 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs More Context Always Better? Examining LLM Reasoning Capability for Time Interval Prediction
Jan 15, 2026Large Language Models (LLMs) have demonstrated impressive capabilities in reasoning and prediction across different domains. Yet, their ability to infer temporal regularities from structured behavioral data remains underexplored. This paper presents a systematic study investigating whether LLMs can predict time intervals between recurring user actions, such as repeated purchases, and how different levels of contextual information shape their predictive behavior. Using a simple but representative repurchase scenario, we benchmark state-of-the-art LLMs in zero-shot settings against both statistical and machine-learning models. Two key findings emerge. First, while LLMs surpass lightweight statistical baselines, they consistently underperform dedicated machine-learning models, showing their limited ability to capture quantitative temporal structure. Second, although moderate context can improve LLM accuracy, adding further user-level detail degrades performance. These results challenge the assumption that "more context leads to better reasoning". Our study highlights fundamental limitations of today's LLMs in structured temporal inference and offers guidance for designing future context-aware hybrid models that integrate statistical precision with linguistic flexibility.
Spatial Reasoning in Foundation Models: Benchmarking Object-Centric Spatial Understanding
Sep 26, 2025
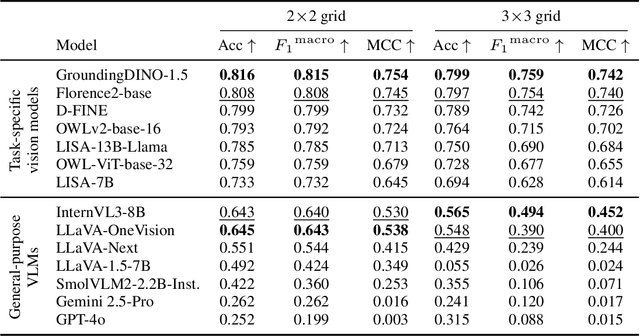

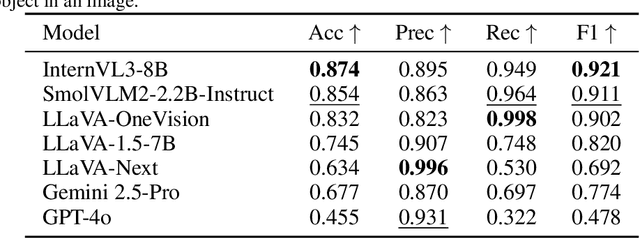
Spatial understanding is a critical capability for vision foundation models. While recent advances in large vision models or vision-language models (VLMs) have expanded recognition capabilities, most benchmarks emphasize localization accuracy rather than whether models capture how objects are arranged and related within a scene. This gap is consequential; effective scene understanding requires not only identifying objects, but reasoning about their relative positions, groupings, and depth. In this paper, we present a systematic benchmark for object-centric spatial reasoning in foundation models. Using a controlled synthetic dataset, we evaluate state-of-the-art vision models (e.g., GroundingDINO, Florence-2, OWLv2) and large VLMs (e.g., InternVL, LLaVA, GPT-4o) across three tasks: spatial localization, spatial reasoning, and downstream retrieval tasks. We find a stable trade-off: detectors such as GroundingDINO and OWLv2 deliver precise boxes with limited relational reasoning, while VLMs like SmolVLM and GPT-4o provide coarse layout cues and fluent captions but struggle with fine-grained spatial context. Our study highlights the gap between localization and true spatial understanding, and pointing toward the need for spatially-aware foundation models in the community.
VL-CLIP: Enhancing Multimodal Recommendations via Visual Grounding and LLM-Augmented CLIP Embeddings
Jul 22, 2025Multimodal learning plays a critical role in e-commerce recommendation platforms today, enabling accurate recommendations and product understanding. However, existing vision-language models, such as CLIP, face key challenges in e-commerce recommendation systems: 1) Weak object-level alignment, where global image embeddings fail to capture fine-grained product attributes, leading to suboptimal retrieval performance; 2) Ambiguous textual representations, where product descriptions often lack contextual clarity, affecting cross-modal matching; and 3) Domain mismatch, as generic vision-language models may not generalize well to e-commerce-specific data. To address these limitations, we propose a framework, VL-CLIP, that enhances CLIP embeddings by integrating Visual Grounding for fine-grained visual understanding and an LLM-based agent for generating enriched text embeddings. Visual Grounding refines image representations by localizing key products, while the LLM agent enhances textual features by disambiguating product descriptions. Our approach significantly improves retrieval accuracy, multimodal retrieval effectiveness, and recommendation quality across tens of millions of items on one of the largest e-commerce platforms in the U.S., increasing CTR by 18.6%, ATC by 15.5%, and GMV by 4.0%. Additional experimental results show that our framework outperforms vision-language models, including CLIP, FashionCLIP, and GCL, in both precision and semantic alignment, demonstrating the potential of combining object-aware visual grounding and LLM-enhanced text representation for robust multimodal recommendations.
