 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs More Context Always Better? Examining LLM Reasoning Capability for Time Interval Prediction
Jan 15, 2026Large Language Models (LLMs) have demonstrated impressive capabilities in reasoning and prediction across different domains. Yet, their ability to infer temporal regularities from structured behavioral data remains underexplored. This paper presents a systematic study investigating whether LLMs can predict time intervals between recurring user actions, such as repeated purchases, and how different levels of contextual information shape their predictive behavior. Using a simple but representative repurchase scenario, we benchmark state-of-the-art LLMs in zero-shot settings against both statistical and machine-learning models. Two key findings emerge. First, while LLMs surpass lightweight statistical baselines, they consistently underperform dedicated machine-learning models, showing their limited ability to capture quantitative temporal structure. Second, although moderate context can improve LLM accuracy, adding further user-level detail degrades performance. These results challenge the assumption that "more context leads to better reasoning". Our study highlights fundamental limitations of today's LLMs in structured temporal inference and offers guidance for designing future context-aware hybrid models that integrate statistical precision with linguistic flexibility.
To See or To Read: User Behavior Reasoning in Multimodal LLMs
Nov 05, 2025Multimodal Large Language Models (MLLMs) are reshaping how modern agentic systems reason over sequential user-behavior data. However, whether textual or image representations of user behavior data are more effective for maximizing MLLM performance remains underexplored. We present \texttt{BehaviorLens}, a systematic benchmarking framework for assessing modality trade-offs in user-behavior reasoning across six MLLMs by representing transaction data as (1) a text paragraph, (2) a scatter plot, and (3) a flowchart. Using a real-world purchase-sequence dataset, we find that when data is represented as images, MLLMs next-purchase prediction accuracy is improved by 87.5% compared with an equivalent textual representation without any additional computational cost.
Improving Sequential Recommender Systems with Online and In-store User Behavior
Dec 03, 2024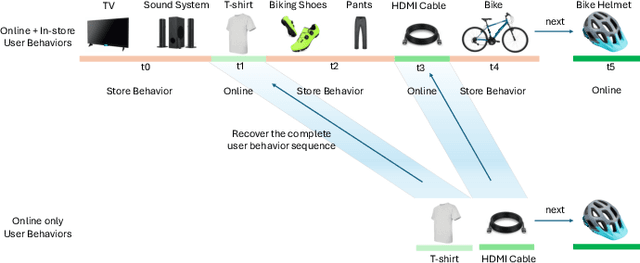
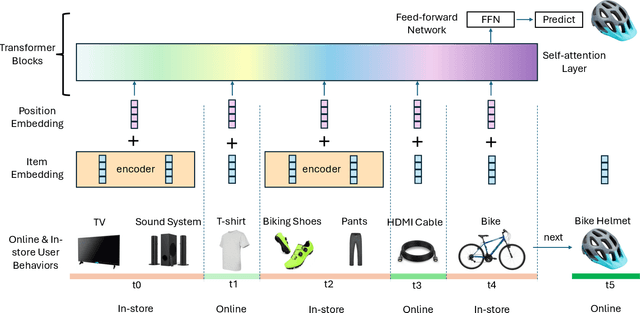
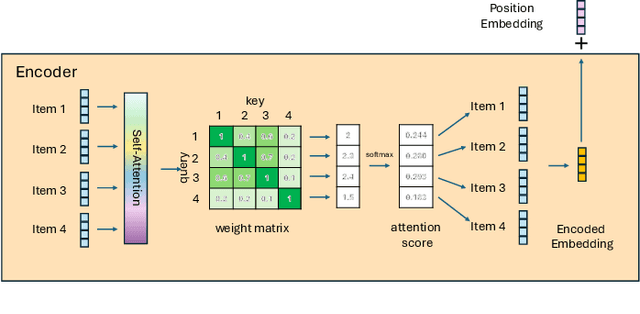

Online e-commerce platforms have been extending in-store shopping, which allows users to keep the canonical online browsing and checkout experience while exploring in-store shopping. However, the growing transition between online and in-store becomes a challenge to sequential recommender systems for future online interaction prediction due to the lack of holistic modeling of hybrid user behaviors (online and in-store). The challenges are twofold. First, combining online and in-store user behavior data into a single data schema and supporting multiple stages in the model life cycle (pre-training, training, inference, etc.) organically needs a new data pipeline design. Second, online recommender systems, which solely rely on online user behavior sequences, must be redesigned to support online and in-store user data as input under the sequential modeling setting. To overcome the first challenge, we propose a hybrid, omnichannel data pipeline to compile online and in-store user behavior data by caching information from diverse data sources. Later, we introduce a model-agnostic encoder module to the sequential recommender system to interpret the user in-store transaction and augment the modeling capacity for better online interaction prediction given the hybrid user behavior.
