 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-HYPER: Generative CTR Modeling for Cold-Start Ad Personalization via LLM-Based Hypernetworks
Apr 13, 2026On online advertising platforms, newly introduced promotional ads face the cold-start problem, as they lack sufficient user feedback for model training. In this work, we propose LLM-HYPER, a novel framework that treats large language models (LLMs) as hypernetworks to directly generate the parameters of the click-through rate (CTR) estimator in a training-free manner. LLM-HYPER uses few-shot Chain-of-Thought prompting over multimodal ad content (text and images) to infer feature-wise model weights for a linear CTR predictor. By retrieving semantically similar past campaigns via CLIP embeddings and formatting them into prompt-based demonstrations, the LLM learns to reason about customer intent, feature influence, and content relevance. To ensure numerical stability and serviceability, we introduce normalization and calibration techniques that align the generated weights with production-ready CTR distributions. Extensive offline experiments show that LLM-HYPER significantly outperforms cold-start baselines in NDCG$@10$ by 55.9\%. Our real-world online A/B test on one of the top e-commerce platforms in the U.S. demonstrates the strong performance of LLM-HYPER, which drastically reduces the cold-start period and achieves competitive performance. LLM-HYPER has been successfully deployed in production.
CASE: Cadence-Aware Set Encoding for Large-Scale Next Basket Repurchase Recommendation
Apr 09, 2026Repurchase behavior is a primary signal in large-scale retail recommendation, particularly in categories with frequent replenishment: many items in a user's next basket were previously purchased and their timing follows stable, item-specific cadences. Yet most next basket repurchase recommendation models represent history as a sequence of discrete basket events indexed by visit order, which cannot explicitly model elapsed calendar time or update item rankings as days pass between purchases. We present CASE (Cadence-Aware Set Encoding for next basket repurchase recommendation), which decouples item-level cadence learning from cross-item interaction, enabling explicit calendar-time modeling while remaining production-scalable. CASE represents each item's purchase history as a calendar-time signal over a fixed horizon, applies shared multi-scale temporal convolutions to capture recurring rhythms, and uses induced set attention to model cross-item dependencies with sub-quadratic complexity, allowing efficient batch inference at scale. Across three public benchmarks and a proprietary dataset, CASE consistently improves Precision, Recall, and NDCG at multiple cutoffs compared to strong next basket prediction baselines. In a production-scale evaluation with tens of millions of users and a large item catalog, CASE achieves up to 8.6% relative Precision and 9.9% Recall lift at top-5, demonstrating that scalable cadence-aware modeling yields measurable gains in both benchmark and industrial settings.
CRAB: Codebook Rebalancing for Bias Mitigation in Generative Recommendation
Apr 06, 2026Generative recommendation (GeneRec) has introduced a new paradigm that represents items as discrete semantic tokens and predicts items in a generative manner. Despite its strong performance across multiple recommendation tasks, existing GeneRec approaches still suffer from severe popularity bias and may even exacerbate it. In this work, we conduct a comprehensive empirical analysis to uncover the root causes of this phenomenon, yielding two core insights: 1) imbalanced tokenization inherits and can further amplify popularity bias from historical item interactions; 2) current training procedures disproportionately favor popular tokens while neglecting semantic relationships among tokens, thereby intensifying popularity bias. Building on these insights, we propose CRAB, a post-hoc debiasing strategy for GeneRec that alleviates popularity bias by mitigating frequency imbalance among semantic tokens. Specifically, given a well-trained model, we first rebalance the codebook by splitting over-popular tokens while preserving their hierarchical semantic structure. Based on the adjusted codebook, we further introduce a tree-structured regularizer to enhance semantic consistency, encouraging more informative representations for unpopular tokens during training. Experiments on real-world datasets demonstrate that CRAB significantly improves recommendation performance by effectively alleviating popularity bias.
Latent Customer Segmentation and Value-Based Recommendation Leveraging a Two-Stage Model with Missing Labels
Feb 12, 2026The success of businesses depends on their ability to convert consumers into loyal customers. A customer's value proposition is a primary determinant in this process, requiring a balance between affordability and long-term brand equity. Broad marketing campaigns can erode perceived brand value and reduce return on investment, while existing economic algorithms often misidentify highly engaged customers as ideal targets, leading to inefficient engagement and conversion outcomes. This work introduces a two-stage multi-model architecture employing Self-Paced Loss to improve customer categorization. The first stage uses a multi-class neural network to distinguish customers influenced by campaigns, organically engaged customers, and low-engagement customers. The second stage applies a binary label correction model to identify true campaign-driven intent using a missing-label framework, refining customer segmentation during training. By separating prompted engagement from organic behavior, the system enables more precise campaign targeting, reduces exposure costs, and improves conversion efficiency. A/B testing demonstrates over 100 basis points improvement in key success metrics, highlighting the effectiveness of intent-aware segmentation for value-driven marketing strategies.
