 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompliance Brain Assistant: Conversational Agentic AI for Assisting Compliance Tasks in Enterprise Environments
Jul 24, 2025This paper presents Compliance Brain Assistant (CBA), a conversational, agentic AI assistant designed to boost the efficiency of daily compliance tasks for personnel in enterprise environments. To strike a good balance between response quality and latency, we design a user query router that can intelligently choose between (i) FastTrack mode: to handle simple requests that only need additional relevant context retrieved from knowledge corpora; and (ii) FullAgentic mode: to handle complicated requests that need composite actions and tool invocations to proactively discover context across various compliance artifacts, and/or involving other APIs/models for accommodating requests. A typical example would be to start with a user query, use its description to find a specific entity and then use the entity's information to query other APIs for curating and enriching the final AI response. Our experimental evaluations compared CBA against an out-of-the-box LLM on various real-world privacy/compliance-related queries targeting various personas. We found that CBA substantially improved upon the vanilla LLM's performance on metrics such as average keyword match rate (83.7% vs. 41.7%) and LLM-judge pass rate (82.0% vs. 20.0%). We also compared metrics for the full routing-based design against the `fast-track only` and `full-agentic` modes and found that it had a better average match-rate and pass-rate while keeping the run-time approximately the same. This finding validated our hypothesis that the routing mechanism leads to a good trade-off between the two worlds.
Prompt Optimizer of Text-to-Image Diffusion Models for Abstract Concept Understanding
Apr 17, 2024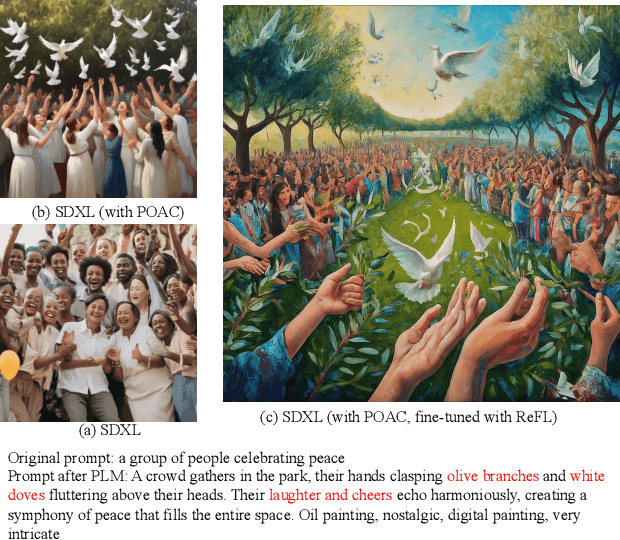
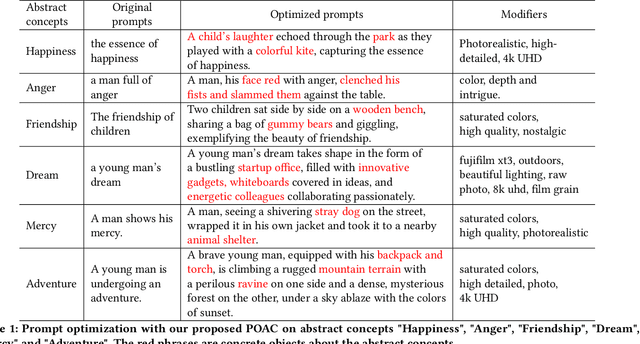
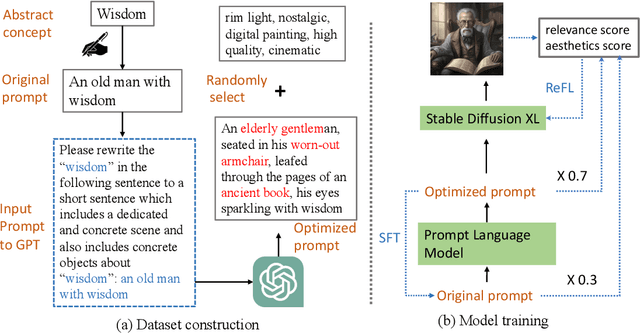

The rapid evolution of text-to-image diffusion models has opened the door of generative AI, enabling the translation of textual descriptions into visually compelling images with remarkable quality. However, a persistent challenge within this domain is the optimization of prompts to effectively convey abstract concepts into concrete objects. For example, text encoders can hardly express "peace", while can easily illustrate olive branches and white doves. This paper introduces a novel approach named Prompt Optimizer for Abstract Concepts (POAC) specifically designed to enhance the performance of text-to-image diffusion models in interpreting and generating images from abstract concepts. We propose a Prompt Language Model (PLM), which is initialized from a pre-trained language model, and then fine-tuned with a curated dataset of abstract concept prompts. The dataset is created with GPT-4 to extend the abstract concept to a scene and concrete objects. Our framework employs a Reinforcement Learning (RL)-based optimization strategy, focusing on the alignment between the generated images by a stable diffusion model and optimized prompts. Through extensive experiments, we demonstrate that our proposed POAC significantly improves the accuracy and aesthetic quality of generated images, particularly in the description of abstract concepts and alignment with optimized prompts. We also present a comprehensive analysis of our model's performance across diffusion models under different settings, showcasing its versatility and effectiveness in enhancing abstract concept representation.
LLM-Ensemble: Optimal Large Language Model Ensemble Method for E-commerce Product Attribute Value Extraction
Feb 29, 2024


