 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Customer Segmentation and Value-Based Recommendation Leveraging a Two-Stage Model with Missing Labels
Feb 12, 2026The success of businesses depends on their ability to convert consumers into loyal customers. A customer's value proposition is a primary determinant in this process, requiring a balance between affordability and long-term brand equity. Broad marketing campaigns can erode perceived brand value and reduce return on investment, while existing economic algorithms often misidentify highly engaged customers as ideal targets, leading to inefficient engagement and conversion outcomes. This work introduces a two-stage multi-model architecture employing Self-Paced Loss to improve customer categorization. The first stage uses a multi-class neural network to distinguish customers influenced by campaigns, organically engaged customers, and low-engagement customers. The second stage applies a binary label correction model to identify true campaign-driven intent using a missing-label framework, refining customer segmentation during training. By separating prompted engagement from organic behavior, the system enables more precise campaign targeting, reduces exposure costs, and improves conversion efficiency. A/B testing demonstrates over 100 basis points improvement in key success metrics, highlighting the effectiveness of intent-aware segmentation for value-driven marketing strategies.
Segment and Matte Anything in a Unified Model
Jan 17, 2026Segment Anything (SAM) has recently pushed the boundaries of segmentation by demonstrating zero-shot generalization and flexible prompting after training on over one billion masks. Despite this, its mask prediction accuracy often falls short of the precision required in real-world applications. While several refinement modules have been proposed to boost SAM's segmentation quality, achieving highly accurate object delineation within a single, unified framework remains an open challenge. Furthermore, interactive image matting, which aims to generate fine-grained alpha mattes guided by diverse user hints, has not yet been explored in the context of SAM. Insights from recent studies highlight strong correlations between segmentation and matting, suggesting the feasibility of a unified model capable of both tasks. In this paper, we introduce Segment And Matte Anything (SAMA), a lightweight extension of SAM that delivers high-quality interactive image segmentation and matting with minimal extra parameters. Our Multi-View Localization Encoder (MVLE) captures detailed features from local views, while the Localization Adapter (Local-Adapter) refines mask outputs by recovering subtle boundary details. We also incorporate two prediction heads for each task into the architecture to generate segmentation and matting masks, simultaneously. Trained on a diverse dataset aggregated from publicly available sources, SAMA achieves state-of-the-art performance across multiple segmentation and matting benchmarks, showcasing its adaptability and effectiveness in a wide range of downstream tasks.
Spatial Reasoning in Foundation Models: Benchmarking Object-Centric Spatial Understanding
Sep 26, 2025
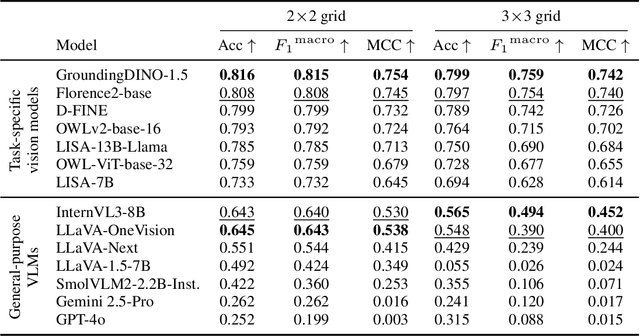

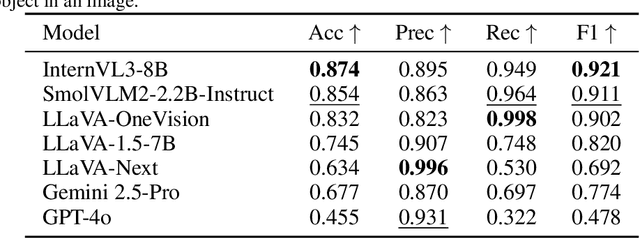
Spatial understanding is a critical capability for vision foundation models. While recent advances in large vision models or vision-language models (VLMs) have expanded recognition capabilities, most benchmarks emphasize localization accuracy rather than whether models capture how objects are arranged and related within a scene. This gap is consequential; effective scene understanding requires not only identifying objects, but reasoning about their relative positions, groupings, and depth. In this paper, we present a systematic benchmark for object-centric spatial reasoning in foundation models. Using a controlled synthetic dataset, we evaluate state-of-the-art vision models (e.g., GroundingDINO, Florence-2, OWLv2) and large VLMs (e.g., InternVL, LLaVA, GPT-4o) across three tasks: spatial localization, spatial reasoning, and downstream retrieval tasks. We find a stable trade-off: detectors such as GroundingDINO and OWLv2 deliver precise boxes with limited relational reasoning, while VLMs like SmolVLM and GPT-4o provide coarse layout cues and fluent captions but struggle with fine-grained spatial context. Our study highlights the gap between localization and true spatial understanding, and pointing toward the need for spatially-aware foundation models in the community.
