 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCASE: Cadence-Aware Set Encoding for Large-Scale Next Basket Repurchase Recommendation
Apr 09, 2026Repurchase behavior is a primary signal in large-scale retail recommendation, particularly in categories with frequent replenishment: many items in a user's next basket were previously purchased and their timing follows stable, item-specific cadences. Yet most next basket repurchase recommendation models represent history as a sequence of discrete basket events indexed by visit order, which cannot explicitly model elapsed calendar time or update item rankings as days pass between purchases. We present CASE (Cadence-Aware Set Encoding for next basket repurchase recommendation), which decouples item-level cadence learning from cross-item interaction, enabling explicit calendar-time modeling while remaining production-scalable. CASE represents each item's purchase history as a calendar-time signal over a fixed horizon, applies shared multi-scale temporal convolutions to capture recurring rhythms, and uses induced set attention to model cross-item dependencies with sub-quadratic complexity, allowing efficient batch inference at scale. Across three public benchmarks and a proprietary dataset, CASE consistently improves Precision, Recall, and NDCG at multiple cutoffs compared to strong next basket prediction baselines. In a production-scale evaluation with tens of millions of users and a large item catalog, CASE achieves up to 8.6% relative Precision and 9.9% Recall lift at top-5, demonstrating that scalable cadence-aware modeling yields measurable gains in both benchmark and industrial settings.
CRAB: Codebook Rebalancing for Bias Mitigation in Generative Recommendation
Apr 06, 2026Generative recommendation (GeneRec) has introduced a new paradigm that represents items as discrete semantic tokens and predicts items in a generative manner. Despite its strong performance across multiple recommendation tasks, existing GeneRec approaches still suffer from severe popularity bias and may even exacerbate it. In this work, we conduct a comprehensive empirical analysis to uncover the root causes of this phenomenon, yielding two core insights: 1) imbalanced tokenization inherits and can further amplify popularity bias from historical item interactions; 2) current training procedures disproportionately favor popular tokens while neglecting semantic relationships among tokens, thereby intensifying popularity bias. Building on these insights, we propose CRAB, a post-hoc debiasing strategy for GeneRec that alleviates popularity bias by mitigating frequency imbalance among semantic tokens. Specifically, given a well-trained model, we first rebalance the codebook by splitting over-popular tokens while preserving their hierarchical semantic structure. Based on the adjusted codebook, we further introduce a tree-structured regularizer to enhance semantic consistency, encouraging more informative representations for unpopular tokens during training. Experiments on real-world datasets demonstrate that CRAB significantly improves recommendation performance by effectively alleviating popularity bias.
Segment and Matte Anything in a Unified Model
Jan 17, 2026Segment Anything (SAM) has recently pushed the boundaries of segmentation by demonstrating zero-shot generalization and flexible prompting after training on over one billion masks. Despite this, its mask prediction accuracy often falls short of the precision required in real-world applications. While several refinement modules have been proposed to boost SAM's segmentation quality, achieving highly accurate object delineation within a single, unified framework remains an open challenge. Furthermore, interactive image matting, which aims to generate fine-grained alpha mattes guided by diverse user hints, has not yet been explored in the context of SAM. Insights from recent studies highlight strong correlations between segmentation and matting, suggesting the feasibility of a unified model capable of both tasks. In this paper, we introduce Segment And Matte Anything (SAMA), a lightweight extension of SAM that delivers high-quality interactive image segmentation and matting with minimal extra parameters. Our Multi-View Localization Encoder (MVLE) captures detailed features from local views, while the Localization Adapter (Local-Adapter) refines mask outputs by recovering subtle boundary details. We also incorporate two prediction heads for each task into the architecture to generate segmentation and matting masks, simultaneously. Trained on a diverse dataset aggregated from publicly available sources, SAMA achieves state-of-the-art performance across multiple segmentation and matting benchmarks, showcasing its adaptability and effectiveness in a wide range of downstream tasks.