Product attribute value extraction is a pivotal component in Natural Language Processing (NLP) and the contemporary e-commerce industry. The provision of precise product attribute values is fundamental in ensuring high-quality recommendations and enhancing customer satisfaction. The recently emerging Large Language Models (LLMs) have demonstrated state-of-the-art performance in numerous attribute extraction tasks, without the need for domain-specific training data. Nevertheless, varying strengths and weaknesses are exhibited by different LLMs due to the diversity in data, architectures, and hyperparameters. This variation makes them complementary to each other, with no single LLM dominating all others. Considering the diverse strengths and weaknesses of LLMs, it becomes necessary to develop an ensemble method that leverages their complementary potentials. In this paper, we propose a novel algorithm called LLM-ensemble to ensemble different LLMs' outputs for attribute value extraction. We iteratively learn the weights for different LLMs to aggregate the labels with weights to predict the final attribute value. Not only can our proposed method be proven theoretically optimal, but it also ensures efficient computation, fast convergence, and safe deployment. We have also conducted extensive experiments with various state-of-the-art LLMs, including Llama2-13B, Llama2-70B, PaLM-2, GPT-3.5, and GPT-4, on Walmart's internal data. Our offline metrics demonstrate that the LLM-ensemble method outperforms all the state-of-the-art single LLMs on Walmart's internal dataset. This method has been launched in several production models, leading to improved Gross Merchandise Volume (GMV), Click-Through Rate (CTR), Conversion Rate (CVR), and Add-to-Cart Rate (ATC).
LLM-TAKE: Theme Aware Keyword Extraction Using Large Language Models
Dec 01, 2023

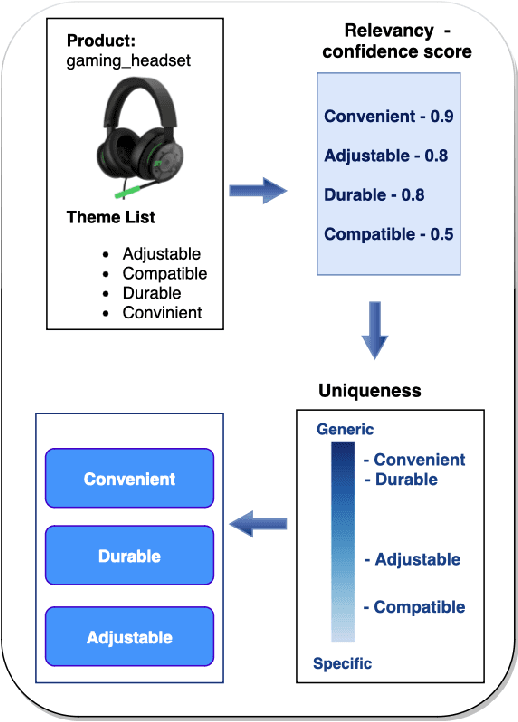
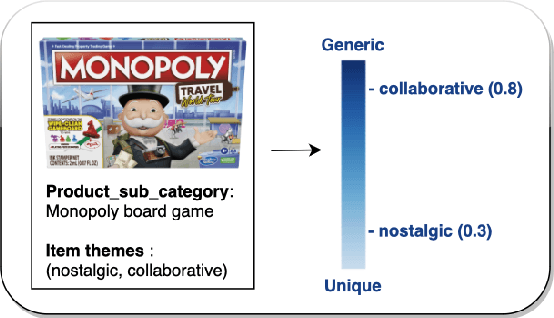
Keyword extraction is one of the core tasks in natural language processing. Classic extraction models are notorious for having a short attention span which make it hard for them to conclude relational connections among the words and sentences that are far from each other. This, in turn, makes their usage prohibitive for generating keywords that are inferred from the context of the whole text. In this paper, we explore using Large Language Models (LLMs) in generating keywords for items that are inferred from the items textual metadata. Our modeling framework includes several stages to fine grain the results by avoiding outputting keywords that are non informative or sensitive and reduce hallucinations common in LLM. We call our LLM-based framework Theme-Aware Keyword Extraction (LLM TAKE). We propose two variations of framework for generating extractive and abstractive themes for products in an E commerce setting. We perform an extensive set of experiments on three real data sets and show that our modeling framework can enhance accuracy based and diversity based metrics when compared with benchmark models.