 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegment and Matte Anything in a Unified Model
Jan 17, 2026Segment Anything (SAM) has recently pushed the boundaries of segmentation by demonstrating zero-shot generalization and flexible prompting after training on over one billion masks. Despite this, its mask prediction accuracy often falls short of the precision required in real-world applications. While several refinement modules have been proposed to boost SAM's segmentation quality, achieving highly accurate object delineation within a single, unified framework remains an open challenge. Furthermore, interactive image matting, which aims to generate fine-grained alpha mattes guided by diverse user hints, has not yet been explored in the context of SAM. Insights from recent studies highlight strong correlations between segmentation and matting, suggesting the feasibility of a unified model capable of both tasks. In this paper, we introduce Segment And Matte Anything (SAMA), a lightweight extension of SAM that delivers high-quality interactive image segmentation and matting with minimal extra parameters. Our Multi-View Localization Encoder (MVLE) captures detailed features from local views, while the Localization Adapter (Local-Adapter) refines mask outputs by recovering subtle boundary details. We also incorporate two prediction heads for each task into the architecture to generate segmentation and matting masks, simultaneously. Trained on a diverse dataset aggregated from publicly available sources, SAMA achieves state-of-the-art performance across multiple segmentation and matting benchmarks, showcasing its adaptability and effectiveness in a wide range of downstream tasks.
Triple Modality Fusion: Aligning Visual, Textual, and Graph Data with Large Language Models for Multi-Behavior Recommendations
Oct 16, 2024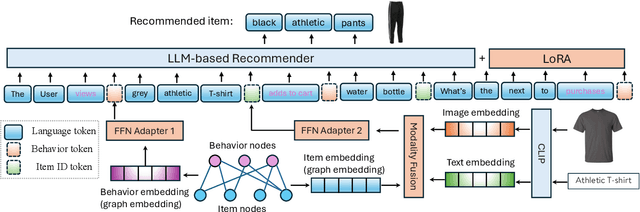
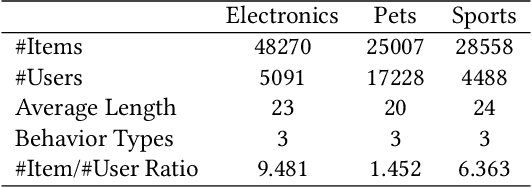
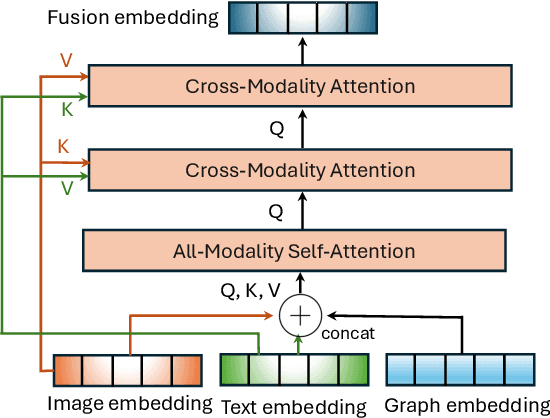
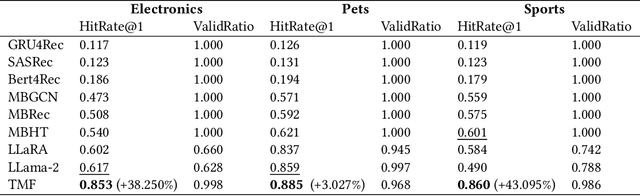
Integrating diverse data modalities is crucial for enhancing the performance of personalized recommendation systems. Traditional models, which often rely on singular data sources, lack the depth needed to accurately capture the multifaceted nature of item features and user behaviors. This paper introduces a novel framework for multi-behavior recommendations, leveraging the fusion of triple-modality, which is visual, textual, and graph data through alignment with large language models (LLMs). By incorporating visual information, we capture contextual and aesthetic item characteristics; textual data provides insights into user interests and item features in detail; and graph data elucidates relationships within the item-behavior heterogeneous graphs. Our proposed model called Triple Modality Fusion (TMF) utilizes the power of LLMs to align and integrate these three modalities, achieving a comprehensive representation of user behaviors. The LLM models the user's interactions including behaviors and item features in natural languages. Initially, the LLM is warmed up using only natural language-based prompts. We then devise the modality fusion module based on cross-attention and self-attention mechanisms to integrate different modalities from other models into the same embedding space and incorporate them into an LLM. Extensive experiments demonstrate the effectiveness of our approach in improving recommendation accuracy. Further ablation studies validate the effectiveness of our model design and benefits of the TMF.
