 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEAT: A Label Noise-resistant Complementary Item Recommender System with Trustworthy Evaluation
Paper and Code
Feb 11, 2022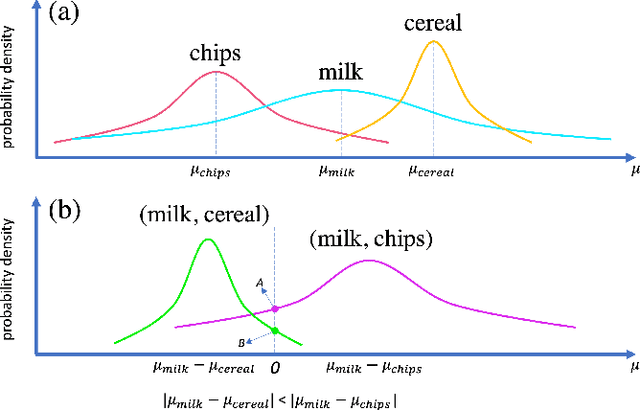
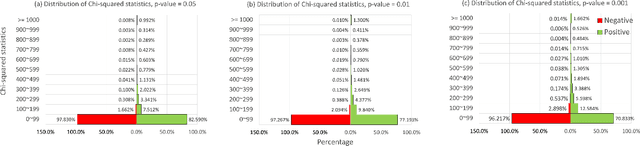


The complementary item recommender system (CIRS) recommends the complementary items for a given query item. Existing CIRS models consider the item co-purchase signal as a proxy of the complementary relationship due to the lack of human-curated labels from the huge transaction records. These methods represent items in a complementary embedding space and model the complementary relationship as a point estimation of the similarity between items vectors. However, co-purchased items are not necessarily complementary to each other. For example, customers may frequently purchase bananas and bottled water within the same transaction, but these two items are not complementary. Hence, using co-purchase signals directly as labels will aggravate the model performance. On the other hand, the model evaluation will not be trustworthy if the labels for evaluation are not reflecting the true complementary relatedness. To address the above challenges from noisy labeling of the copurchase data, we model the co-purchases of two items as a Gaussian distribution, where the mean denotes the co-purchases from the complementary relatedness, and covariance denotes the co-purchases from the noise. To do so, we represent each item as a Gaussian embedding and parameterize the Gaussian distribution of co-purchases by the means and covariances from item Gaussian embedding. To reduce the impact of the noisy labels during evaluation, we propose an independence test-based method to generate a trustworthy label set with certain confidence. Our extensive experiments on both the publicly available dataset and the large-scale real-world dataset justify the effectiveness of our proposed model in complementary item recommendations compared with the state-of-the-art models.