Triple Modality Fusion: Aligning Visual, Textual, and Graph Data with Large Language Models for Multi-Behavior Recommendations
Oct 16, 2024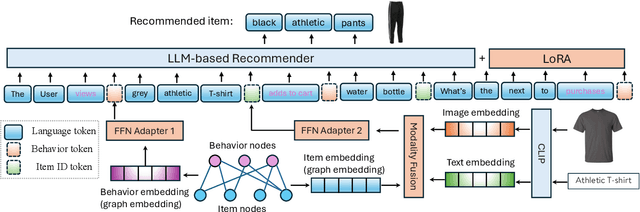
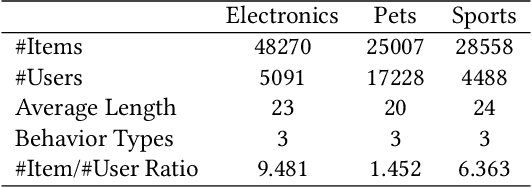
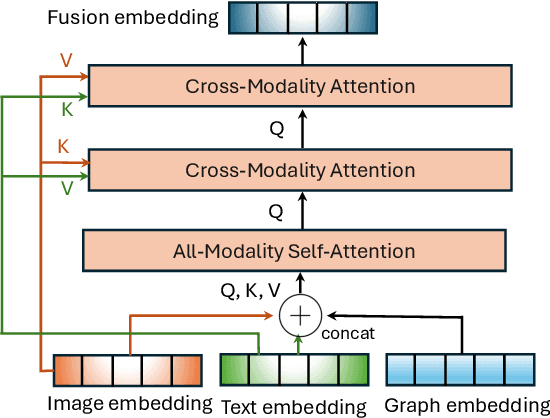
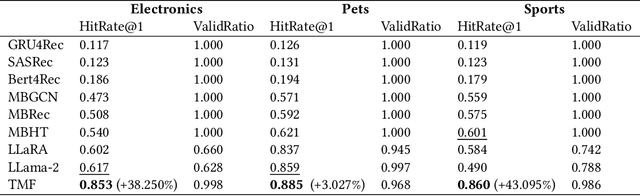
Integrating diverse data modalities is crucial for enhancing the performance of personalized recommendation systems. Traditional models, which often rely on singular data sources, lack the depth needed to accurately capture the multifaceted nature of item features and user behaviors. This paper introduces a novel framework for multi-behavior recommendations, leveraging the fusion of triple-modality, which is visual, textual, and graph data through alignment with large language models (LLMs). By incorporating visual information, we capture contextual and aesthetic item characteristics; textual data provides insights into user interests and item features in detail; and graph data elucidates relationships within the item-behavior heterogeneous graphs. Our proposed model called Triple Modality Fusion (TMF) utilizes the power of LLMs to align and integrate these three modalities, achieving a comprehensive representation of user behaviors. The LLM models the user's interactions including behaviors and item features in natural languages. Initially, the LLM is warmed up using only natural language-based prompts. We then devise the modality fusion module based on cross-attention and self-attention mechanisms to integrate different modalities from other models into the same embedding space and incorporate them into an LLM. Extensive experiments demonstrate the effectiveness of our approach in improving recommendation accuracy. Further ablation studies validate the effectiveness of our model design and benefits of the TMF.
Event-based Product Carousel Recommendation with Query-Click Graph
Feb 05, 2024Many current recommender systems mainly focus on the product-to-product recommendations and user-to-product recommendations even during the time of events rather than modeling the typical recommendations for the target event (e.g., festivals, seasonal activities, or social activities) without addressing the multiple aspects of the shopping demands for the target event. Product recommendations for the multiple aspects of the target event are usually generated by human curators who manually identify the aspects and select a list of aspect-related products (i.e., product carousel) for each aspect as recommendations. However, building a recommender system with machine learning is non-trivial due to the lack of both the ground truth of event-related aspects and the aspect-related products. To fill this gap, we define the novel problem as the event-based product carousel recommendations in e-commerce and propose an effective recommender system based on the query-click bipartite graph. We apply the iterative clustering algorithm over the query-click bipartite graph and infer the event-related aspects by the clusters of queries. The aspect-related recommendations are powered by the click-through rate of products regarding each aspect. We show through experiments that this approach effectively mines product carousels for the target event.