Is More Context Always Better? Examining LLM Reasoning Capability for Time Interval Prediction
Jan 15, 2026Large Language Models (LLMs) have demonstrated impressive capabilities in reasoning and prediction across different domains. Yet, their ability to infer temporal regularities from structured behavioral data remains underexplored. This paper presents a systematic study investigating whether LLMs can predict time intervals between recurring user actions, such as repeated purchases, and how different levels of contextual information shape their predictive behavior. Using a simple but representative repurchase scenario, we benchmark state-of-the-art LLMs in zero-shot settings against both statistical and machine-learning models. Two key findings emerge. First, while LLMs surpass lightweight statistical baselines, they consistently underperform dedicated machine-learning models, showing their limited ability to capture quantitative temporal structure. Second, although moderate context can improve LLM accuracy, adding further user-level detail degrades performance. These results challenge the assumption that "more context leads to better reasoning". Our study highlights fundamental limitations of today's LLMs in structured temporal inference and offers guidance for designing future context-aware hybrid models that integrate statistical precision with linguistic flexibility.
Spatial Reasoning in Foundation Models: Benchmarking Object-Centric Spatial Understanding
Sep 26, 2025
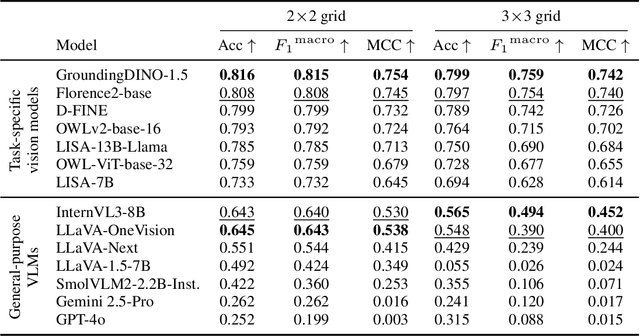

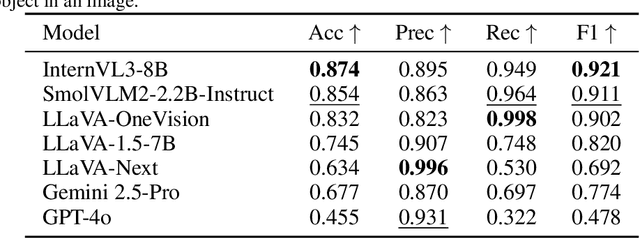
Spatial understanding is a critical capability for vision foundation models. While recent advances in large vision models or vision-language models (VLMs) have expanded recognition capabilities, most benchmarks emphasize localization accuracy rather than whether models capture how objects are arranged and related within a scene. This gap is consequential; effective scene understanding requires not only identifying objects, but reasoning about their relative positions, groupings, and depth. In this paper, we present a systematic benchmark for object-centric spatial reasoning in foundation models. Using a controlled synthetic dataset, we evaluate state-of-the-art vision models (e.g., GroundingDINO, Florence-2, OWLv2) and large VLMs (e.g., InternVL, LLaVA, GPT-4o) across three tasks: spatial localization, spatial reasoning, and downstream retrieval tasks. We find a stable trade-off: detectors such as GroundingDINO and OWLv2 deliver precise boxes with limited relational reasoning, while VLMs like SmolVLM and GPT-4o provide coarse layout cues and fluent captions but struggle with fine-grained spatial context. Our study highlights the gap between localization and true spatial understanding, and pointing toward the need for spatially-aware foundation models in the community.
