 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProduct Title Generation for Conversational Systems using BERT
Jul 23, 2020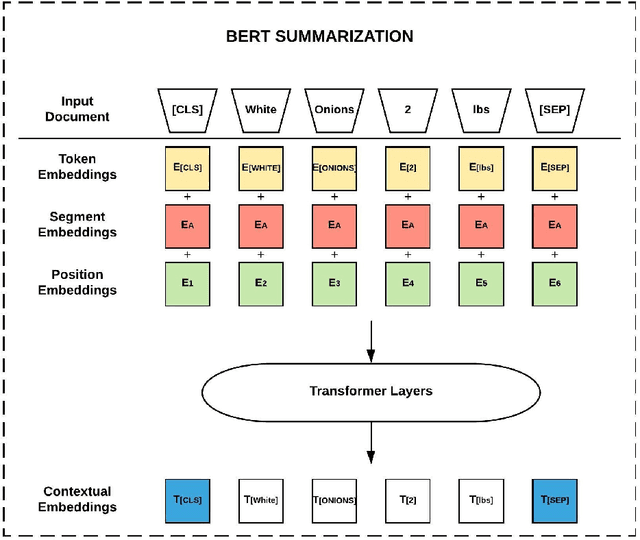



Through recent advancements in speech technology and introduction of smart devices, such as Amazon Alexa and Google Home, increasing number of users are interacting with applications through voice. E-commerce companies typically display short product titles on their webpages, either human-curated or algorithmically generated, when brevity is required, but these titles are dissimilar from natural spoken language. For example, "Lucky Charms Gluten Free Break-fast Cereal, 20.5 oz a box Lucky Charms Gluten Free" is acceptable to display on a webpage, but "a 20.5 ounce box of lucky charms gluten free cereal" is easier to comprehend over a conversational system. As compared to display devices, where images and detailed product information can be presented to users, short titles for products are necessary when interfacing with voice assistants. We propose a sequence-to-sequence approach using BERT to generate short, natural, spoken language titles from input web titles. Our extensive experiments on a real-world industry dataset and human evaluation of model outputs, demonstrate that BERT summarization outperforms comparable baseline models.
Head and Tail Localization of C. elegans
Jan 12, 2020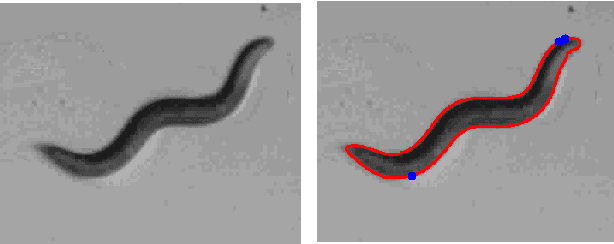
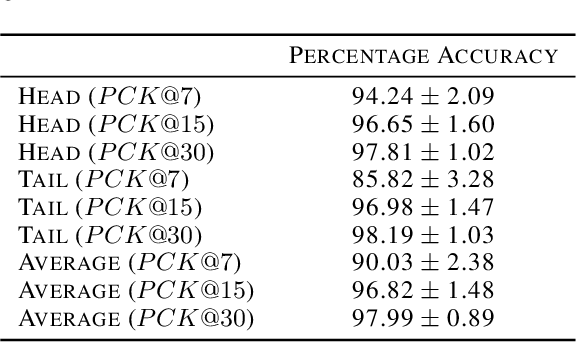