LLMs with User-defined Prompts as Generic Data Operators for Reliable Data Processing
Dec 26, 2023Data processing is one of the fundamental steps in machine learning pipelines to ensure data quality. Majority of the applications consider the user-defined function (UDF) design pattern for data processing in databases. Although the UDF design pattern introduces flexibility, reusability and scalability, the increasing demand on machine learning pipelines brings three new challenges to this design pattern -- not low-code, not dependency-free and not knowledge-aware. To address these challenges, we propose a new design pattern that large language models (LLMs) could work as a generic data operator (LLM-GDO) for reliable data cleansing, transformation and modeling with their human-compatible performance. In the LLM-GDO design pattern, user-defined prompts (UDPs) are used to represent the data processing logic rather than implementations with a specific programming language. LLMs can be centrally maintained so users don't have to manage the dependencies at the run-time. Fine-tuning LLMs with domain-specific data could enhance the performance on the domain-specific tasks which makes data processing knowledge-aware. We illustrate these advantages with examples in different data processing tasks. Furthermore, we summarize the challenges and opportunities introduced by LLMs to provide a complete view of this design pattern for more discussions.
Knowledge Graph Completion Models are Few-shot Learners: An Empirical Study of Relation Labeling in E-commerce with LLMs
May 17, 2023Knowledge Graphs (KGs) play a crucial role in enhancing e-commerce system performance by providing structured information about entities and their relationships, such as complementary or substitutable relations between products or product types, which can be utilized in recommender systems. However, relation labeling in KGs remains a challenging task due to the dynamic nature of e-commerce domains and the associated cost of human labor. Recently, breakthroughs in Large Language Models (LLMs) have shown surprising results in numerous natural language processing tasks. In this paper, we conduct an empirical study of LLMs for relation labeling in e-commerce KGs, investigating their powerful learning capabilities in natural language and effectiveness in predicting relations between product types with limited labeled data. We evaluate various LLMs, including PaLM and GPT-3.5, on benchmark datasets, demonstrating their ability to achieve competitive performance compared to humans on relation labeling tasks using just 1 to 5 labeled examples per relation. Additionally, we experiment with different prompt engineering techniques to examine their impact on model performance. Our results show that LLMs significantly outperform existing KG completion models in relation labeling for e-commerce KGs and exhibit performance strong enough to replace human labeling.
Mitigating Frequency Bias in Next-Basket Recommendation via Deconfounders
Nov 16, 2022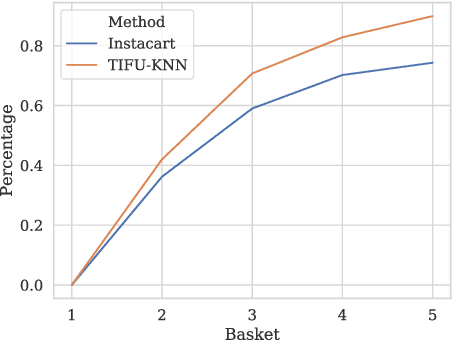
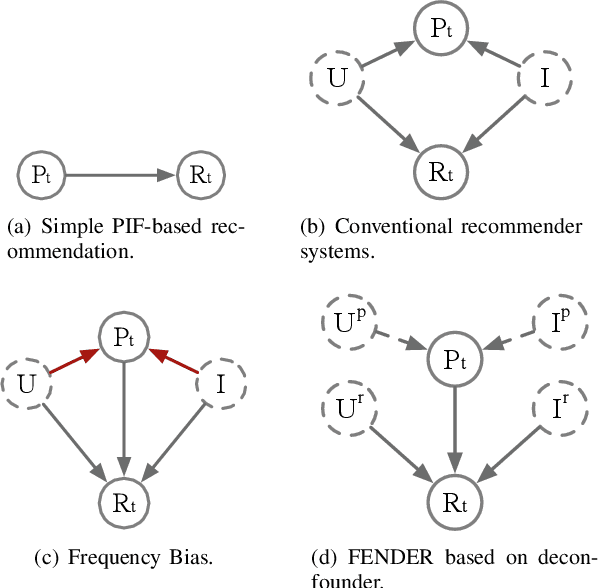
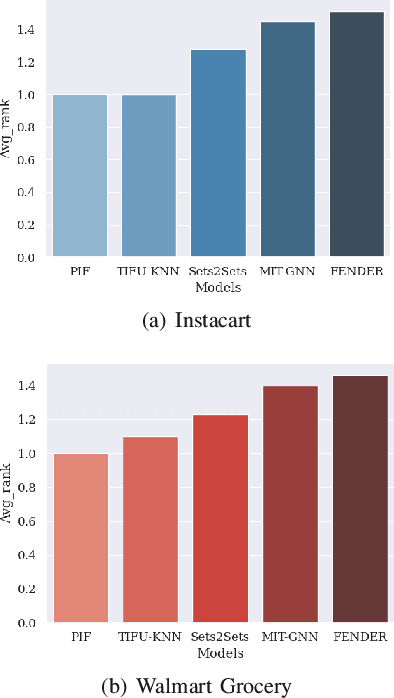
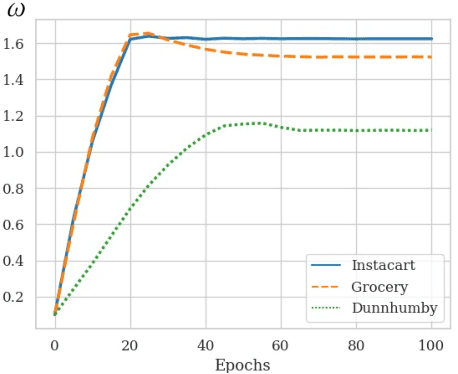