Campaign-2-PT-RAG: LLM-Guided Semantic Product Type Attribution for Scalable Campaign Ranking
Feb 11, 2026E-commerce campaign ranking models require large-scale training labels indicating which users purchased due to campaign influence. However, generating these labels is challenging because campaigns use creative, thematic language that does not directly map to product purchases. Without clear product-level attribution, supervised learning for campaign optimization remains limited. We present \textbf{Campaign-2-PT-RAG}, a scalable label generation framework that constructs user--campaign purchase labels by inferring which product types (PTs) each campaign promotes. The framework first interprets campaign content using large language models (LLMs) to capture implicit intent, then retrieves candidate PTs through semantic search over the platform taxonomy. A structured LLM-based classifier evaluates each PT's relevance, producing a campaign-specific product coverage set. User purchases matching these PTs generate positive training labels for downstream ranking models. This approach reframes the ambiguous attribution problem into a tractable semantic alignment task, enabling scalable and consistent supervision for downstream tasks such as campaign ranking optimization in production e-commerce environments. Experiments on internal and synthetic datasets, validated against expert-annotated campaign--PT mappings, show that our LLM-assisted approach generates high-quality labels with 78--90% precision while maintaining over 99% recall.
Segment and Matte Anything in a Unified Model
Jan 17, 2026Segment Anything (SAM) has recently pushed the boundaries of segmentation by demonstrating zero-shot generalization and flexible prompting after training on over one billion masks. Despite this, its mask prediction accuracy often falls short of the precision required in real-world applications. While several refinement modules have been proposed to boost SAM's segmentation quality, achieving highly accurate object delineation within a single, unified framework remains an open challenge. Furthermore, interactive image matting, which aims to generate fine-grained alpha mattes guided by diverse user hints, has not yet been explored in the context of SAM. Insights from recent studies highlight strong correlations between segmentation and matting, suggesting the feasibility of a unified model capable of both tasks. In this paper, we introduce Segment And Matte Anything (SAMA), a lightweight extension of SAM that delivers high-quality interactive image segmentation and matting with minimal extra parameters. Our Multi-View Localization Encoder (MVLE) captures detailed features from local views, while the Localization Adapter (Local-Adapter) refines mask outputs by recovering subtle boundary details. We also incorporate two prediction heads for each task into the architecture to generate segmentation and matting masks, simultaneously. Trained on a diverse dataset aggregated from publicly available sources, SAMA achieves state-of-the-art performance across multiple segmentation and matting benchmarks, showcasing its adaptability and effectiveness in a wide range of downstream tasks.
Is More Context Always Better? Examining LLM Reasoning Capability for Time Interval Prediction
Jan 15, 2026Large Language Models (LLMs) have demonstrated impressive capabilities in reasoning and prediction across different domains. Yet, their ability to infer temporal regularities from structured behavioral data remains underexplored. This paper presents a systematic study investigating whether LLMs can predict time intervals between recurring user actions, such as repeated purchases, and how different levels of contextual information shape their predictive behavior. Using a simple but representative repurchase scenario, we benchmark state-of-the-art LLMs in zero-shot settings against both statistical and machine-learning models. Two key findings emerge. First, while LLMs surpass lightweight statistical baselines, they consistently underperform dedicated machine-learning models, showing their limited ability to capture quantitative temporal structure. Second, although moderate context can improve LLM accuracy, adding further user-level detail degrades performance. These results challenge the assumption that "more context leads to better reasoning". Our study highlights fundamental limitations of today's LLMs in structured temporal inference and offers guidance for designing future context-aware hybrid models that integrate statistical precision with linguistic flexibility.