FUTURE: Flexible Unlearning for Tree Ensemble
Aug 28, 2025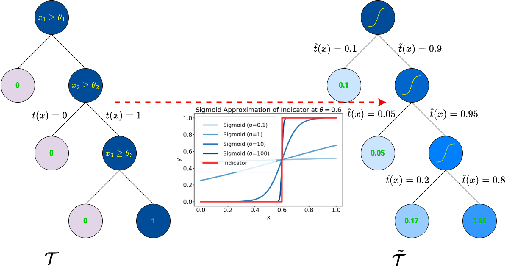
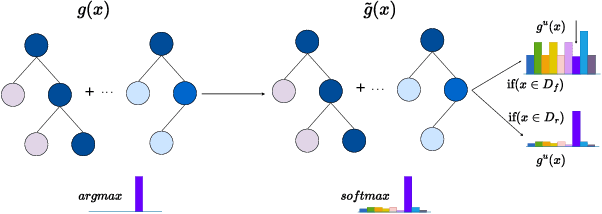
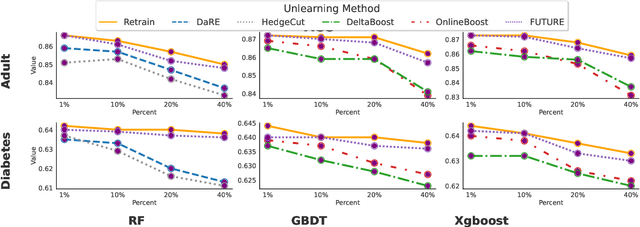
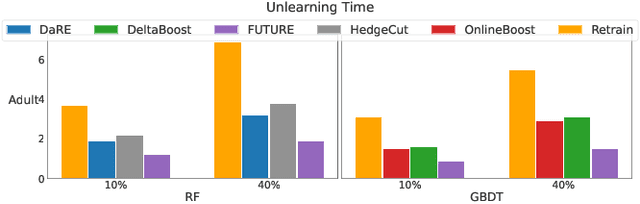
Tree ensembles are widely recognized for their effectiveness in classification tasks, achieving state-of-the-art performance across diverse domains, including bioinformatics, finance, and medical diagnosis. With increasing emphasis on data privacy and the \textit{right to be forgotten}, several unlearning algorithms have been proposed to enable tree ensembles to forget sensitive information. However, existing methods are often tailored to a particular model or rely on the discrete tree structure, making them difficult to generalize to complex ensembles and inefficient for large-scale datasets. To address these limitations, we propose FUTURE, a novel unlearning algorithm for tree ensembles. Specifically, we formulate the problem of forgetting samples as a gradient-based optimization task. In order to accommodate non-differentiability of tree ensembles, we adopt the probabilistic model approximations within the optimization framework. This enables end-to-end unlearning in an effective and efficient manner. Extensive experiments on real-world datasets show that FUTURE yields significant and successful unlearning performance.
Improving Sequential Recommender Systems with Online and In-store User Behavior
Dec 03, 2024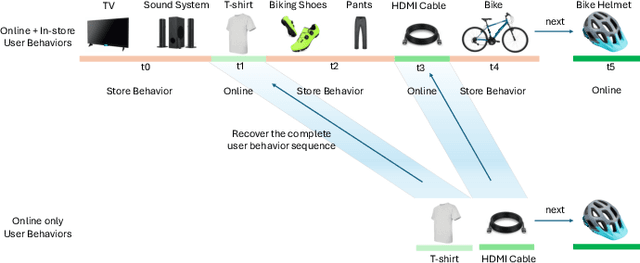
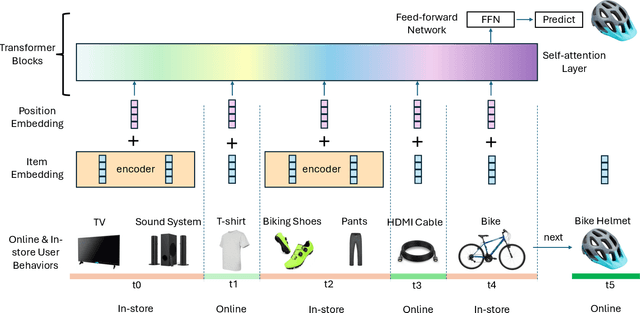
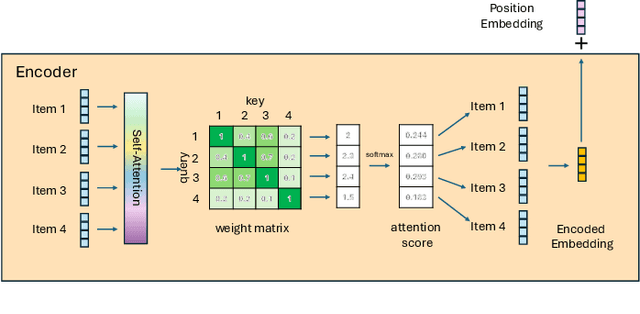

Online e-commerce platforms have been extending in-store shopping, which allows users to keep the canonical online browsing and checkout experience while exploring in-store shopping. However, the growing transition between online and in-store becomes a challenge to sequential recommender systems for future online interaction prediction due to the lack of holistic modeling of hybrid user behaviors (online and in-store). The challenges are twofold. First, combining online and in-store user behavior data into a single data schema and supporting multiple stages in the model life cycle (pre-training, training, inference, etc.) organically needs a new data pipeline design. Second, online recommender systems, which solely rely on online user behavior