 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline RL With Resource Constrained Online Deployment
Oct 07, 2021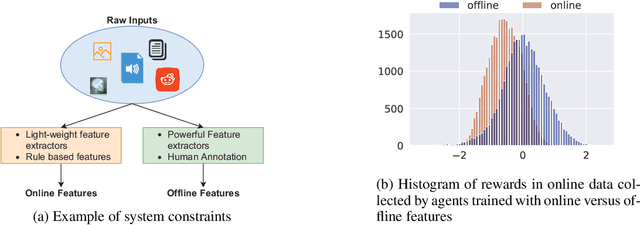


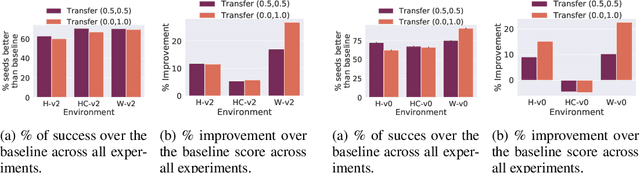
Offline reinforcement learning is used to train policies in scenarios where real-time access to the environment is expensive or impossible. As a natural consequence of these harsh conditions, an agent may lack the resources to fully observe the online environment before taking an action. We dub this situation the resource-constrained setting. This leads to situations where the offline dataset (available for training) can contain fully processed features (using powerful language models, image models, complex sensors, etc.) which are not available when actions are actually taken online. This disconnect leads to an interesting and unexplored problem in offline RL: Is it possible to use a richly processed offline dataset to train a policy which has access to fewer features in the online environment? In this work, we introduce and formalize this novel resource-constrained problem setting. We highlight the performance gap between policies trained using the full offline dataset and policies trained using limited features. We address this performance gap with a policy transfer algorithm which first trains a teacher agent using the offline dataset where features are fully available, and then transfers this knowledge to a student agent that only uses the resource-constrained features. To better capture the challenge of this setting, we propose a data collection procedure: Resource Constrained-Datasets for RL (RC-D4RL). We evaluate our transfer algorithm on RC-D4RL and the popular D4RL benchmarks and observe consistent improvement over the baseline (TD3+BC without transfer). The code for the experiments is available at https://github.com/JayanthRR/RC-OfflineRL}{github.com/RC-OfflineRL.
Representation Learning for Clustering via Building Consensus
May 04, 2021
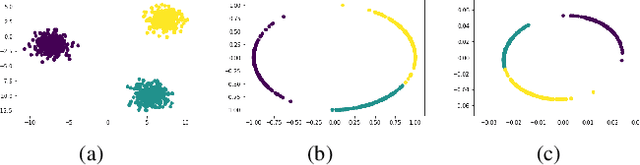
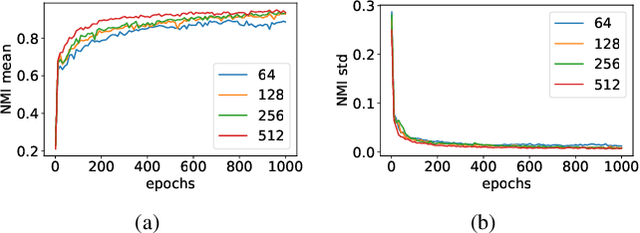

In this paper, we focus on deep clustering and unsupervised representation learning for images. Recent advances in deep clustering and unsupervised representation learning are based on the idea that different views of an input image (generated through data augmentation techniques) must be closer in the representation space (exemplar consistency), and/or similar images have a similar cluster assignment (population consistency). We define an additional notion of consistency, consensus consistency, which ensures that representations are learnt to induce similar partitions for variations in the representation space, different clustering algorithms or different initializations of a clustering algorithm. We define a clustering loss by performing variations in the representation space and seamlessly integrate all three consistencies (consensus, exemplar and population) into an end-to-end learning framework. The proposed algorithm, Consensus Clustering using Unsupervised Representation Learning (ConCURL) improves the clustering performance over state-of-the art methods on four out of five image datasets. Further, we extend the evaluation procedure for clustering to reflect the challenges in real world clustering tasks, such as clustering performance in the case of distribution shift. We also perform a detailed ablation study for a deeper understanding of the algorithm.