To See or To Read: User Behavior Reasoning in Multimodal LLMs
Nov 05, 2025Multimodal Large Language Models (MLLMs) are reshaping how modern agentic systems reason over sequential user-behavior data. However, whether textual or image representations of user behavior data are more effective for maximizing MLLM performance remains underexplored. We present \texttt{BehaviorLens}, a systematic benchmarking framework for assessing modality trade-offs in user-behavior reasoning across six MLLMs by representing transaction data as (1) a text paragraph, (2) a scatter plot, and (3) a flowchart. Using a real-world purchase-sequence dataset, we find that when data is represented as images, MLLMs next-purchase prediction accuracy is improved by 87.5% compared with an equivalent textual representation without any additional computational cost.
Spatial Reasoning in Foundation Models: Benchmarking Object-Centric Spatial Understanding
Sep 26, 2025
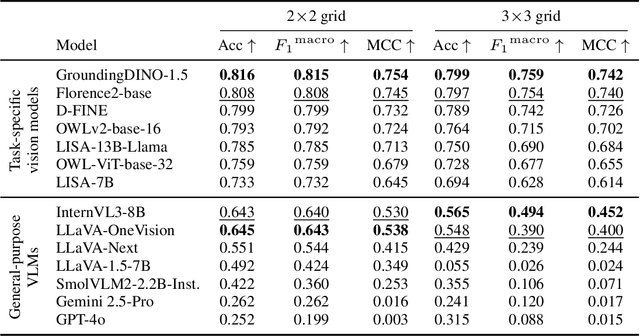

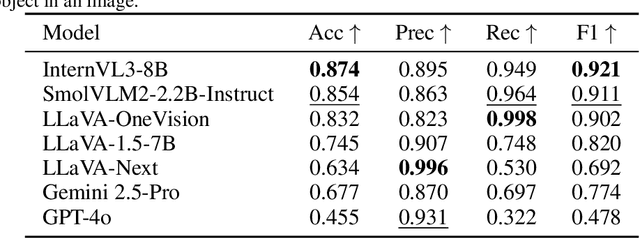
Spatial understanding is a critical capability for vision foundation models. While recent advances in large vision models or vision-language models (VLMs) have expanded recognition capabilities, most benchmarks emphasize localization accuracy rather than whether models capture how objects are arranged and related within a scene. This gap is consequential; effective scene understanding requires not only identifying objects, but reasoning about their relative positions, groupings, and depth. In this paper, we present a systematic benchmark for object-centric spatial reasoning in foundation models. Using a controlled synthetic dataset, we evaluate state-of-the-art vision models (e.g., GroundingDINO, Florence-2, OWLv2) and large VLMs (e.g., InternVL, LLaVA, GPT-4o) across three tasks: spatial localization, spatial reasoning, and downstream retrieval tasks. We find a stable trade-off: detectors such as GroundingDINO and OWLv2 deliver precise boxes with limited relational reasoning, while VLMs like SmolVLM and GPT-4o provide coarse layout cues and fluent captions but struggle with fine-grained spatial context. Our study highlights the gap between localization and true spatial understanding, and pointing toward the need for spatially-aware foundation models in the community.
VL-CLIP: Enhancing Multimodal Recommendations via Visual Grounding and LLM-Augmented CLIP Embeddings
Jul 22, 2025Multimodal learning plays a critical role in e-commerce recommendation platforms today, enabling accurate recommendations and product understanding. However, existing vision-language models, such as CLIP, face key challenges in e-commerce recommendation systems: 1) Weak object-level alignment, where global image embeddings fail to capture fine-grained product attributes, leading to suboptimal retrieval performance; 2) Ambiguous textual representations, where product descriptions often lack contextual clarity, affecting cross-modal matching; and 3) Domain mismatch, as generic vision-language models may not generalize well to e-commerce-specific data. To address these limitations, we propose a framework, VL-CLIP, that enhances CLIP embeddings by integrating Visual Grounding for fine-grained visual understanding and an LLM-based agent for generating enriched text embeddings. Visual Grounding refines image representations by localizing key products, while the LLM agent enhances textual features by disambiguating product descriptions. Our approach significantly improves retrieval accuracy, multimodal retrieval effectiveness, and recommendation quality across tens of millions of items on one of the largest e-commerce platforms in the U.S., increasing CTR by 18.6%, ATC by 15.5%, and GMV by 4.0%. Additional experimental results show that our framework outperforms vision-language models, including CLIP, FashionCLIP, and GCL, in both precision and semantic alignment, demonstrating the potential of combining object-aware visual grounding and LLM-enhanced text representation for robust multimodal recommendations.