sequences, must be redesigned to support online and in-store user data as input under the sequential modeling setting. To overcome the first challenge, we propose a hybrid, omnichannel data pipeline to compile online and in-store user behavior data by caching information from diverse data sources. Later, we introduce a model-agnostic encoder module to the sequential recommender system to interpret the user in-store transaction and augment the modeling capacity for better online interaction prediction given the hybrid user behavior.
Triple Modality Fusion: Aligning Visual, Textual, and Graph Data with Large Language Models for Multi-Behavior Recommendations
Oct 16, 2024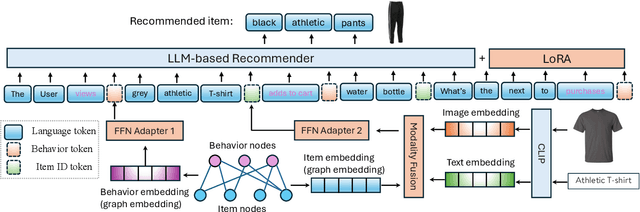
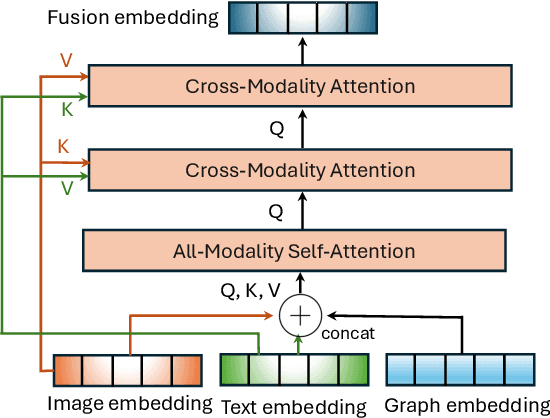
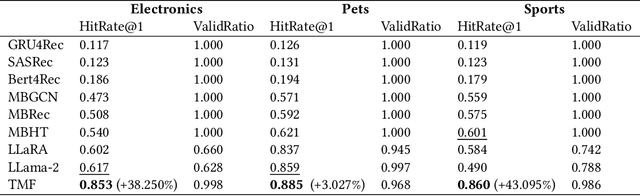
Integrating diverse data modalities is crucial for enhancing the performance of personalized recommendation systems. Traditional models, which often rely on singular data sources, lack the depth needed to accurately capture the multifaceted nature of item features and user behaviors. This paper introduces a novel framework for multi-behavior recommendations, leveraging the fusion of triple-modality, which is visual, textual, and graph data through alignment with large language models (LLMs). By incorporating visual information, we capture contextual and aesthetic item characteristics; textual data provides insights into user interests and item features in detail; and graph data elucidates relationships within the item-behavior heterogeneous graphs. Our proposed model called Triple Modality Fusion (TMF) utilizes the power of LLMs to align and integrate these three modalities, achieving a comprehensive representation of user behaviors. The LLM models the user's interactions including behaviors and item features in natural languages. Initially, the LLM is warmed up using only natural language-based prompts. We then devise the modality fusion module based on cross-attention and self-attention mechanisms to integrate different modalities from other models into the same embedding space and incorporate them into an LLM. Extensive experiments demonstrate the effectiveness of our approach in improving recommendation accuracy. Further ablation studies validate the effectiveness of our model design and benefits of the TMF.