Triple Modality Fusion: Aligning Visual, Textual, and Graph Data with Large Language Models for Multi-Behavior Recommendations
Oct 16, 2024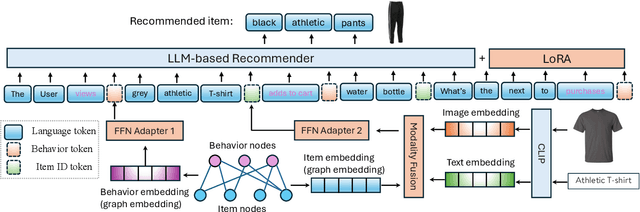
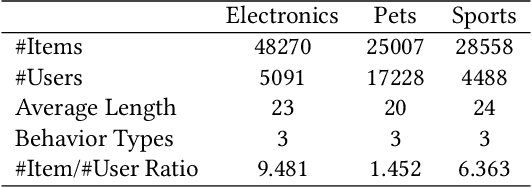
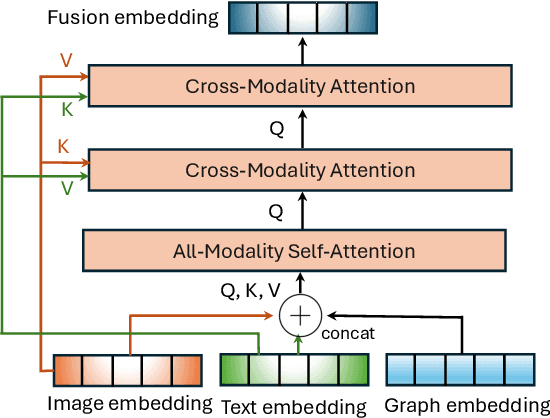
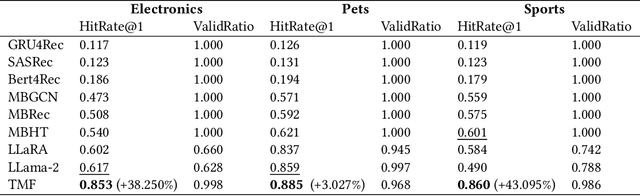
Integrating diverse data modalities is crucial for enhancing the performance of personalized recommendation systems. Traditional models, which often rely on singular data sources, lack the depth needed to accurately capture the multifaceted nature of item features and user behaviors. This paper introduces a novel framework for multi-behavior recommendations, leveraging the fusion of triple-modality, which is visual, textual, and graph data through alignment with large language models (LLMs). By incorporating visual information, we capture contextual and aesthetic item characteristics; textual data provides insights into user interests and item features in detail; and graph data elucidates relationships within the item-behavior heterogeneous graphs. Our proposed model called Triple Modality Fusion (TMF) utilizes the power of LLMs to align and integrate these three modalities, achieving a comprehensive representation of user behaviors. The LLM models the user's interactions including behaviors and item features in natural languages. Initially, the LLM is warmed up using only natural language-based prompts. We then devise the modality fusion module based on cross-attention and self-attention mechanisms to integrate different modalities from other models into the same embedding space and incorporate them into an LLM. Extensive experiments demonstrate the effectiveness of our approach in improving recommendation accuracy. Further ablation studies validate the effectiveness of our model design and benefits of the TMF.