Prompt Optimizer of Text-to-Image Diffusion Models for Abstract Concept Understanding
Apr 17, 2024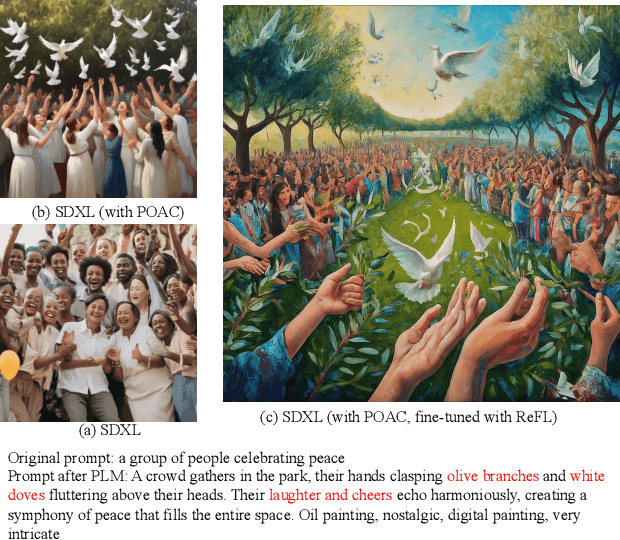
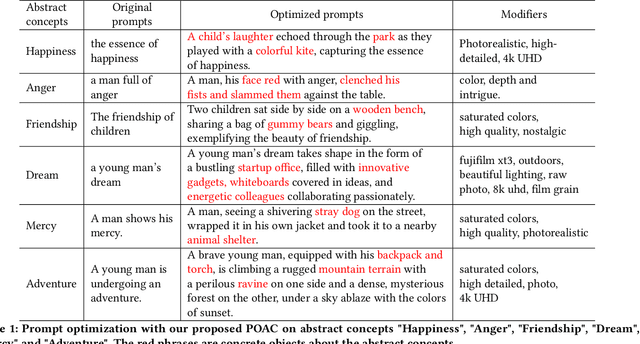
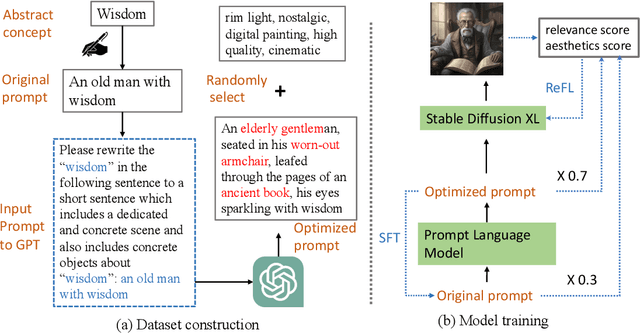

The rapid evolution of text-to-image diffusion models has opened the door of generative AI, enabling the translation of textual descriptions into visually compelling images with remarkable quality. However, a persistent challenge within this domain is the optimization of prompts to effectively convey abstract concepts into concrete objects. For example, text encoders can hardly express "peace", while can easily illustrate olive branches and white doves. This paper introduces a novel approach named Prompt Optimizer for Abstract Concepts (POAC) specifically designed to enhance the performance of text-to-image diffusion models in interpreting and generating images from abstract concepts. We propose a Prompt Language Model (PLM), which is initialized from a pre-trained language model, and then fine-tuned with a curated dataset of abstract concept prompts. The dataset is created with GPT-4 to extend the abstract concept to a scene and concrete objects. Our framework employs a Reinforcement Learning (RL)-based optimization strategy, focusing on the alignment between the generated images by a stable diffusion model and optimized prompts. Through extensive experiments, we demonstrate that our proposed POAC significantly improves the accuracy and aesthetic quality of generated images, particularly in the description of abstract concepts and alignment with optimized prompts. We also present a comprehensive analysis of our model's performance across diffusion models under different settings, showcasing its versatility and effectiveness in enhancing abstract concept representation.
LLM-Ensemble: Optimal Large Language Model Ensemble Method for E-commerce Product Attribute Value Extraction
Feb 29, 2024


Product attribute value extraction is a pivotal component in Natural Language Processing (NLP) and the contemporary e-commerce industry. The provision of precise product attribute values is fundamental in ensuring high-quality recommendations and enhancing customer satisfaction. The recently emerging Large Language Models (LLMs) have demonstrated state-of-the-art performance in numerous attribute extraction tasks, without the need for domain-specific training data. Nevertheless, varying strengths and weaknesses are exhibited by different LLMs due to the diversity in data, architectures, and hyperparameters. This variation makes them complementary to each other, with no single LLM dominating all others. Considering the diverse strengths and weaknesses of LLMs, it becomes necessary to develop an ensemble method that leverages their complementary potentials. In this paper, we propose a novel algorithm called LLM-ensemble to ensemble different LLMs' outputs for attribute value extraction. We iteratively learn the weights for different LLMs to aggregate the labels with weights to predict the final attribute value. Not only can our proposed method be proven theoretically optimal, but it also ensures efficient computation, fast convergence, and safe deployment. We have also conducted extensive experiments with various state-of-the-art LLMs, including Llama2-13B, Llama2-70B, PaLM-2, GPT-3.5, and GPT-4, on Walmart's internal data. Our offline metrics demonstrate that the LLM-ensemble method outperforms all the state-of-the-art single LLMs on Walmart's internal dataset. This method has been launched in several production models, leading to improved Gross Merchandise Volume (GMV), Click-Through Rate (CTR), Conversion Rate (CVR), and Add-to-Cart Rate (ATC).