Leveraging User-Generated Reviews for Recommender Systems with Dynamic Headers
Sep 11, 2024E-commerce platforms have a vast catalog of items to cater to their customers' shopping interests. Most of these platforms assist their customers in the shopping process by offering optimized recommendation carousels, designed to help customers quickly locate their desired items. Many models have been proposed in academic literature to generate and enhance the ranking and recall set of items in these carousels. Conventionally, the accompanying carousel title text (header) of these carousels remains static. In most instances, a generic text such as "Items similar to your current viewing" is utilized. Fixed variations such as the inclusion of specific attributes "Other items from a similar seller" or "Items from a similar brand" in addition to "frequently bought together" or "considered together" are observed as well. This work proposes a novel approach to customize the header generation process of these carousels. Our work leverages user-generated reviews that lay focus on specific attributes (aspects) of an item that were favorably perceived by users during their interaction with the given item. We extract these aspects from reviews and train a graph neural network-based model under the framework of a conditional ranking task. We refer to our innovative methodology as Dynamic Text Snippets (DTS) which generates multiple header texts for an anchor item and its recall set. Our approach demonstrates the potential of utilizing user-generated reviews and presents a unique paradigm for exploring increasingly context-aware recommendation systems.
Debiasing Machine Unlearning with Counterfactual Examples
Apr 24, 2024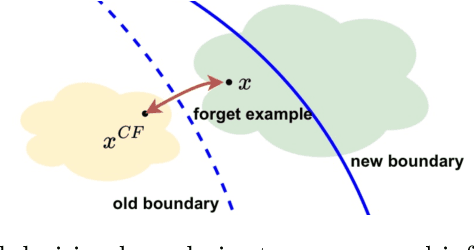

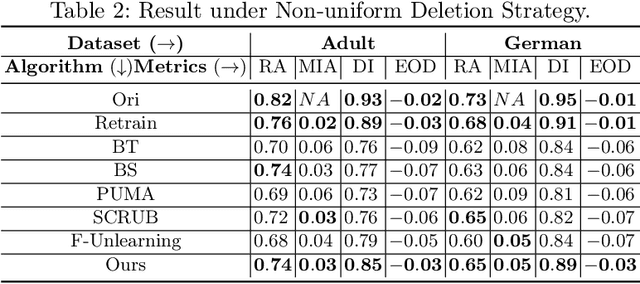
The right to be forgotten (RTBF) seeks to safeguard individuals from the enduring effects of their historical actions by implementing machine-learning techniques. These techniques facilitate the deletion of previously acquired knowledge without requiring extensive model retraining. However, they often overlook a critical issue: unlearning processes bias. This bias emerges from two main sources: (1) data-level bias, characterized by uneven data removal, and (2) algorithm-level bias, which leads to the contamination of the remaining dataset, thereby degrading model accuracy. In this work, we analyze the causal factors behind the unlearning process and mitigate biases at both data and algorithmic levels. Typically, we introduce an intervention-based approach, where knowledge to forget is erased with a debiased dataset. Besides, we guide the forgetting procedure by leveraging counterfactual examples, as they maintain semantic data consistency without hurting performance on the remaining dataset. Experimental results demonstrate that our method outperforms existing machine unlearning baselines on evaluation metrics.