Consensus Clustering with Unsupervised Representation Learning
Oct 03, 2020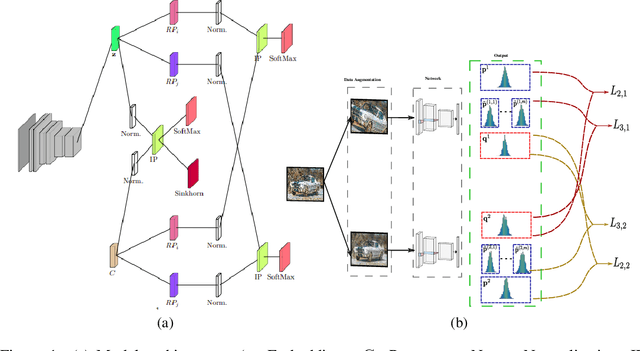


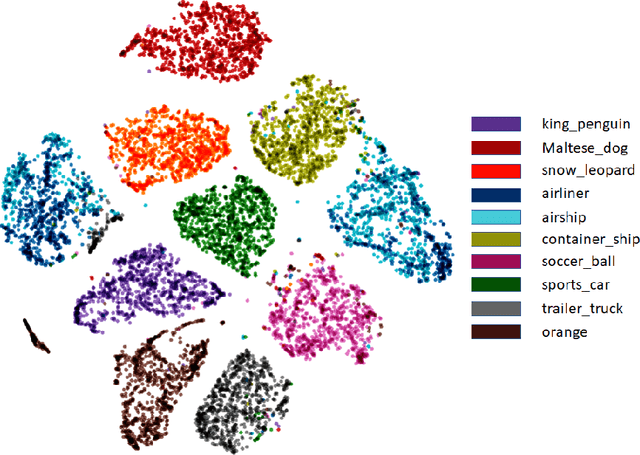
Recent advances in deep clustering and unsupervised representation learning are based on the idea that different views of an input image (generated through data augmentation techniques) must either be closer in the representation space, or have a similar cluster assignment. In this work, we leverage this idea together with ensemble learning to perform clustering and representation learning. Ensemble learning is widely used in the supervised learning setting but has not yet been practical in deep clustering. Previous works on ensemble learning for clustering neither work on the feature space nor learn features. We propose a novel ensemble learning algorithm dubbed Consensus Clustering with Unsupervised Representation Learning (ConCURL) which learns representations by creating a consensus on multiple clustering outputs. Specifically, we generate a cluster ensemble using random transformations on the embedding space, and define a consensus loss function that measures the disagreement among the constituents of the ensemble. Thus, diverse ensembles minimize this loss function in a synergistic way, which leads to better representations that work with all cluster ensemble constituents. Our proposed method ConCURL is easy to implement and integrate into any representation learning or deep clustering block. ConCURL outperforms all state of the art methods on various computer vision datasets. Specifically, we beat the closest state of the art method by 5.9 percent on the ImageNet-10 dataset, and by 18 percent on the ImageNet-Dogs dataset in terms of clustering accuracy. We further shed some light on the under-studied overfitting issue in clustering and show that our method does not overfit as much as existing methods, and thereby generalizes better for new data samples.
