 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndieFake Dataset: A Benchmark Dataset for Audio Deepfake Detection
Jun 23, 2025



Advancements in audio deepfake technology offers benefits like AI assistants, better accessibility for speech impairments, and enhanced entertainment. However, it also poses significant risks to security, privacy, and trust in digital communications. Detecting and mitigating these threats requires comprehensive datasets. Existing datasets lack diverse ethnic accents, making them inadequate for many real-world scenarios. Consequently, models trained on these datasets struggle to detect audio deepfakes in diverse linguistic and cultural contexts such as in South-Asian countries. Ironically, there is a stark lack of South-Asian speaker samples in the existing datasets despite constituting a quarter of the worlds population. This work introduces the IndieFake Dataset (IFD), featuring 27.17 hours of bonafide and deepfake audio from 50 English speaking Indian speakers. IFD offers balanced data distribution and includes speaker-level characterization, absent in datasets like ASVspoof21 (DF). We evaluated various baselines on IFD against existing ASVspoof21 (DF) and In-The-Wild (ITW) datasets. IFD outperforms ASVspoof21 (DF) and proves to be more challenging compared to benchmark ITW dataset. The dataset will be publicly available upon acceptance.
ZClip: Adaptive Spike Mitigation for LLM Pre-Training
Apr 03, 2025



Training large language models (LLMs) presents numerous challenges, including gradient instability and loss spikes. These phenomena can lead to catastrophic divergence, requiring costly checkpoint restoration and data batch skipping. Traditional gradient clipping techniques, such as constant or norm-based methods, fail to address these issues effectively due to their reliance on fixed thresholds or heuristics, leading to inefficient learning and requiring frequent manual intervention. In this work, we propose ZClip, an adaptive gradient clipping algorithm that dynamically adjusts the clipping threshold based on statistical properties of gradient norms over time. Unlike prior reactive strategies, ZClip proactively adapts to training dynamics without making any prior assumptions on the scale and the temporal evolution of gradient norms. At its core, it leverages z-score-based anomaly detection to identify and mitigate large gradient spikes, preventing malignant loss spikes while not interfering with convergence otherwise. Our code is available at: https://github.com/bluorion-com/ZClip.
A Refined Analysis of Massive Activations in LLMs
Mar 28, 2025



Motivated in part by their relevance for low-precision training and quantization, massive activations in large language models (LLMs) have recently emerged as a topic of interest. However, existing analyses are limited in scope, and generalizability across architectures is unclear. This paper helps address some of these gaps by conducting an analysis of massive activations across a broad range of LLMs, including both GLU-based and non-GLU-based architectures. Our findings challenge several prior assumptions, most importantly: (1) not all massive activations are detrimental, i.e. suppressing them does not lead to an explosion of perplexity or a collapse in downstream task performance; (2) proposed mitigation strategies such as Attention KV bias are model-specific and ineffective in certain cases. We consequently investigate novel hybrid mitigation strategies; in particular pairing Target Variance Rescaling (TVR) with Attention KV bias or Dynamic Tanh (DyT) successfully balances the mitigation of massive activations with preserved downstream model performance in the scenarios we investigated. Our code is available at: https://github.com/bluorion-com/refine_massive_activations.
Streamlining Video Analysis for Efficient Violence Detection
Nov 29, 2024This paper addresses the challenge of automated violence detection in video frames captured by surveillance cameras, specifically focusing on classifying scenes as "fight" or "non-fight." This task is critical for enhancing unmanned security systems, online content filtering, and related applications. We propose an approach using a 3D Convolutional Neural Network (3D CNN)-based model named X3D to tackle this problem. Our approach incorporates pre-processing steps such as tube extraction, volume cropping, and frame aggregation, combined with clustering techniques, to accurately localize and classify fight scenes. Extensive experimentation demonstrates the effectiveness of our method in distinguishing violent from non-violent events, providing valuable insights for advancing practical violence detection systems.
ProvocationProbe: Instigating Hate Speech Dataset from Twitter
Oct 25, 2024In the recent years online social media platforms has been flooded with hateful remarks such as racism, sexism, homophobia etc. As a result, there have been many measures taken by various social media platforms to mitigate the spread of hate-speech over the internet. One particular concept within the domain of hate speech is instigating hate, which involves provoking hatred against a particular community, race, colour, gender, religion or ethnicity. In this work, we introduce \textit{ProvocationProbe} - a dataset designed to explore what distinguishes instigating hate speech from general hate speech. For this study, we collected around twenty thousand tweets from Twitter, encompassing a total of nine global controversies. These controversies span various themes including racism, politics, and religion. In this paper, i) we present an annotated dataset after comprehensive examination of all the controversies, ii) we also highlight the difference between hate speech and instigating hate speech by identifying distinguishing features, such as targeted identity attacks and reasons for hate.
Leveraging User-Generated Reviews for Recommender Systems with Dynamic Headers
Sep 11, 2024E-commerce platforms have a vast catalog of items to cater to their customers' shopping interests. Most of these platforms assist their customers in the shopping process by offering optimized recommendation carousels, designed to help customers quickly locate their desired items. Many models have been proposed in academic literature to generate and enhance the ranking and recall set of items in these carousels. Conventionally, the accompanying carousel title text (header) of these carousels remains static. In most instances, a generic text such as "Items similar to your current viewing" is utilized. Fixed variations such as the inclusion of specific attributes "Other items from a similar seller" or "Items from a similar brand" in addition to "frequently bought together" or "considered together" are observed as well. This work proposes a novel approach to customize the header generation process of these carousels. Our work leverages user-generated reviews that lay focus on specific attributes (aspects) of an item that were favorably perceived by users during their interaction with the given item. We extract these aspects from reviews and train a graph neural network-based model under the framework of a conditional ranking task. We refer to our innovative methodology as Dynamic Text Snippets (DTS) which generates multiple header texts for an anchor item and its recall set. Our approach demonstrates the potential of utilizing user-generated reviews and presents a unique paradigm for exploring increasingly context-aware recommendation systems.
Komodo: A Linguistic Expedition into Indonesia's Regional Languages
Mar 19, 2024



