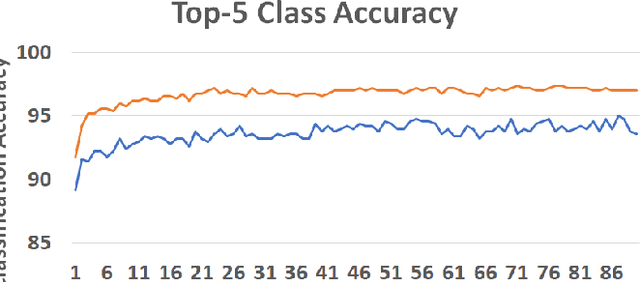
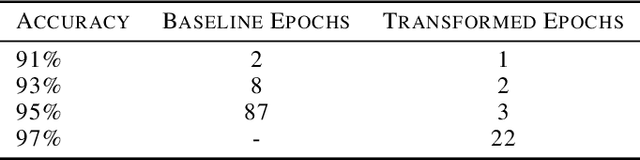
Self-supervision is key to extending use of deep learning for label scarce domains. For most of self-supervised approaches data transformations play an important role. However, up until now the impact of transformations have not been studied. Furthermore, different transformations may have different impact on the system. We provide novel insights into the use of data transformation in self-supervised tasks, specially pertaining to clustering. We show theoretically and empirically that certain set of transformations are helpful in convergence of self-supervised clustering. We also show the cases when the transformations are not helpful or in some cases even harmful. We show faster convergence rate with valid transformations for convex as well as certain family of non-convex objectives along with the proof of convergence to the original set of optima. We have synthetic as well as real world data experiments. Empirically our results conform with the theoretical insights provided.