Zero Shot Domain Generalization
Aug 17, 2020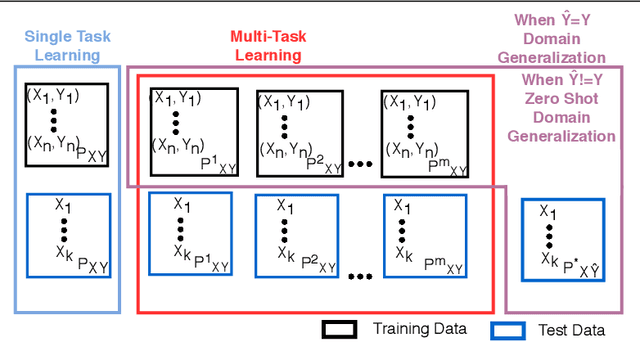
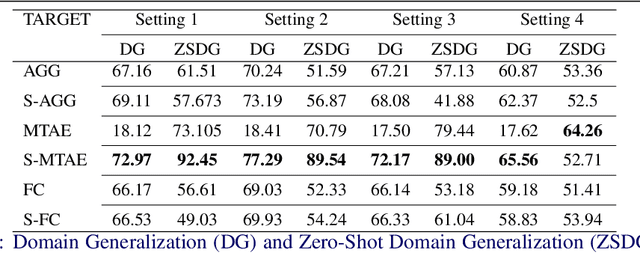
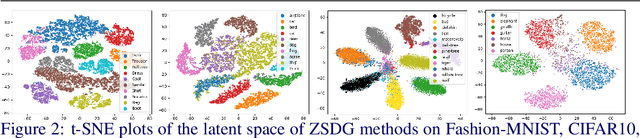
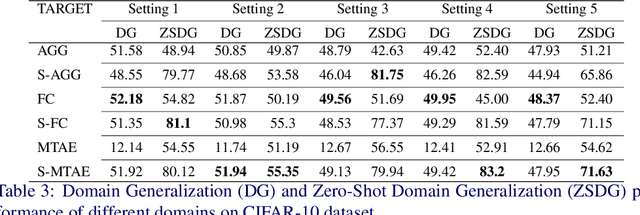
Standard supervised learning setting assumes that training data and test data come from the same distribution (domain). Domain generalization (DG) methods try to learn a model that when trained on data from multiple domains, would generalize to a new unseen domain. We extend DG to an even more challenging setting, where the label space of the unseen domain could also change. We introduce this problem as Zero-Shot Domain Generalization (to the best of our knowledge, the first such effort), where the model generalizes across new domains and also across new classes in those domains. We propose a simple strategy which effectively exploits semantic information of classes, to adapt existing DG methods to meet the demands of Zero-Shot Domain Generalization. We evaluate the proposed methods on CIFAR-10, CIFAR-100, F-MNIST and PACS datasets, establishing a strong baseline to foster interest in this new research direction.
Self-Supervised Contextual Bandits in Computer Vision
Mar 18, 2020
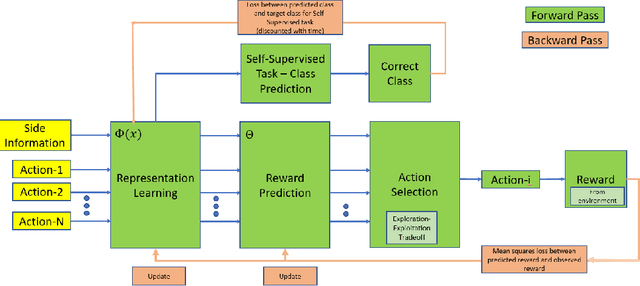
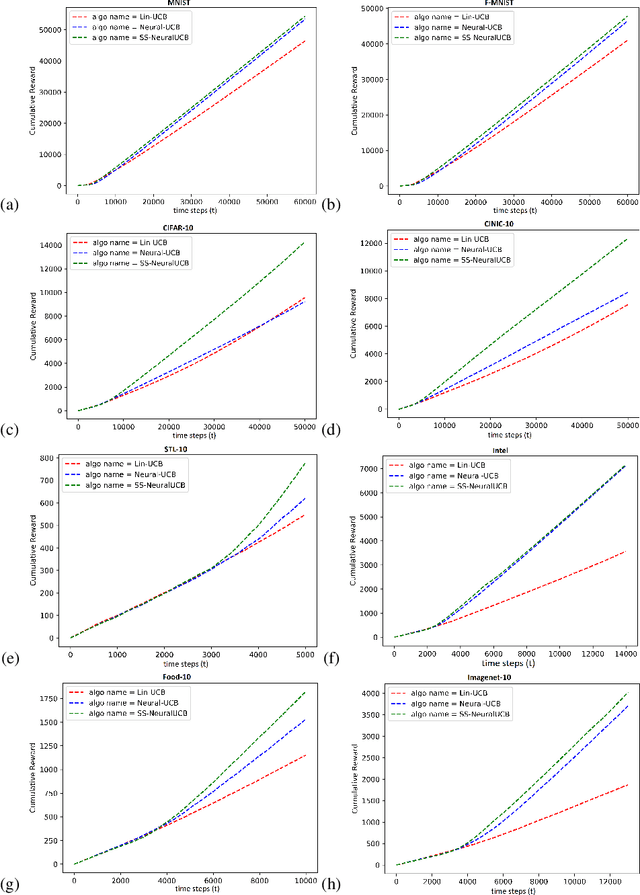
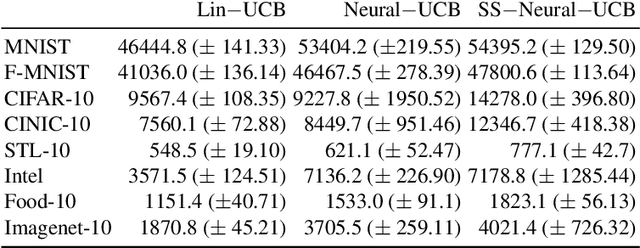
Contextual bandits are a common problem faced by machine learning practitioners in domains as diverse as hypothesis testing to product recommendations. There have been a lot of approaches in exploiting rich data representations for contextual bandit problems with varying degree of success. Self-supervised learning is a promising approach to find rich data representations without explicit labels. In a typical self-supervised learning scheme, the primary task is defined by the problem objective (e.g. clustering, classification, embedding generation etc.) and the secondary task is defined by the self-supervision