The recent breakthroughs in Large Language Models (LLMs) have mostly focused on languages with easily available and sufficient resources, such as English. However, there remains a significant gap for languages that lack sufficient linguistic resources in the public domain. Our work introduces Komodo-7B, 7-billion-parameter Large Language Models designed to address this gap by seamlessly operating across Indonesian, English, and 11 regional languages in Indonesia. Komodo-7B is a family of LLMs that consist of Komodo-7B-Base and Komodo-7B-Instruct. Komodo-7B-Instruct stands out by achieving state-of-the-art performance in various tasks and languages, outperforming the benchmarks set by OpenAI's GPT-3.5, Cohere's Aya-101, Llama-2-Chat-13B, Mixtral-8x7B-Instruct-v0.1, Gemma-7B-it , and many more. This model not only demonstrates superior performance in both language-specific and overall assessments but also highlights its capability to excel in linguistic diversity. Our commitment to advancing language models extends beyond well-resourced languages, aiming to bridge the gap for those with limited linguistic assets. Additionally, Komodo-7B-Instruct's better cross-language understanding contributes to addressing educational disparities in Indonesia, offering direct translations from English to 11 regional languages, a significant improvement compared to existing language translation services. Komodo-7B represents a crucial step towards inclusivity and effectiveness in language models, providing to the linguistic needs of diverse communities.
[Re] Double Sampling Randomized Smoothing
Jun 27, 2023This paper is a contribution to the reproducibility challenge in the field of machine learning, specifically addressing the issue of certifying the robustness of neural networks (NNs) against adversarial perturbations. The proposed Double Sampling Randomized Smoothing (DSRS) framework overcomes the limitations of existing methods by using an additional smoothing distribution to improve the robustness certification. The paper provides a clear manifestation of DSRS for a generalized family of Gaussian smoothing and a computationally efficient method for implementation. The experiments on MNIST and CIFAR-10 demonstrate the effectiveness of DSRS, consistently certifying larger robust radii compared to other methods. Also various ablations studies are conducted to further analyze the hyperparameters and effect of adversarial training methods on the certified radius by the proposed framework.
BED: Bi-Encoder-Based Detectors for Out-of-Distribution Detection
Jun 15, 2023This paper introduces a novel method leveraging bi-encoder-based detectors along with a comprehensive study comparing different out-of-distribution (OOD) detection methods in NLP using different feature extractors. The feature extraction stage employs popular methods such as Universal Sentence Encoder (USE), BERT, MPNET, and GLOVE to extract informative representations from textual data. The evaluation is conducted on several datasets, including CLINC150, ROSTD-Coarse, SNIPS, and YELLOW. Performance is assessed using metrics such as F1-Score, MCC, FPR@90, FPR@95, AUPR, an AUROC. The experimental results demonstrate that the proposed bi-encoder-based detectors outperform other methods, both those that require OOD labels in training and those that do not, across all datasets, showing great potential for OOD detection in NLP. The simplicity of the training process and the superior detection performance make them applicable to real-world scenarios. The presented methods and benchmarking metrics serve as a valuable resource for future research in OOD detection, enabling further advancements in this field. The code and implementation details can be found on our GitHub repository: https://github.com/yellowmessenger/ood-detection.
MTCNET: Multi-task Learning Paradigm for Crowd Count Estimation
Aug 23, 2019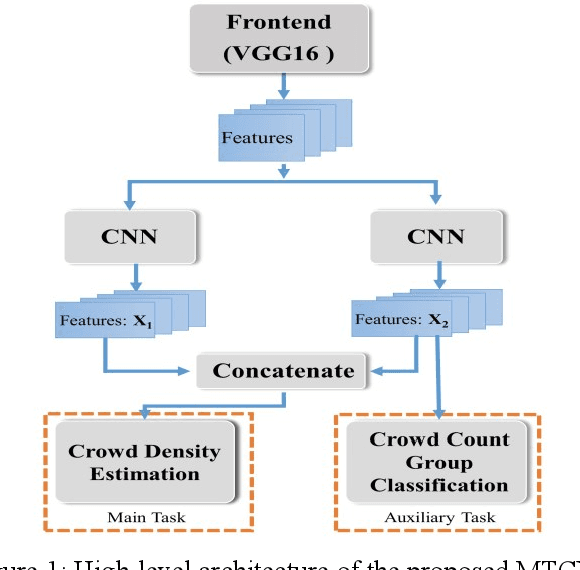
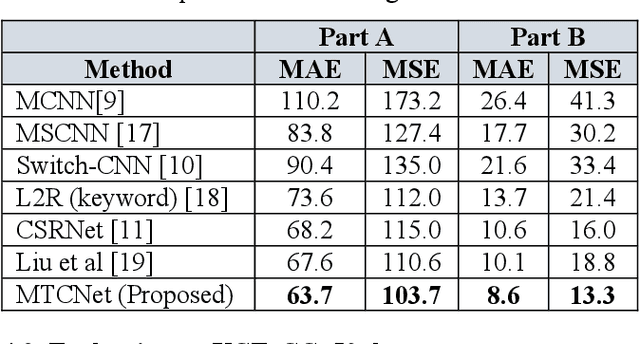