Prompt Optimizer of Text-to-Image Diffusion Models for Abstract Concept Understanding
Apr 17, 2024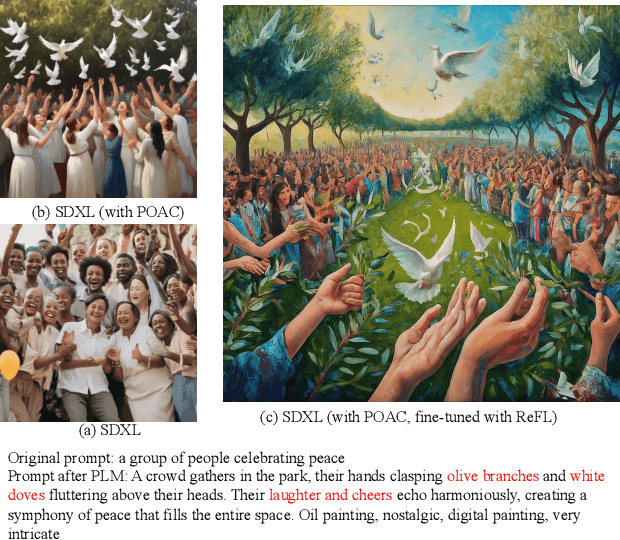
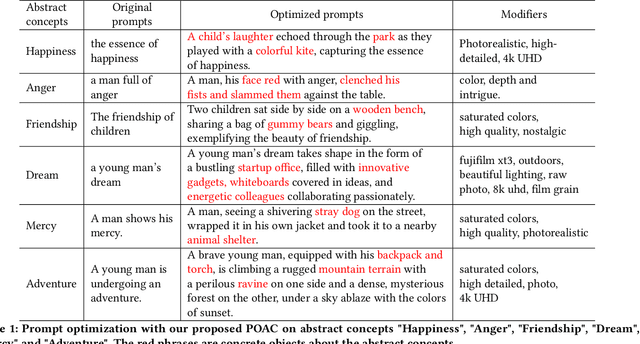
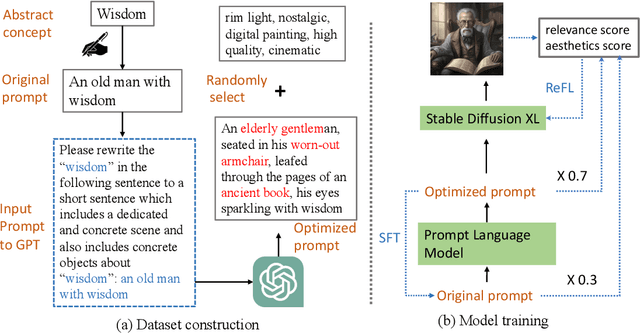

The rapid evolution of text-to-image diffusion models has opened the door of generative AI, enabling the translation of textual descriptions into visually compelling images with remarkable quality. However, a persistent challenge within this domain is the optimization of prompts to effectively convey abstract concepts into concrete objects. For example, text encoders can hardly express "peace", while can easily illustrate olive branches and white doves. This paper introduces a novel approach named Prompt Optimizer for Abstract Concepts (POAC) specifically designed to enhance the performance of text-to-image diffusion models in interpreting and generating images from abstract concepts. We propose a Prompt Language Model (PLM), which is initialized from a pre-trained language model, and then fine-tuned with a curated dataset of abstract concept prompts. The dataset is created with GPT-4 to extend the abstract concept to a scene and concrete objects. Our framework employs a Reinforcement Learning (RL)-based optimization strategy, focusing on the alignment between the generated images by a stable diffusion model and optimized prompts. Through extensive experiments, we demonstrate that our proposed POAC significantly improves the accuracy and aesthetic quality of generated images, particularly in the description of abstract concepts and alignment with optimized prompts. We also present a comprehensive analysis of our model's performance across diffusion models under different settings, showcasing its versatility and effectiveness in enhancing abstract concept representation.