objective (e.g. rotation prediction, words in neighborhood, colorization, etc.). In the usual self-supervision, we learn implicit labels from the training data for a secondary task. However, in the contextual bandit setting, we don't have the advantage of getting implicit labels due to lack of data in the initial phase of learning. We provide a novel approach to tackle this issue by combining a contextual bandit objective with a self supervision objective. By augmenting contextual bandit learning with self-supervision we get a better cumulative reward. Our results on eight popular computer vision datasets show substantial gains in cumulative reward. We provide cases where the proposed scheme doesn't perform optimally and give alternative methods for better learning in these cases.
Data Transformation Insights in Self-supervision with Clustering Tasks
Feb 18, 2020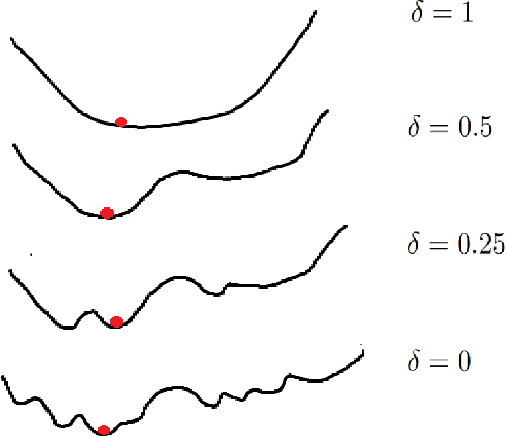

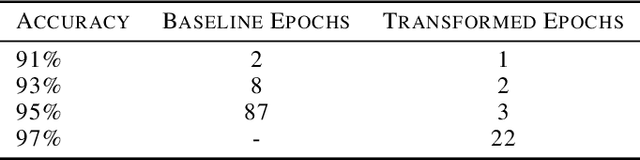
Self-supervision is key to extending use of deep learning for label scarce domains. For most of self-supervised approaches data transformations play an important role. However, up until now the impact of transformations have not been studied. Furthermore, different transformations may have different impact on the system. We provide novel insights into the use of data transformation in self-supervised tasks, specially pertaining to clustering. We show theoretically and empirically that certain set of transformations are helpful in convergence of self-supervised clustering. We also show the cases when the transformations are not helpful or in some cases even harmful. We show faster convergence rate with valid transformations for convex as well as certain family of non-convex objectives along with the proof of convergence to the original set of optima. We have synthetic as well as real world data experiments. Empirically our results conform with the theoretical insights provided.
