 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistantly Supervised Semantic Text Detection and Recognition for Broadcast Sports Videos Understanding
Paper and Code

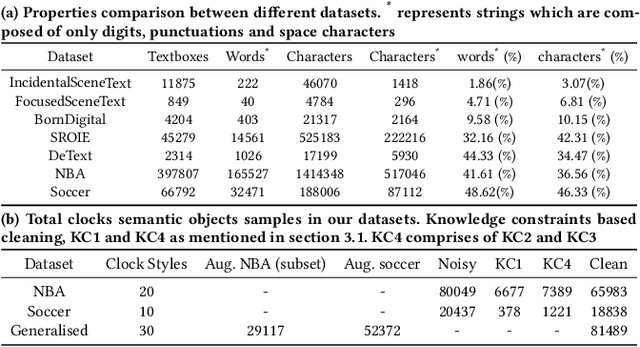
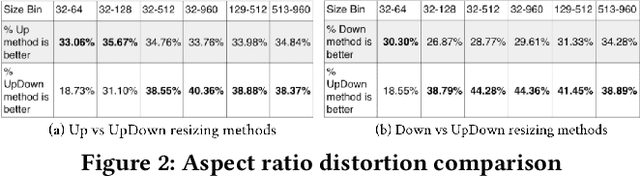
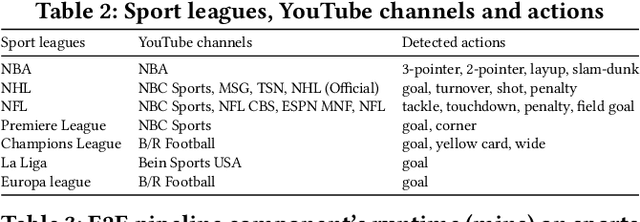
Comprehensive understanding of key players and actions in multiplayer sports broadcast videos is a challenging problem. Unlike in news or finance videos, sports videos have limited text. While both action recognition for multiplayer sports and detection of players has seen robust research, understanding contextual text in video frames still remains one of the most impactful avenues of sports video understanding. In this work we study extremely accurate semantic text detection and recognition in sports clocks, and challenges therein. We observe unique properties of sports clocks, which makes it hard to utilize general-purpose pre-trained detectors and recognizers, so that text can be accurately understood to the degree of being used to align to external knowledge. We propose a novel distant supervision technique to automatically build sports clock datasets. Along with suitable data augmentations, combined with any state-of-the-art text detection and recognition model architectures, we extract extremely accurate semantic text. Finally, we share our computational architecture pipeline to scale this system in industrial setting and proposed a robust dataset for the same to validate our results.