Recent studies on Next-basket Recommendation (NBR) have achieved much progress by leveraging Personalized Item Frequency (PIF) as one of the main features, which measures the frequency of the user's interactions with the item. However, taking the PIF as an explicit feature incurs bias towards frequent items. Items that a user purchases frequently are assigned higher weights in the PIF-based recommender system and appear more frequently in the personalized recommendation list. As a result, the system will lose the fairness and balance between items that the user frequently purchases and items that the user never purchases. We refer to this systematic bias on personalized recommendation lists as frequency bias, which narrows users' browsing scope and reduces the system utility. We adopt causal inference theory to address this issue. Considering the influence of historical purchases on users' future interests, the user and item representations can be viewed as unobserved confounders in the causal diagram. In this paper, we propose a deconfounder model named FENDER (Frequency-aware Deconfounder for Next-basket Recommendation) to mitigate the frequency bias. With the deconfounder theory and the causal diagram we propose, FENDER decomposes PIF with a neural tensor layer to obtain substitute confounders for users and items. Then, FENDER performs unbiased recommendations considering the effect of these substitute confounders. Experimental results demonstrate that FENDER has derived diverse and fair results compared to ten baseline models on three datasets while achieving competitive performance. Further experiments illustrate how FENDER balances users' historical purchases and potential interests.
NEAT: A Label Noise-resistant Complementary Item Recommender System with Trustworthy Evaluation
Feb 11, 2022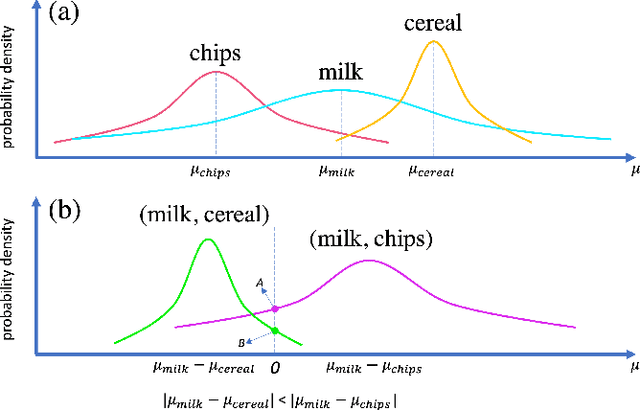
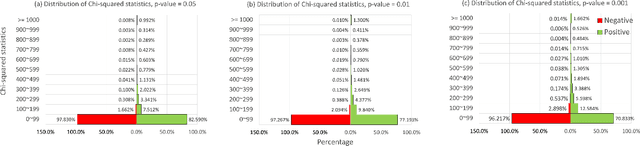


The complementary item recommender system (CIRS) recommends the complementary items for a given query item. Existing CIRS models consider the item co-purchase signal as a proxy of the complementary relationship due to the lack of human-curated labels from the huge transaction records. These methods represent items in a complementary embedding space and model the complementary relationship as a point estimation of the similarity between items vectors. However, co-purchased items are not necessarily complementary to each other. For example, customers may frequently purchase bananas and bottled water within the same transaction, but these two items are not complementary. Hence, using co-purchase signals directly as labels will aggravate the model performance. On the other hand, the model evaluation will not be trustworthy if the labels for evaluation are not reflecting the true complementary relatedness. To address the above challenges from noisy labeling of the copurchase data, we model the co-purchases of two items as a Gaussian distribution, where the mean denotes the co-purchases from the complementary relatedness, and covariance denotes the co-purchases from the noise. To do so, we represent each item as a Gaussian embedding and parameterize the Gaussian distribution of co-purchases by the means and covariances from item Gaussian embedding. To reduce the impact of the noisy labels during evaluation, we propose an independence test-based method to generate a trustworthy label set with certain confidence. Our extensive experiments on both the publicly available dataset and the large-scale real-world dataset justify the effectiveness of our proposed model in complementary item recommendations compared with the state-of-the-art models.