Head and Tail Localization of C. elegans
Jan 12, 2020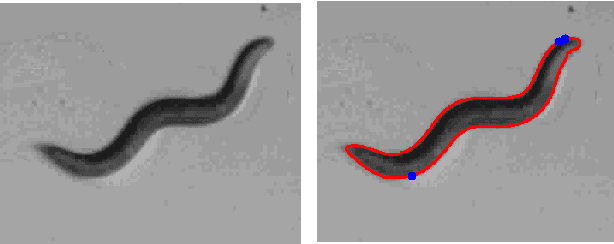
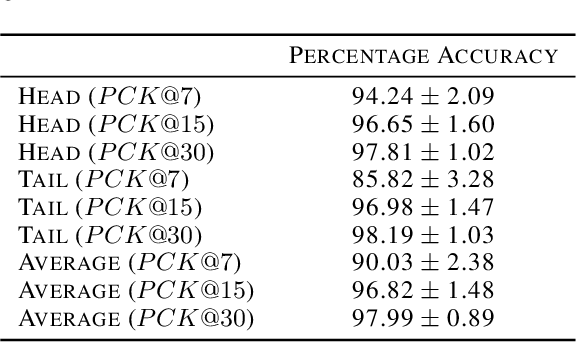

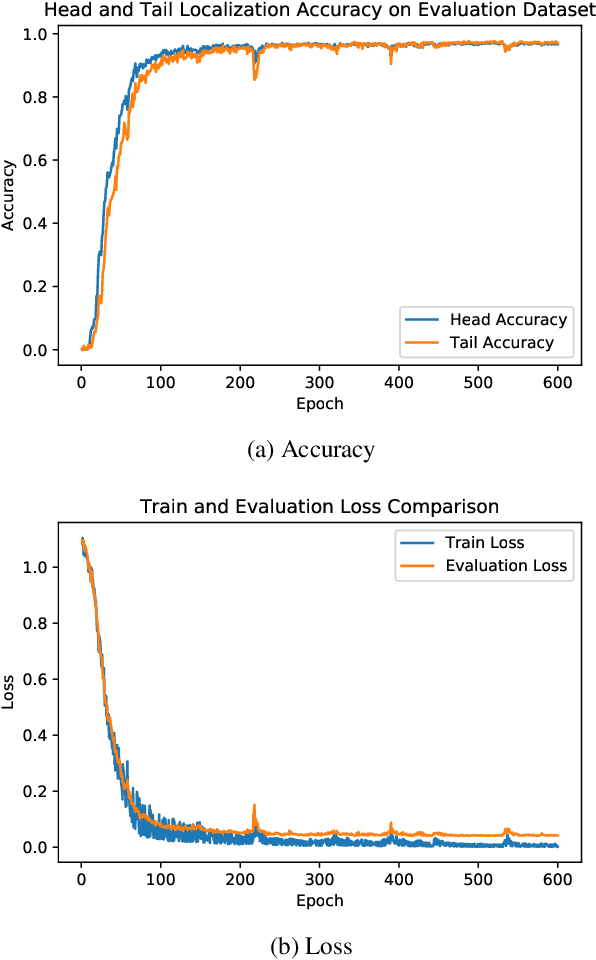
C. elegans is commonly used in neuroscience for behaviour analysis because of it's compact nervous system with well-described connectivity. Localizing the animal and distinguishing between its head and tail are important tasks to track the worm during behavioural assays and to perform quantitative analyses. We demonstrate a neural network based approach to localize both the head and the tail of the worm in an image. To make empirical results in the paper reproducible and promote open source machine learning based solutions for C. elegans behavioural analysis, we also make our code publicly available.