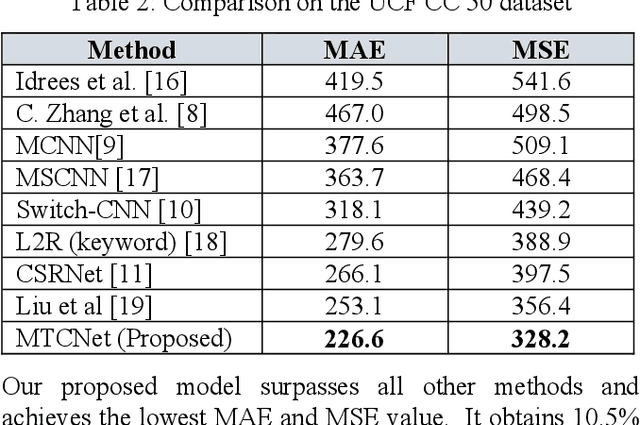
We propose a Multi-Task Learning (MTL) paradigm based deep neural network architecture, called MTCNet (Multi-Task Crowd Network) for crowd density and count estimation. Crowd count estimation is challenging due to the non-uniform scale variations and the arbitrary perspective of an individual image. The proposed model has two related tasks, with Crowd Density Estimation as the main task and Crowd-Count Group Classification as the auxiliary task. The auxiliary task helps in capturing the relevant scale-related information to improve the performance of the main task. The main task model comprises two blocks: VGG-16 front-end for feature extraction and a dilated Convolutional Neural Network for density map generation. The auxiliary task model shares the same front-end as the main task, followed by a CNN classifier. Our proposed network achieves 5.8% and 14.9% lower Mean Absolute Error (MAE) than the state-of-the-art methods on ShanghaiTech dataset without using any data augmentation. Our model also outperforms with 10.5% lower MAE on UCF_CC_50 dataset.