 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriple Modality Fusion: Aligning Visual, Textual, and Graph Data with Large Language Models for Multi-Behavior Recommendations
Paper and Code
Oct 16, 2024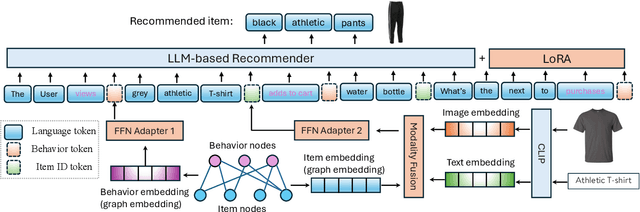
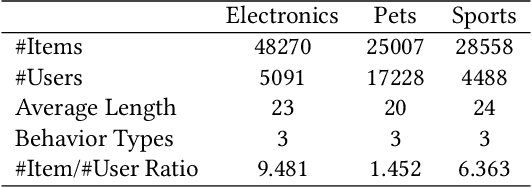
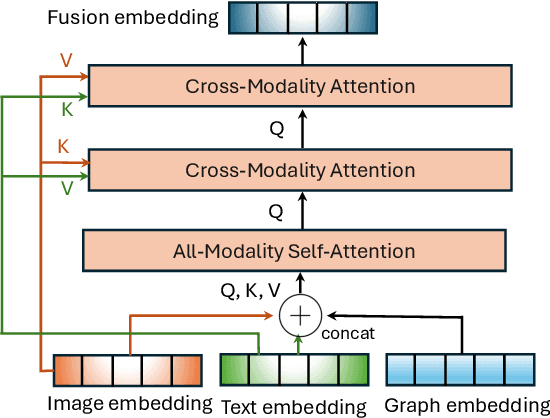
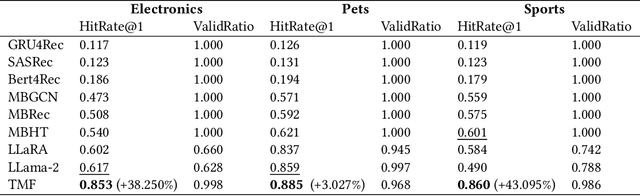
Integrating diverse data modalities is crucial for enhancing the performance of personalized recommendation systems. Traditional models, which often rely on singular data sources, lack the depth needed to accurately capture the multifaceted nature of item features and user behaviors. This paper introduces a novel framework for multi-behavior recommendations, leveraging the fusion of triple-modality, which is visual, textual, and graph data through alignment with large language models (LLMs). By incorporating visual information, we capture contextual and aesthetic item characteristics; textual data provides insights into user interests and item features in detail; and graph data elucidates relationships within the item-behavior heterogeneous graphs. Our proposed model called Triple Modality Fusion (TMF) utilizes the power of LLMs to align and integrate these three modalities, achieving a comprehensive representation of user behaviors. The LLM models the user's interactions including behaviors and item features in natural languages. Initially, the LLM is warmed up using only natural language-based prompts. We then devise the modality fusion module based on cross-attention and self-attention mechanisms to integrate different modalities from other models into the same embedding space and incorporate them into an LLM. Extensive experiments demonstrate the effectiveness of our approach in improving recommendation accuracy. Further ablation studies validate the effectiveness of our model design and benefits of the TMF.