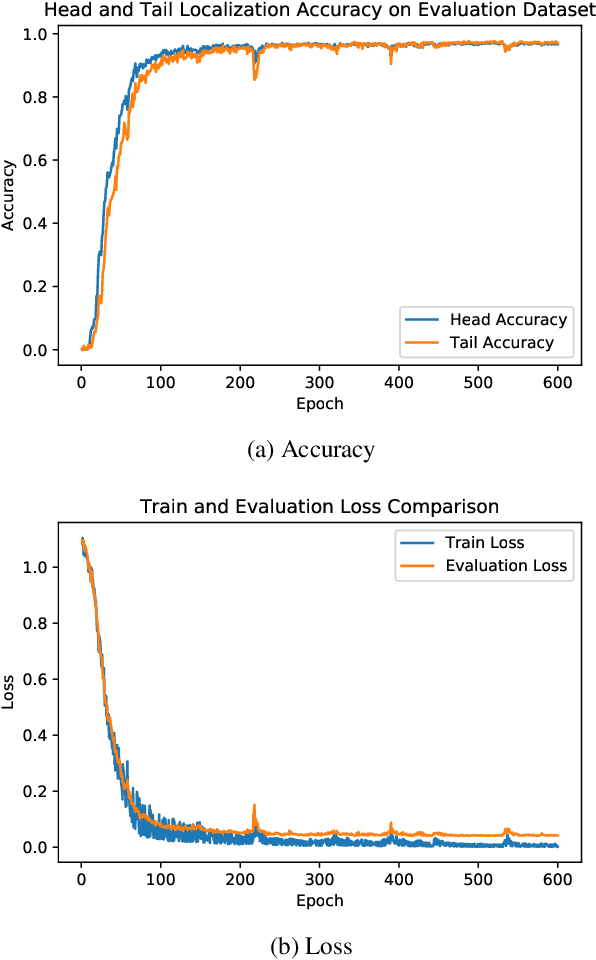
C. elegans is commonly used in neuroscience for behaviour analysis because of it's compact nervous system with well-described connectivity. Localizing the animal and distinguishing between its head and tail are important tasks to track the worm during behavioural assays and to perform quantitative analyses. We demonstrate a neural network based approach to localize both the head and the tail of the worm in an image. To make empirical results in the paper reproducible and promote open source machine learning based solutions for C. elegans behavioural analysis, we also make our code publicly available.
Complementary-Similarity Learning using Quadruplet Network
Sep 14, 2019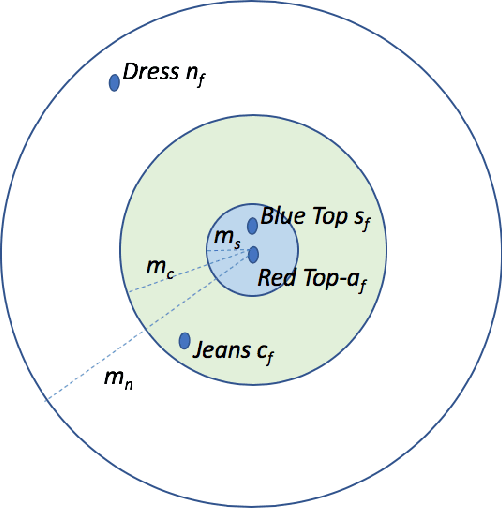


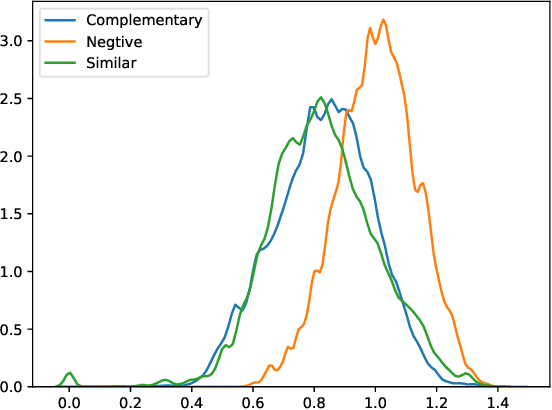
We propose a novel learning framework to answer questions such as "if a user is purchasing a shirt, what other items will (s)he need with the shirt?" Our framework learns distributed representations for items from available textual data, with the learned representations representing items in a latent space expressing functional complementarity as well similarity. In particular, our framework places functionally similar items close together in the latent space, while also placing complementary items closer than non-complementary items, but farther away than similar items. In this study, we introduce a new dataset of similar, complementary, and negative items derived from the Amazon co-purchase dataset. For evaluation purposes, we focus our approach on clothing and fashion verticals. As per our knowledge, this is the first attempt to learn similar and complementary relationships simultaneously through just textual title metadata. Our framework is applicable across a broad set of items in the product catalog and can generate quality complementary item recommendations at scale.