LLM-Ensemble: Optimal Large Language Model Ensemble Method for E-commerce Product Attribute Value Extraction
Feb 29, 2024


Product attribute value extraction is a pivotal component in Natural Language Processing (NLP) and the contemporary e-commerce industry. The provision of precise product attribute values is fundamental in ensuring high-quality recommendations and enhancing customer satisfaction. The recently emerging Large Language Models (LLMs) have demonstrated state-of-the-art performance in numerous attribute extraction tasks, without the need for domain-specific training data. Nevertheless, varying strengths and weaknesses are exhibited by different LLMs due to the diversity in data, architectures, and hyperparameters. This variation makes them complementary to each other, with no single LLM dominating all others. Considering the diverse strengths and weaknesses of LLMs, it becomes necessary to develop an ensemble method that leverages their complementary potentials. In this paper, we propose a novel algorithm called LLM-ensemble to ensemble different LLMs' outputs for attribute value extraction. We iteratively learn the weights for different LLMs to aggregate the labels with weights to predict the final attribute value. Not only can our proposed method be proven theoretically optimal, but it also ensures efficient computation, fast convergence, and safe deployment. We have also conducted extensive experiments with various state-of-the-art LLMs, including Llama2-13B, Llama2-70B, PaLM-2, GPT-3.5, and GPT-4, on Walmart's internal data. Our offline metrics demonstrate that the LLM-ensemble method outperforms all the state-of-the-art single LLMs on Walmart's internal dataset. This method has been launched in several production models, leading to improved Gross Merchandise Volume (GMV), Click-Through Rate (CTR), Conversion Rate (CVR), and Add-to-Cart Rate (ATC).
LLMs with User-defined Prompts as Generic Data Operators for Reliable Data Processing
Dec 26, 2023Data processing is one of the fundamental steps in machine learning pipelines to ensure data quality. Majority of the applications consider the user-defined function (UDF) design pattern for data processing in databases. Although the UDF design pattern introduces flexibility, reusability and scalability, the increasing demand on machine learning pipelines brings three new challenges to this design pattern -- not low-code, not dependency-free and not knowledge-aware. To address these challenges, we propose a new design pattern that large language models (LLMs) could work as a generic data operator (LLM-GDO) for reliable data cleansing, transformation and modeling with their human-compatible performance. In the LLM-GDO design pattern, user-defined prompts (UDPs) are used to represent the data processing logic rather than implementations with a specific programming language. LLMs can be centrally maintained so users don't have to manage the dependencies at the run-time. Fine-tuning LLMs with domain-specific data could enhance the performance on the domain-specific tasks which makes data processing knowledge-aware. We illustrate these advantages with examples in different data processing tasks. Furthermore, we summarize the challenges and opportunities introduced by LLMs to provide a complete view of this design pattern for more discussions.
LLM-TAKE: Theme Aware Keyword Extraction Using Large Language Models
Dec 01, 2023

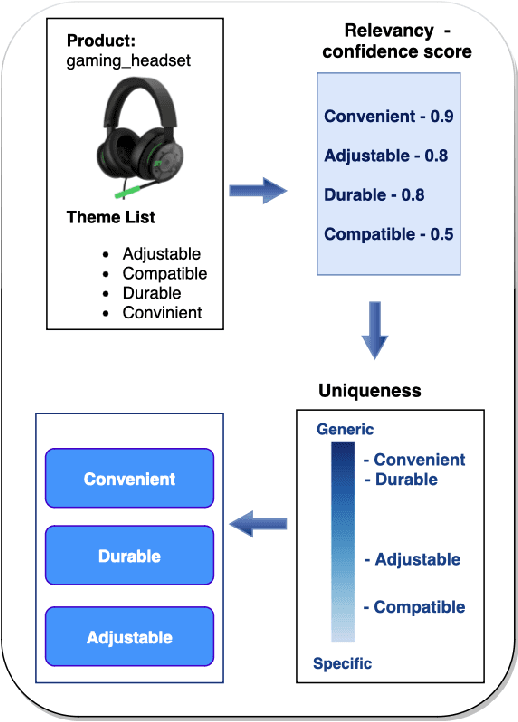
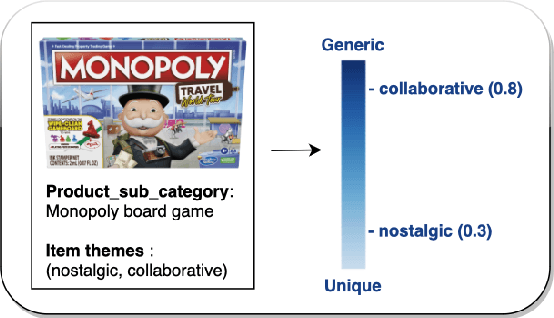
Keyword extraction is one of the core tasks in natural language processing. Classic extraction models are notorious for having a short attention span which make it hard for them to conclude relational connections among the words and sentences that are far from each other. This, in turn, makes their usage prohibitive for generating keywords that are inferred from the context of the whole text. In this paper, we explore using Large Language Models (LLMs) in generating keywords for items that are inferred from the items textual metadata. Our modeling framework includes several stages to fine grain the results by avoiding outputting keywords that are non informative or sensitive and reduce hallucinations common in LLM. We call our LLM-based framework Theme-Aware Keyword Extraction (LLM TAKE). We propose two variations of framework for generating extractive and abstractive themes for products in an E commerce setting. We perform an extensive set of experiments on three real data sets and show that our modeling framework can enhance accuracy based and diversity based metrics when compared with benchmark models.