VL-CLIP: Enhancing Multimodal Recommendations via Visual Grounding and LLM-Augmented CLIP Embeddings
Jul 22, 2025Multimodal learning plays a critical role in e-commerce recommendation platforms today, enabling accurate recommendations and product understanding. However, existing vision-language models, such as CLIP, face key challenges in e-commerce recommendation systems: 1) Weak object-level alignment, where global image embeddings fail to capture fine-grained product attributes, leading to suboptimal retrieval performance; 2) Ambiguous textual representations, where product descriptions often lack contextual clarity, affecting cross-modal matching; and 3) Domain mismatch, as generic vision-language models may not generalize well to e-commerce-specific data. To address these limitations, we propose a framework, VL-CLIP, that enhances CLIP embeddings by integrating Visual Grounding for fine-grained visual understanding and an LLM-based agent for generating enriched text embeddings. Visual Grounding refines image representations by localizing key products, while the LLM agent enhances textual features by disambiguating product descriptions. Our approach significantly improves retrieval accuracy, multimodal retrieval effectiveness, and recommendation quality across tens of millions of items on one of the largest e-commerce platforms in the U.S., increasing CTR by 18.6%, ATC by 15.5%, and GMV by 4.0%. Additional experimental results show that our framework outperforms vision-language models, including CLIP, FashionCLIP, and GCL, in both precision and semantic alignment, demonstrating the potential of combining object-aware visual grounding and LLM-enhanced text representation for robust multimodal recommendations.
Prompt Optimizer of Text-to-Image Diffusion Models for Abstract Concept Understanding
Apr 17, 2024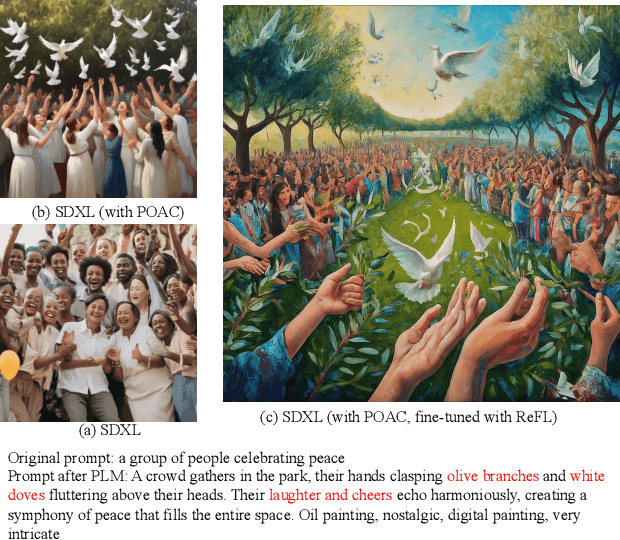
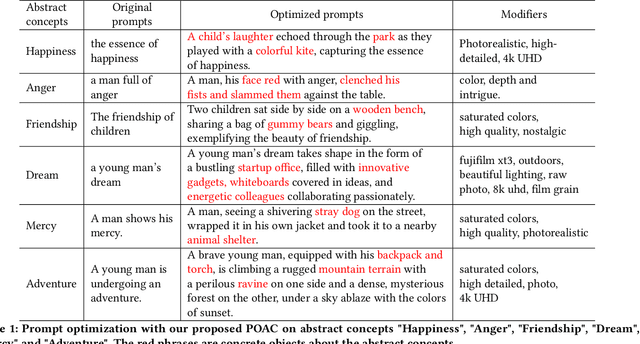
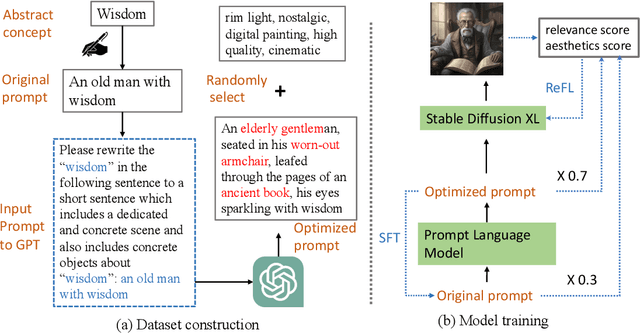