Label-similarity Curriculum Learning
Nov 15, 2019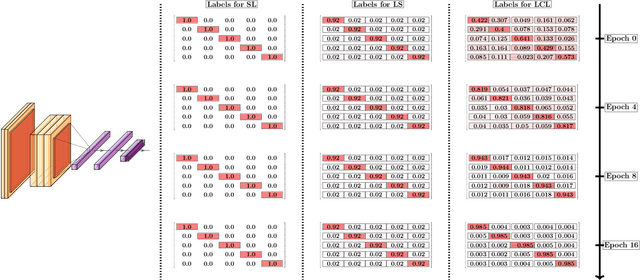

Curriculum learning can improve neural network training by guiding the optimization to desirable optima. We propose a novel curriculum learning approach for image classification that adapts the loss function by changing the label representation. The idea is to use a probability distribution over classes as target label, where the class probabilities reflect the similarity to the true class. Gradually, this label representation is shifted towards the standard one-hot-encoding. That is, in the beginning minor mistakes are corrected less than large mistakes, resembling a teaching process in which broad concepts are explained first before subtle differences are taught. The class similarity can be based on prior knowledge. For the special case of the labels being natural words, we propose a generic way to automatically compute the similarities. The natural words are embedded into Euclidean space using a standard word embedding. The probability of each class is then a function of the cosine similarity between the vector representations of the class and the true label. The proposed label-similarity curriculum learning (LCL) approach was empirically evaluated on several popular deep learning architectures for image classification task applied to three datasets, ImageNet, CIFAR100, and AWA2. In all scenarios, LCL was able to improve the classification accuracy on the test data compared to standard training.
PAC Reinforcement Learning without Real-World Feedback
Oct 25, 2019This work studies reinforcement learning in the Sim-to-Real setting, in which an agent is first trained on a number of simulators before being deployed in the real world, with the aim of decreasing the real-world sample complexity requirement. Using a dynamic model known as a rich observation Markov decision process (ROMDP), we formulate a theoretical framework for Sim-to-Real in the situation where feedback in the real world is not available. We establish real-world sample complexity guarantees that are smaller than what is currently known for directly (i.e., without access to simulators) learning a ROMDP with feedback.
A Generalization Error Bound for Multi-class Domain Generalization
May 24, 2019
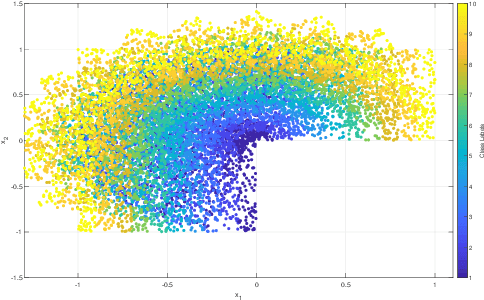
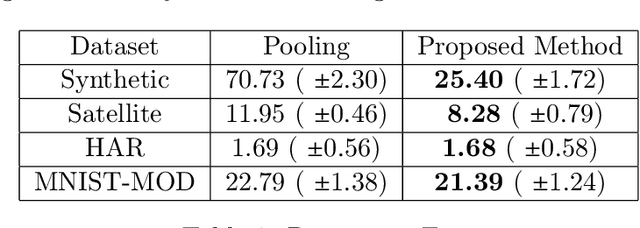

Domain generalization is the problem of assigning labels to an unlabeled data set, given several similar data sets for which labels have been provided. Despite considerable interest in this problem over the last decade, there has been no theoretical analysis in the setting of multi-class classification. In this work, we study a kernel-based learning algorithm and establish a generalization error bound that scales logarithmically in the number of classes, matching state-of-the-art bounds for multi-class classification in the conventional learning setting. We also demonstrate empirically that the proposed algorithm achieves significant performance gains compared to a pooling strategy.