GNN-GMVO: Graph Neural Networks for Optimizing Gross Merchandise Value in Similar Item Recommendation
Oct 26, 2023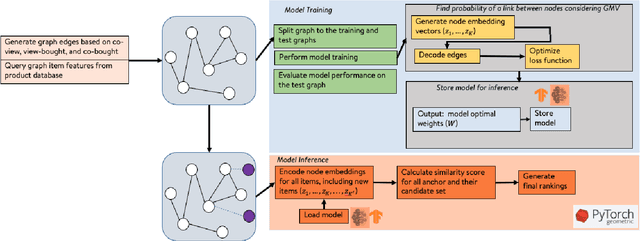

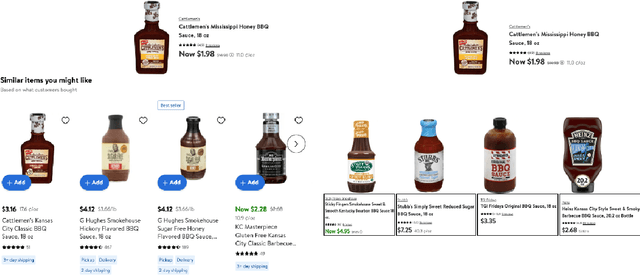

Similar item recommendation is a critical task in the e-Commerce industry, which helps customers explore similar and relevant alternatives based on their interested products. Despite the traditional machine learning models, Graph Neural Networks (GNNs), by design, can understand complex relations like similarity between products. However, in contrast to their wide usage in retrieval tasks and their focus on optimizing the relevance, the current GNN architectures are not tailored toward maximizing revenue-related objectives such as Gross Merchandise Value (GMV), which is one of the major business metrics for e-Commerce companies. In addition, defining accurate edge relations in GNNs is non-trivial in large-scale e-Commerce systems, due to the heterogeneity nature of the item-item relationships. This work aims to address these issues by designing a new GNN architecture called GNN-GMVO (Graph Neural Network - Gross Merchandise Value Optimizer). This model directly optimizes GMV while considering the complex relations between items. In addition, we propose a customized edge construction method to tailor the model toward similar item recommendation task and alleviate the noisy and complex item-item relations. In our comprehensive experiments on three real-world datasets, we show higher prediction performance and expected GMV for top ranked items recommended by our model when compared with selected state-of-the-art benchmark models.
Knowledge Graph Completion Models are Few-shot Learners: An Empirical Study of Relation Labeling in E-commerce with LLMs
May 17, 2023Knowledge Graphs (KGs) play a crucial role in enhancing e-commerce system performance by providing structured information about entities and their relationships, such as complementary or substitutable relations between products or product types, which can be utilized in recommender systems. However, relation labeling in KGs remains a challenging task due to the dynamic nature of e-commerce domains and the associated cost of human labor. Recently, breakthroughs in Large Language Models (LLMs) have shown surprising results in numerous natural language processing tasks. In this paper, we conduct an empirical study of LLMs for relation labeling in e-commerce KGs, investigating their powerful learning capabilities in natural language and effectiveness in predicting relations between product types with limited labeled data. We evaluate various LLMs, including PaLM and GPT-3.5, on benchmark datasets, demonstrating their ability to achieve competitive performance compared to humans on relation labeling tasks using just 1 to 5 labeled examples per relation. Additionally, we experiment with different prompt engineering techniques to examine their impact on model performance. Our results show that LLMs significantly outperform existing KG completion models in relation labeling for e-commerce KGs and exhibit performance strong enough to replace human labeling.