The rapid evolution of text-to-image diffusion models has opened the door of generative AI, enabling the translation of textual descriptions into visually compelling images with remarkable quality. However, a persistent challenge within this domain is the optimization of prompts to effectively convey abstract concepts into concrete objects. For example, text encoders can hardly express "peace", while can easily illustrate olive branches and white doves. This paper introduces a novel approach named Prompt Optimizer for Abstract Concepts (POAC) specifically designed to enhance the performance of text-to-image diffusion models in interpreting and generating images from abstract concepts. We propose a Prompt Language Model (PLM), which is initialized from a pre-trained language model, and then fine-tuned with a curated dataset of abstract concept prompts. The dataset is created with GPT-4 to extend the abstract concept to a scene and concrete objects. Our framework employs a Reinforcement Learning (RL)-based optimization strategy, focusing on the alignment between the generated images by a stable diffusion model and optimized prompts. Through extensive experiments, we demonstrate that our proposed POAC significantly improves the accuracy and aesthetic quality of generated images, particularly in the description of abstract concepts and alignment with optimized prompts. We also present a comprehensive analysis of our model's performance across diffusion models under different settings, showcasing its versatility and effectiveness in enhancing abstract concept representation.
Temporally Precise Action Spotting in Soccer Videos Using Dense Detection Anchors
May 20, 2022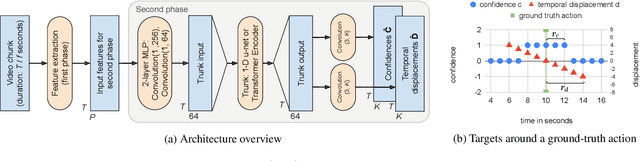
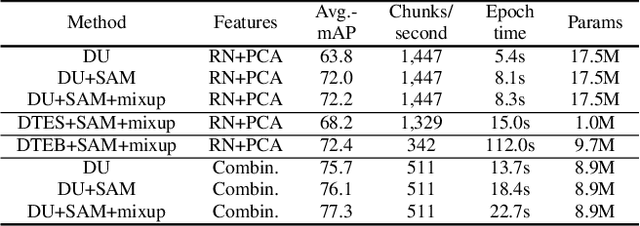
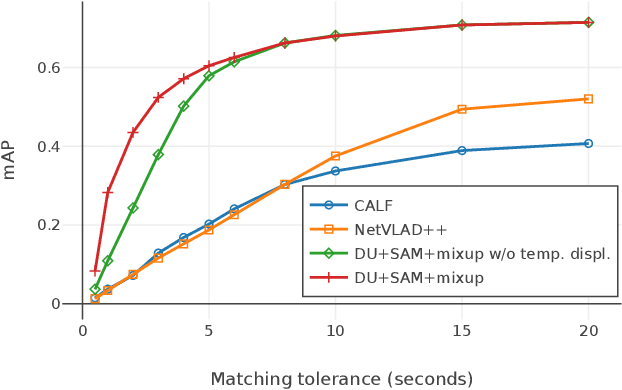
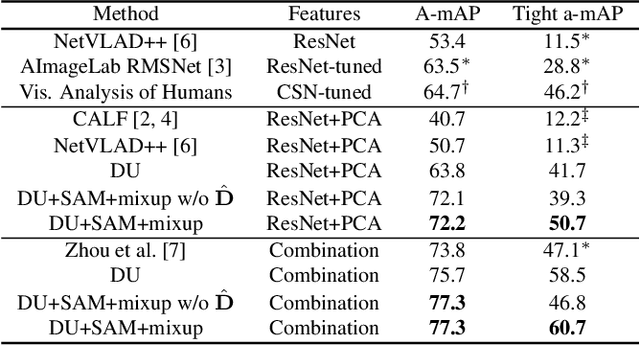
We present a model for temporally precise action spotting in videos, which uses a dense set of detection anchors, predicting a detection confidence and corresponding fine-grained temporal displacement for each anchor. We experiment with two trunk architectures, both of which are able to incorporate large temporal contexts while preserving the smaller-scale features required for precise localization: a one-dimensional version of a u-net, and a Transformer encoder (TE). We also suggest best practices for training models of this kind, by applying Sharpness-Aware Minimization (SAM) and mixup data augmentation. We achieve a new state-of-the-art on SoccerNet-v2, the largest soccer video dataset of its kind, with marked improvements in temporal localization. Additionally, our ablations show: the importance of predicting the temporal displacements; the trade-offs between the u-net and TE trunks; and the benefits of training with SAM and mixup.
Distantly Supervised Semantic Text Detection and Recognition for Broadcast Sports Videos Understanding
Oct 31, 2021
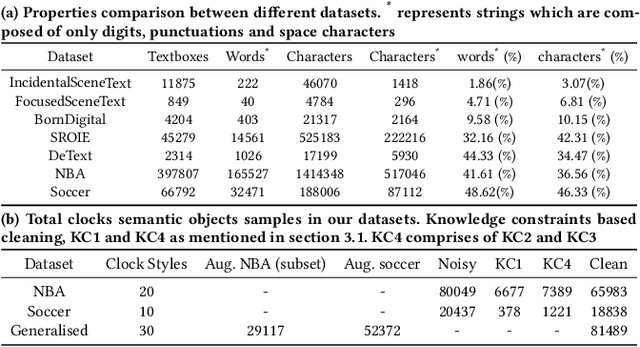
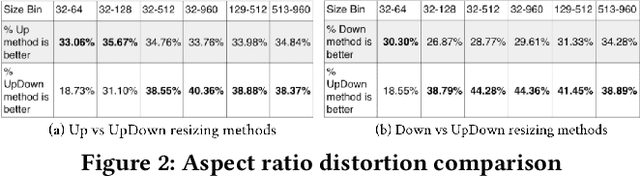
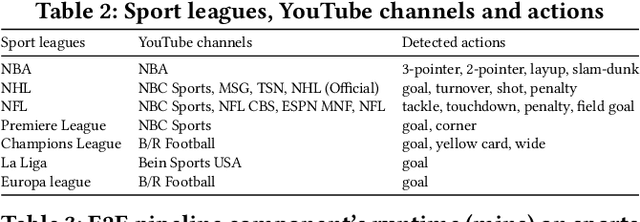
Comprehensive understanding of key players and actions in multiplayer sports broadcast videos is a challenging problem. Unlike in news or finance videos, sports videos have limited text. While both action recognition for multiplayer sports and detection of players has seen robust research, understanding contextual text in video frames still remains one of the most impactful avenues of sports video understanding. In this work we study extremely accurate semantic text detection and recognition in sports clocks, and challenges therein. We observe unique properties of sports clocks, which makes it hard to utilize general-purpose pre-trained detectors and recognizers, so that text can be accurately understood to the degree of being used to align to external knowledge. We propose a novel distant supervision technique to automatically build sports clock datasets. Along with suitable data augmentations, combined with any state-of-the-art text detection and recognition model architectures, we extract extremely accurate semantic text. Finally, we share our computational architecture pipeline to scale this system in industrial setting and proposed a robust dataset for the same to validate our results.